近日,DeepSeek-AI团队正式发布了 DeepSeek-OCR 2,并提出了全新的“视觉因果流”概念。这一设计旨在模拟人类阅读文档时动态、有逻辑的视线扫描模式,让模型能够根据图像内容的语义,智能地重排“阅读顺序”。基于这一新范式,DeepSeek-OCR 2在关键文档解析基准上取得了 91.09% 的SOTA综合性能,阅读顺序错误率大幅降低,在相似的视觉Token预算下,效果超越了Gemini 3 Pro。目前,其代码与模型权重均已开源。
当你阅读一篇论文或浏览一张海报时,你的视线是如何移动的?大概率不是像机器扫描仪那样,严格地从左上角到右下角逐行扫过。相反,你会根据标题、图表、段落等逻辑结构,进行一种灵活、有重点的跳跃式注视。每一次“看”哪里,都基于前一刻的理解,这是一个遵循内在因果逻辑的序列过程。
然而,传统的视觉语言模型在处理图像时,往往违背了这种人类认知机制。它们通常将图像分割成块(patch),然后展平成一维序列,并赋予固定的位置编码。这种“光栅扫描”顺序引入了一种不合理的归纳偏见,尤其在处理布局复杂的文档、表格或公式时,会严重影响模型对内容逻辑关系的理解。
为了从根本上解决这个问题,DeepSeek-OCR 2的核心是提出了一个全新的视觉编码器——DeepEncoder V2。这项研究探索了一个引人深思的范式:能否通过两个级联的一维因果推理结构,来高效地实现二维图像的理解?这或许是指向真正“2D推理”的一条新路径。
核心革新:从CLIP到LLM,引入“视觉因果流”
DeepSeek-OCR 2的架构升级,核心在于其视觉编码器DeepEncoder V2的设计。相较于前代使用CLIP作为视觉知识压缩模块,V2版本做出了一个大胆的替换:采用了一个紧凑的LLM风格架构(基于Qwen2 500M参数)来担任视觉编码器的角色。

这一改变带来了最关键的特性:视觉因果流。通过定制化的注意力掩码,DeepEncoder V2实现了“双轨并行”的信息处理:
- 原始视觉Token:采用双向注意力,允许每个图像块看到全局上下文信息,保留了类似ViT的全图感知能力。
- 可学习查询:引入了一组与视觉Token等量的“因果流查询”,采用因果注意力。每个查询Token只能关注它之前的所有查询Token以及全部的视觉Token。
