在大模型规模不断扩张、算力与数据竞争日趋激烈的背景下,RockAI创始人刘凡平提出了一个不同于主流共识的观点:人工智能发展的下一个台阶,关键在于突破Transformer与反向传播算法这“两座大山”。
未来的智能,核心不在于模型“更大”,而在于让模型“活起来”。其本质是让模型摆脱静态函数的限制,使终端设备具备原生记忆、自主学习与持续进化的能力。这意味着AI的发展方向将从云端集中式的算力竞争,转向让每一台设备、每一个个体都能参与学习和生成知识的新范式。
在MEET2026智能未来大会上,刘凡平将这一转折点称为 硬件觉醒:当模型在设备端侧能像大脑一样稀疏激活、实时形成记忆,并在物理世界中不断更新自身时,设备便不再是工具,而是“活”的智能体。无数这样的智能体在现实世界中学习与协作,将孕育出真正能够产生知识的群体智能。

核心观点:为智能付费,而非为Token付费
当前,随着智能体(Agent)的广泛应用,Token消耗量急剧增长,其本质是用户在为Token付费。刘凡平指出,为Token付费是一件很愚蠢的事情。我们追求的是智能,因此付费的对象应该是智能本身,而非生成智能过程中产生的冗余信息量。
重新定义端侧模型:自主学习和原生记忆
硬件生态正在变化,AI能力正从云端走向终端。让AI属于每一个人,关键在于发展端侧智能。端侧不仅离用户更近,而且数据天然存在于设备周围。
然而,端侧模型并不是云端大模型的小参数版本。RockAI对端侧大模型有两个关键定义:自主学习和原生记忆。这恰恰是当前主流的Transformer架构模型在端侧难以实现的特性。
Transformer架构取得了巨大成功,但也使其陷入了一种“死亡螺旋”:为了提升性能,只能不断堆叠算力与数据,导致成本急剧攀升。刘凡平认为,对Scaling Law(缩放定律)的盲目信仰在当前看来是错误的。问题的核心不在于模型不够大,而在于思考方向有误。
当前的大模型是一个静态函数,而人的大脑是一个动态函数,时刻都在建立新的神经连接,这才是记忆与智能的基础。另一个误区是“参数越多越智能”,这在Transformer架构下成立,但若跳出该架构则不然。
同时,业界追逐的“长上下文”能力,在刘凡平看来并非真正的记忆。真正的记忆应该像人大脑的海马体,能够对信息进行加工、压缩和参数化存储。长上下文只是一种退而求其次的临时方案,因为部署后的Transformer模型是静态的,只能通过延长上下文来模拟记忆。
训练与推理同步:实现自主进化
未来的智能硬件必须拥有原生记忆和自主学习能力。其中,自主学习一定要走向物理世界。自主学习带来的最大好处是模型不会在部署时就“死亡”。目前的模型参数固定,部署即定型。而具备自主学习能力的模型可以实现训练和推理同步进行,在推理的同时不断调整自身参数,成为一个持续进化的“活”的系统。
当前许多方案,如知识外挂(RAG),都是针对静态模型缺陷的临时补丁。刘凡平强调,人工智能要迈向更高台阶,必须突破两座大山:第一是Transformer架构,第二是反向传播算法。
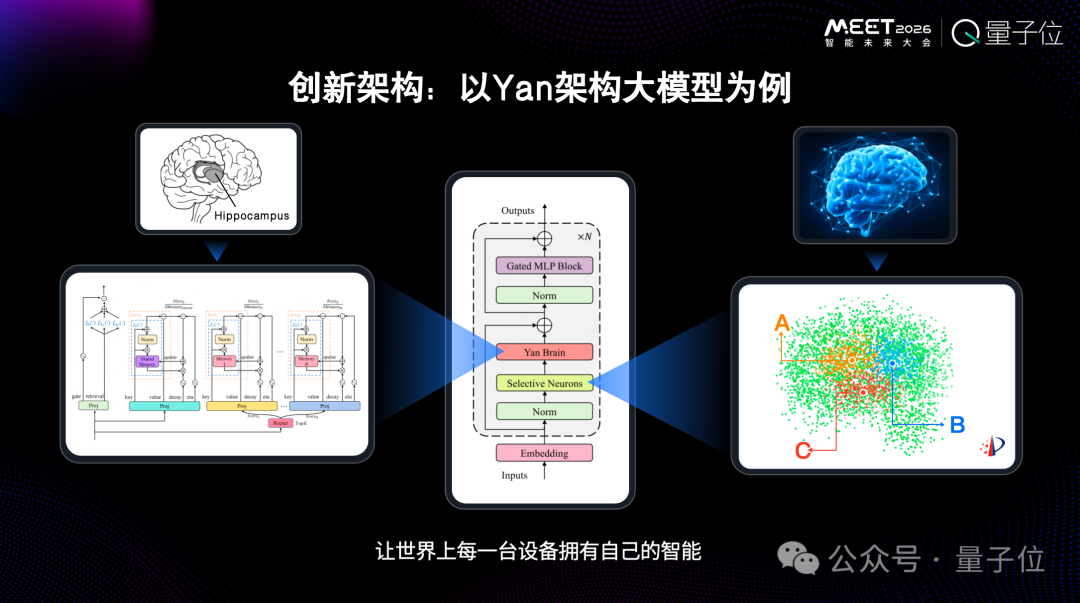
架构革新:Yan模型与稀疏激活
为了让模型能够进化,架构必须改变。以RockAI自主研发的Yan架构模型为例,它实现了整个模型的极端稀疏化,其激活机制比MoE(混合专家模型)更为稀疏,模仿了人脑高效节能的运行机制。
此外,模型中专门加入了记忆模块。在推理过程中,随着与用户的交互,记忆模块的参数会发生改变,从而实现真正的、个性化的记忆。这种架构使得模型无需依赖云端GPU,在手机、CPU等端侧设备上也能直接高效运行,为云原生与边缘计算场景提供了新的可能性。
例如,一个搭载了该模型的机器狗可以从零开始,在现场学习中掌握新技能。这为具身智能的发展提供了新思路:未来的家庭服务机器人不需要在出厂时就知晓一切,它可以通过在用户家中的自主学习来适应个性化环境。
智能重新定义硬件价值
原生记忆和自主学习带来的变革,远不止于“Token免费”。更深层次的影响在于,智能会重新定义硬件的价值。未来的硬件不再是冰冷的功能集合,而是能够与用户共同成长、创造情感连接的伙伴。其价值在购买时最小,并随着共同“经历”而不断增长。
迈向通用人工智能的最佳路径:群体智能
当每一台设备都拥有原生智能并能向物理世界学习时,群体智能便会涌现。这类似于人类社会:个体并非全能,但通过擅长领域的协作,能够产生全新的知识。
刘凡平指出,知识包含“产生”和“传播”两个环节。当前基于Transformer架构的大模型主要擅长知识的传播与整合,但其本身并不产生原生知识。真正的智能涌现应来自于每个能够自主学习和进化的个体,个体间通过协作产生新知识,再传播开来。因此,群体智能才是迈向通用人工智能(AGI)的更佳路径,而非创造一个全知全能的“云端之神”。
 发表于 2025-12-15 06:05:16
|
查看: 220|
回复: 0
发表于 2025-12-15 06:05:16
|
查看: 220|
回复: 0
