


人人都想拥有Jarvis,它可能先是个“移动硬盘”
“我们没想到端侧AI会火得这么快。” 3月末,Tiiny AI副总裁兼商业化负责人Eco Lee在复盘其Kickstarter众筹项目时这样感慨。
这个名为Tiiny AI Pocket Lab的“小盒子”,在3月中旬登陆Kickstarter,起售价1399美元。令人惊讶的是,上线仅5小时,其众筹金额便突破了100万美元大关。上一次在该平台创造如此速度的,还要追溯到2022年的3D打印品牌拓竹。截至发稿,该项目已筹集超过295万美元,获得了超过两千名支持者。
一个有趣的现象是,在AI PC市场尚未完全成熟之际,这个外接式的AI算力盒子先火了。其背后的核心逻辑在于,它为搭建本地AI助手的需求,提供了一个极其简单直接的解决方案。
当用户觉得单独购置一台AI PC成本过高,自行部署大模型过于繁琐,依赖云端服务又担心隐私和持续成本时,Tiiny AI Pocket Lab出现了。它不负责日常办公,不处理娱乐任务,只专注于一件事:成为你专属的、离线的AI算力源。
这就像是当电脑或手机存储空间告急时,我们选择加购一块移动硬盘。Tiiny AI这款产品不做通用计算,只专注于100B级别大模型的本地推理,旨在一次性解决用户的离线隐私保护、一键部署难度和本地算力需求这三大痛点。不过,它究竟代表着一个全新的硬件品类,还是特定技术过渡期的“补丁”产品,现在下结论还为时尚早。
想拥有Jarvis,却找不到合适的硬件
众筹的火爆为Tiiny AI带来了大量关注,Eco Lee几乎每周都能收到数十家投资机构的邀约。
据了解,Tiiny AI的国内主体为“本智激活”,孵化自上海交通大学并行与分布式系统研究所(IPADS)。团队在2024年于GitHub上开源了推理加速引擎项目PowerInfer,并迅速获得了超过9100个star。Tiiny AI硬件项目正是从这个明星软件项目中孵化而来。
为什么Tiiny AI Pocket Lab能在这个时间点引爆市场?这不得不提及近期的“AI助手热”。无论是OpenClaw等开源项目的流行,还是Ollama下载量的暴增,都表明了一个强烈的市场需求:在用户渴望拥有的“Jarvis”与市面上能买到的合适硬件之间,存在一条明显的市场缝隙。
许多专业用户和极客都在尝试搭建自己的AI助手,但现有方案各有不足:
- 云端API:虽然方便,但长期使用成本不菲,且涉及敏感数据的隐私焦虑始终存在。
- AI PC:并非专为大模型推理设计。在高性能电脑上同时运行大模型和日常任务,会导致系统资源被严重占用,体验卡顿。
- 开发板方案:如树莓派算力严重不足;而像NVIDIA Jetson AGX Orin这类高性能边缘计算设备,价格又过于高昂。
因此,一个具备足够算力与内存、能够一键部署、并且拥有消费级性价比的“Agent Box”,正好切中了当下核心用户的急切需求。Tiiny AI选择了做减法:Pocket Lab不运行传统操作系统,系统完全为AI推理服务。同时,它在算力上做加法,其标称的190TOPS(INT8)峰值算力,已达到了主流桌面级专业AI显卡的水平。
在易用性上,Tiiny宣称其设备可以一键下载并运行100B参数以下的主流开源模型。用户只需通过USB-C线将设备连接到电脑(无论Mac、Windows还是Linux),下载客户端即可使用。
换句话说,它并不与AI PC或Mac mini直接竞争,而是瞄准了一个产品真空地带——一个专为本地人工智能推理设计的“外接算力硬盘”。
Tiiny AI如何用软件弥补硬件?
Tiiny AI产品的聪明之处在于,它将复杂的AI算力硬件包装成了易于理解的消费级产品:“能跑100B大模型,即插即用”。这极大地降低了用户的决策门槛。
支撑这一切的,是团队对技术路线的核心思考:到底多大能力的模型才能真正满足核心用户场景?团队认为,10B以下模型能力有限;70B级别模型已具备较强的逻辑推理和工具调用能力;而300B以上模型目前仍需依赖云端。
因此,Tiiny将目标锁定在“让100B级别模型在本地流畅运行”。选择100B作为一个关键节点,部分原因是行业普遍认为,达到GPT-4o(约120B参数)这个级别,AI才开始真正具备解决复杂实际问题的能力。
但用消费级硬件运行如此庞大的模型是个巨大挑战。Tiiny的解法并非单纯堆砌昂贵硬件,而是依赖于其核心的PowerInfer技术——一个面向端侧异构算力的推理加速引擎。
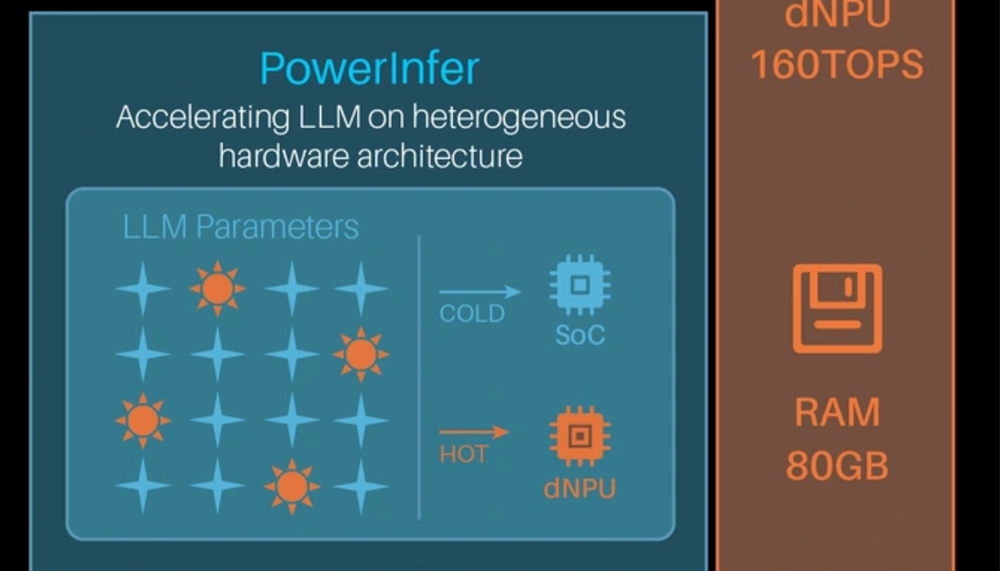
简单来说,PowerInfer利用了[大模型推理中一个关键特性:并非所有参数都会被同时激活。它将参数分为“热激活参数”(每次交互都调用的核心参数,约占20%)和“冷激活参数”(仅在特定领域问题中被激活)。基于此,Tiiny AI的硬件采用了异构计算架构:
- SoC(系统级芯片):包含Arm CPU和一个30TOPS的NPU,用于处理“冷激活参数”。
- dNPU(专用神经处理单元):一块专门为Transformer架构设计的ASIC芯片,提供160TOPS的算力,专门处理“热激活参数”。
根据虎嗅获得的一组实测数据,在这套方案下:
- 运行120B模型时,“思考”(prefill)速度可达300 tokens/s,“回答”(decoding)速度约为20 tokens/s。
- 运行35B模型时,“思考”速度约2000 tokens/s,“回答”速度可达45 tokens/s。
作为参照,人类的平均阅读速度约为8-12 tokens/s。从参数上看,这套软件调度方案的效果,已经能够媲美高端AI工作站的运行效率。其核心逻辑在于:聪明的软件设计,能够最大限度地弥补硬件资源的不足。
面临的质疑与团队的回应
在亮眼的参数背后,行业观察者也提出了一些技术性质疑:
- 关于模型参数:Tiiny宣传的“120B大模型”实为MoE(混合专家)架构,每个token实际激活的参数约为51亿。这与传统密集模型“运行1200亿参数”在技术含义上存在区别。
- 关于算力宣传:190TOPS的算力可能是将不同计算单元(NPU、dNPU)的理论峰值相加得出,而不同架构的算力直接累加是行业常见的营销表述,但并非严格的性能指标。
- 关于内存与带宽:80GB内存分布在SoC和dNPU两颗芯片上,质疑者担心跨PCIe总线传输数据会成为性能瓶颈。

