在CUDA异构计算的实践中,CPU与GPU之间的内存隔离,常常成为制约程序性能的关键瓶颈。许多开发者都曾面临这样的困境:GPU的算力明明充足,但数据在主机与设备内存之间反复拷贝,导致PCIe总线不堪重负,最终让程序运行变得迟缓。这种“算力过剩但数据断流”的矛盾,根源就在于内存壁垒。而CUDA提供的内存映射机制,正是破解这一难题的核心钥匙。它通过虚拟地址映射等技术,允许GPU直接访问主机的页锁定内存,也能让主机直连设备的全局内存,从根本上减少冗余的数据拷贝,释放宝贵的PCIe带宽。
本文将深入剖析这一机制的底层原理,详细解析页锁定内存与零拷贝内存的工作机制,拆解地址映射与数据同步的关键步骤,并梳理核心的API调用方法。无论你是希望突破性能瓶颈的开发者,还是希望深入理解CUDA原理的学习者,都能在这里找到打破内存壁垒的有效技术路径。
一、初识CUDA
1.1 什么是CUDA?
在计算能力发展的道路上,CUDA的出现标志着一个重要的转折点,它为CPU与GPU的协同计算开辟了全新的方向。CUDA,全称为Compute Unified Device Architecture(统一计算设备架构),是NVIDIA于2006年推出的一套并行计算平台和编程模型。它就像一座桥梁,一端连接着CPU的逻辑控制优势,另一端则连接着GPU强大的并行计算能力,让原本“各自为战”的二者能够紧密协作,共同解决复杂的计算难题。
CUDA彻底改变了传统的计算模式。在此之前,GPU主要专注于图形渲染任务,其强大的计算能力被限制在特定领域。CUDA则赋予了GPU更广阔的舞台,它允许开发者使用类似C/C++等熟悉的编程语言,编写能够在GPU上并行执行的代码,从而将GPU从纯粹的图形处理器,转变为通用的并行计算引擎,在科学计算、深度学习等领域大放异彩。
以深度学习为例,训练一个复杂的神经网络模型需要处理海量数据和进行极其复杂的矩阵运算。如果仅依赖CPU,漫长的训练周期将是难以承受的。而借助CUDA,GPU可以充分发挥其成百上千个计算核心的并行优势,将庞大的计算任务分解并同时处理,从而将训练时间从数周缩短至数天甚至数小时,极大地推动了AI技术的发展与应用。
1.2 CPU与GPU的区别
在计算机系统中,CPU与GPU虽然都承担计算任务,但在内存管理上却如同两个“独立王国”。CPU内存,通常被称为主内存或系统内存,是计算机的通用存储区域,负责存储操作系统、应用程序及各类数据。它像一个综合性的大仓库,访问灵活,通用性强。
GPU内存,即显存,则是专为GPU设计的高速存储区,主要用于存储图形数据或计算任务所需的数据。它更像一个为GPU计算核心服务的专用高速缓存,针对高带宽、低延迟的并行数据访问进行了深度优化。
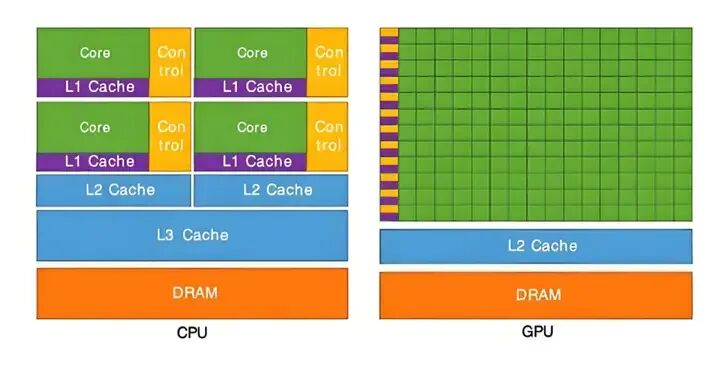
然而,这两个内存区域之间存在物理界限。它们位于不同的硬件上,通过PCIe总线等接口连接。数据在两者间传输需要经过复杂的路径,过程耗时且占用总线带宽。此外,两者的管理方式也存在差异:CPU内存管理注重通用性,而GPU内存管理则优先保障并行计算的高吞吐需求,这种差异进一步增加了数据交互的复杂性。
1.3 内存壁垒带来的困境
内存壁垒的存在,严重制约了计算效率和资源利用率。在深度学习模型训练中,海量的训练数据和模型参数通常存放在CPU内存,而计算则由GPU执行。由于内存壁垒,数据传输速度往往跟不上GPU的计算速度,导致GPU频繁处于“饥饿”的等待状态,其强大的算力无法被充分利用,造成显著的资源浪费。
在图形渲染、高实时性的游戏或VR/AR应用中,内存壁垒带来的数据传输延迟可能导致画面卡顿、掉帧,严重影响用户体验。此外,频繁的数据拷贝本身会消耗额外的能量,而因效率低下导致的更长的任务运行时间,也进一步增加了系统整体能耗。
二、CUDA映射机制核心原理
2.1 统一虚拟寻址(UVA)
统一虚拟寻址(UVA, Unified Virtual Addressing)是打破CPU与GPU内存壁垒的关键技术。它创建了一个统一的虚拟地址空间,允许CPU和GPU使用相同的指针地址来访问内存,无论该内存在物理上位于主机端还是设备端。
在传统模式下,CPU和GPU拥有各自独立的地址空间,互相访问需要进行复杂的地址转换和显式拷贝。UVA的出现简化了这一过程。例如,在深度学习训练中,通过UVA,GPU可以直接读取存放在CPU内存中的模型参数,无需事先进行显式的内存拷贝,从而减少了数据传输开销,提升了效率。
以下是一个展示UVA用法的简化代码示例:
#include <iostream>
#include <cuda_runtime.h>
// CUDA核函数:将数组每个元素乘以2
__global__ void multiplyByTwo(float* data, int n) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < n) {
data[idx] *= 2.0f;
}
}
int main() {
const int N = 1024;
size_t size = N * sizeof(float);
// 1. 使用cudaMallocManaged分配统一内存(UVA内存)
float* uva_data;
cudaMallocManaged(&uva_data, size);
// 2. CPU初始化数据
for (int i = 0; i < N; ++i) {
uva_data[i] = static_cast<float>(i);
}
// 3. GPU直接访问UVA内存进行计算
dim3 blockSize(256);
dim3 gridSize((N + blockSize.x - 1) / blockSize.x);
multiplyByTwo<<<gridSize, blockSize>>>(uva_data, N);
// 4. 同步并等待GPU完成
cudaDeviceSynchronize();
// 5. CPU可直接读取GPU计算后的结果,无需显式拷贝
std::cout << "Result at index 10: " << uva_data[10] << std::endl; // 应为 20.0
// 6. 释放统一内存
cudaFree(uva_data);
return 0;
}
2.2 页锁定内存(Pinned Memory)
页锁定内存(Pinned Memory),也称为固定内存,是CUDA映射机制中的另一块基石。普通的主机内存由操作系统进行分页管理,在内存紧张时可能被换出到磁盘,这会导致访问延迟。而页锁定内存则被“锁定”在物理内存中,不会被操作系统换出,从而确保了快速、稳定的访问。
使用页锁定内存可以显著提升主机与设备间数据拷贝的带宽,尤其是在进行异步传输时。通过cudaMallocHost或cudaHostAlloc(不带映射标志)分配的内存即为页锁定内存。
// 分配页锁定内存
float* h_pinnedData = nullptr;
cudaError_t err = cudaMallocHost((void**)&h_pinnedData, size);
if (err != cudaSuccess) {
// 错误处理
}
// ... 使用h_pinnedData进行数据传输
// 释放页锁定内存必须使用cudaFreeHost
cudaFreeHost(h_pinnedData);
2.3 异步传输与流(Streams)
异步传输和流(Streams)是实现计算与数据传输重叠、从而隐藏延迟的关键技术。异步传输允许数据拷贝操作在后台执行,CPU无需等待其完成即可继续执行后续指令。
流则是一系列异步操作(如内存拷贝、内核启动)的序列。不同流中的操作可以并发执行,这为实现计算与通信的重叠提供了可能。例如,可以将数据从主机拷贝到设备(流A)与在设备上执行另一个计算内核(流B)同时进行。
cudaStream_t stream1, stream2;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
// 在stream1中异步拷贝数据
cudaMemcpyAsync(d_a, h_a, size, cudaMemcpyHostToDevice, stream1);
// 在stream2中启动一个内核,可能与stream1的拷贝重叠执行
kernel2<<<grid, block, 0, stream2>>>(d_b);
// 等待特定流完成
cudaStreamSynchronize(stream1);
cudaStreamDestroy(stream1);
cudaStreamDestroy(stream2);
2.4 零拷贝内存(Zero-Copy Memory)
零拷贝内存是CUDA映射机制的一项突破,它允许GPU内核直接访问CPU的页锁定内存,省去了显式的数据拷贝步骤。这是通过将主机端的页锁定内存映射到设备的地址空间来实现的。
零拷贝内存适用于GPU内核需要频繁读写少量数据,或数据量过大无法完全放入设备内存的场景。它简化了编程模型,但需要注意,由于访问需要通过PCIe总线,其延迟高于设备内存,因此更适合对带宽不敏感或访问不频繁的操作。