对此,Tiiny AI在Kickstarter上给出了技术解释:针对PCIe带宽瓶颈的担忧,其指出由于PowerInfer的冷热激活特性,需要跨芯片传输的数据量极小。以GPT-OSS-120B为例,每次推理需传输的数据仅约5.625 KB,远低于PCIe Gen4 x4链路约8 GB/s的带宽上限,因此传输延迟微乎其微,并非性能瓶颈。
此外,关于产品交付时间(预计8月),Eco Lee解释称,产品从研发到众筹已历时13个月,众筹结束后可迅速进入量产。目前正在进行的FCC、CE等全球市场合规认证,预计在6月底前完成。生产制造将由全球头部PC制造商LCFC位于越南的工厂负责,以保障品控和交付质量。
小结:个人AI工作站的雏形

无论如何,Tiiny AI Pocket Lab的众筹成功,证实了市场对个人专属、离线AI工作站的真实需求。它清晰地描绘出一个用户场景:本地AI首先不会成为大众消费品,而是会率先成为金融、法律、科研等领域专业用户,以及高频极客玩家的生产力工具。
“Agent Box”这类产品或许只是技术发展窗口期的过渡形态,但它确实精准地切中了高敏感数据用户和高频AI使用者最迫切的痛点,成为了今年AI硬件领域一个值得关注的趋势。对于这类软硬件结合的新物种,其最终体验和长期价值,还需要等待实际产品交付后的市场检验。欢迎开发者们在云栈社区继续探讨本地AI推理的技术前景与产品形态。
 发表于 2026-4-5 01:17:49
|
查看: 125|
回复: 0
发表于 2026-4-5 01:17:49
|
查看: 125|
回复: 0