// 1. 分配零拷贝内存(映射式的页锁定内存)
float* hostData = nullptr;
cudaHostAlloc((void**)&hostData, size, cudaHostAllocMapped);
// 2. 获取对应的设备指针
float* devicePtr = nullptr;
cudaHostGetDevicePointer((void**)&devicePtr, hostData, 0);
// 3. GPU核函数可以直接使用devicePtr访问hostData指向的主机内存
kernel<<<grid, block>>>(devicePtr, N);
// 4. 释放时必须使用cudaFreeHost
cudaFreeHost(hostData);
三、零拷贝(Zero-Copy)技术深度解析
3.1 虚拟地址映射的实现路径
基础映射:通过cudaHostRegister()函数,可以将已由malloc等分配的主机内存注册为可映射到设备空间的区域。这适用于需要复用现有内存缓冲区的场景。
双向映射(UVA):在支持UVA的系统上(计算能力2.0及以上),设置cudaSetDeviceFlags(cudaDeviceMapHost)后,可以在GPU核函数中直接使用主机指针(需由cudaHostAlloc分配)。这消除了手动获取设备指针的步骤。
写合并优化:针对主机写入、设备读取的单向数据流,使用cudaHostAllocWriteCombined标志分配内存。这种内存禁用CPU缓存,能提升主机到设备的传输带宽,但CPU读取它会非常慢。
3.2 数据同步的精准控制
流同步:利用CUDA流对异步操作进行细粒度排序和控制,确保在数据就绪后才启动计算内核。
// 在同一个流内,操作保证顺序执行
cudaMemcpyAsync(d_a, h_a, size, cudaMemcpyHostToDevice, stream1);
myKernel<<<grid, block, 0, stream1>>>(d_a); // 保证拷贝完成后才执行
cudaMemcpyAsync(h_result, d_a, size, cudaMemcpyDeviceToHost, stream1);
事件(Event):用于在流中标记一个点,并查询该点之前的操作是否已完成,实现跨流的精细同步。
cudaEvent_t event;
cudaEventCreate(&event);
cudaMemcpyAsync(d_a, h_a, size, cudaMemcpyHostToDevice, streamA);
cudaEventRecord(event, streamA); // 在streamA的拷贝操作后记录事件
// streamB需要等待streamA的拷贝完成
cudaStreamWaitEvent(streamB, event, 0);
kernelOnStreamB<<<grid, block, 0, streamB>>>(d_a);
3.3 从内存分配到资源释放
分配标志选择:
cudaHostAllocDefault: 分配普通页锁定内存。cudaHostAllocMapped: 分配可用于零拷贝的映射内存。cudaHostAllocWriteCombined: 分配写合并内存,优化主机到设备传输。cudaHostAllocPortable: 分配的内存可被多个CUDA设备上下文使用。
地址转换:在非UVA环境或使用cudaHostRegister时,必须通过cudaHostGetDevicePointer()获取设备端可用的指针。
资源释放:至关重要。由cudaHostAlloc或cudaHostRegister分配/注册的内存,必须使用cudaFreeHost或cudaHostUnregister来释放/注销,绝不能使用普通的free(),否则会导致未定义行为或内存泄漏。
四、实践指南:从性能诊断到方案落地
4.1 瓶颈定位的工具链组合
- Nsight Systems / 旧版 nvprof:进行时间线分析,查看内核执行、内存拷贝、流并发等情况。重点关注
cudaMemcpy系列调用的耗时占比。如果数据传输时间占总运行时间的比例过高(例如超过30%),就是引入内存映射和异步操作优化的强烈信号。
- Nsight Compute / 旧版 nvvp:进行更细致的核函数性能分析,查看内存带宽利用率、缓存命中率等指标。可以辅助判断核函数本身是计算受限还是内存访问受限。
4.2 场景化优化方案设计
- 高频小数据交互(如实时推理、信号处理):优先考虑零拷贝内存。将主机端产生的小批量数据放入零拷贝内存,GPU直接处理,避免拷贝开销,最大化降低端到端延迟。
- 大数据集处理(数据量 > 显存):采用零拷贝内存池 + 分块处理策略。将大数据集保留在主机零拷贝内存中,GPU核函数分块读取和处理,实现“外核计算”,有效突破显存容量限制。
- 可预知的规则数据传输(如图像处理管道):采用页锁定内存 + 多流异步。使用页锁定内存保证高拷贝带宽,并创建多个CUDA流。在一个流执行当前数据块的计算时,另一个流已经开始传输下一个数据块,实现计算与通信的完美重叠。
- 多GPU协同计算:使用
cudaHostAllocPortable分配可移植的页锁定内存,结合GPUDirect P2P(Peer-to-Peer)技术,实现GPU间直接通过PCIe交换数据,甚至通过RDMA绕过主机内存,极大提升多GPU间的通信效率。
4.3 核心API总结与示例
以下是一个综合运用统一内存和异步流来加速向量加法的完整示例:
#include <iostream>
#include <cuda_runtime.h>
__global__ void vectorAdd(const float* A, const float* B, float* C, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
C[idx] = A[idx] + B[idx];
}
}
int main() {
const int N = 1000000;
const size_t size = N * sizeof(float);
// 1. 分配统一内存
float *A, *B, *C;
cudaMallocManaged(&A, size);
cudaMallocManaged(&B, size);
cudaMallocManaged(&C, size);
// 初始化
for (int i = 0; i < N; i++) {
A[i] = i;
B[i] = i * 2;
}
// 2. 创建CUDA流
cudaStream_t stream;
cudaStreamCreate(&stream);
// 3. 可选:预取数据到GPU以获得最佳首次访问性能
int deviceId;
cudaGetDevice(&deviceId);
cudaMemPrefetchAsync(A, size, deviceId, stream);
cudaMemPrefetchAsync(B, size, deviceId, stream);
cudaMemPrefetchAsync(C, size, deviceId, stream);
cudaStreamSynchronize(stream);
// 4. 启动核函数
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
vectorAdd<<<blocksPerGrid, threadsPerBlock, 0, stream>>>(A, B, C, N);
// 5. 同步流,确保计算完成
cudaStreamSynchronize(stream);
// 6. 验证结果(检查前几个)
bool correct = true;
for (int i = 0; i < 10; i++) {
if (fabs(C[i] - (A[i] + B[i])) > 1e-5) {
correct = false;
break;
}
}
std::cout << "Test " << (correct ? "PASSED" : "FAILED") << std::endl;
// 7. 清理
cudaFree(A);
cudaFree(B);
cudaFree(C);
cudaStreamDestroy(stream);
return 0;
}
编译命令:nvcc -o vector_add vector_add.cu -std=c++11
这个示例综合展示了:
- 统一虚拟寻址:使用
cudaMallocManaged。
- 页锁定内存特性:托管内存自动具备页锁定属性。
- 异步预取:使用
cudaMemPrefetchAsync优化数据位置。
- 流管理:使用
cudaStream组织异步操作。
通过理解并灵活运用CUDA内存映射机制的各项技术,开发者可以显著优化异构计算程序的性能,真正释放GPU的澎湃算力。
 发表于 2025-12-15 01:41:35
|
查看: 245|
回复: 0
发表于 2025-12-15 01:41:35
|
查看: 245|
回复: 0