这种设计使得“因果流查询”能够在看到完整视觉信息的基础上,逐步、有序地对这些信息进行重新梳理和排序,最终形成一个符合内容内在逻辑的“新阅读顺序”。只有这些经过重排序的“因果流查询”所输出的特征,才会被送入后续的大语言模型解码器中。这个过程,便是“视觉因果流”的精髓。
DeepEncoder V2 架构拆解
DeepSeek-OCR 2的整体流程依然遵循编码器-解码器范式,关键升级在于DeepEncoder V2模块。
1. 视觉分词器
与前代类似,首先使用一个由80M参数的SAM-base和两个卷积层构成的视觉分词器处理输入图像。它能实现16倍的视觉Token压缩,极大降低了后续模块的计算和存储开销。
2. 作为视觉编码器的语言模型
这是架构创新的核心。模型将视觉Token作为前缀输入,并在其后拼接上可学习的“因果流查询”作为后缀。这样,整个模块在一个统一的Transformer架构内,就能同时完成全局信息建模和序列因果重排两件事。
研究团队发现,这种“前缀+后缀”的解码器式架构至关重要。相比之下,将视觉Token隔离在独立编码器中的类mBART架构在实验中无法收敛。这表明,让视觉Token在所有网络层中保持“激活”状态,并与因果流查询进行充分、持续的信息交换,是模型成功学习的关键。
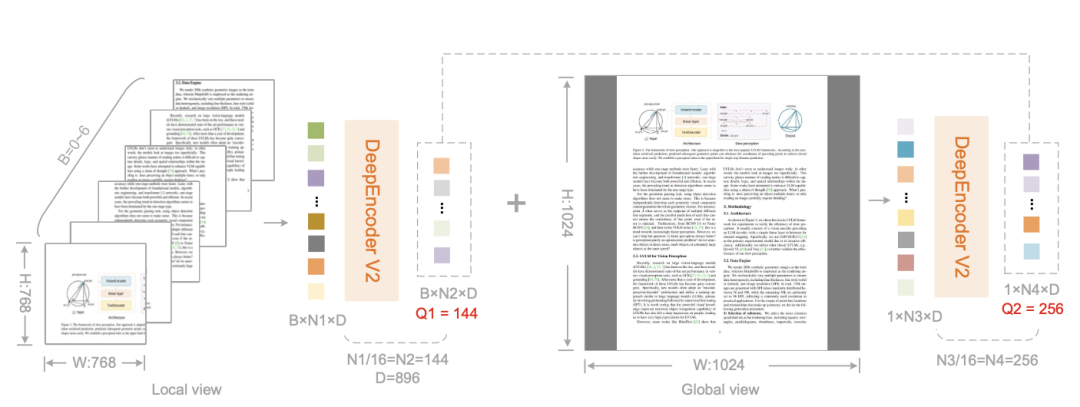
为了处理高分辨率文档图像,模型采用了多裁剪策略。一个1024x1024的全局视图产生256个Token,每个768x768的局部视图产生144个Token。通过组合0到6个局部视图,最终送入LLM的视觉Token数量可以在256到1120之间动态调整,这与Gemini 3 Pro的最大视觉Token预算基本持平。
3. 定制化的注意力掩码
为了实现上述“双轨”机制,DeepEncoder V2使用了如下图所示的注意力掩码。
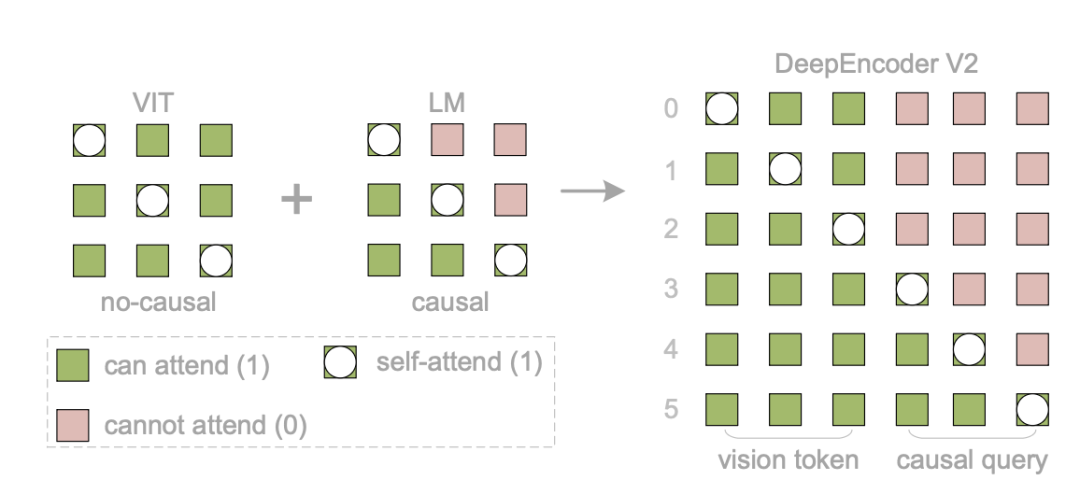
该掩码由两部分拼接而成:
- 左侧(视觉Token区域):是一个全1的矩阵,实现双向注意力,确保全局感知。
- 右侧(因果流查询区域):是一个下三角矩阵,实现严格的因果注意力,确保序列生成的有序性。
这种精妙的设计使得模型在单次前向传播中,就能无缝协同“无序感知”与“有序梳理”这两个任务。
4. 整体推理流程
整个DeepSeek-OCR 2的前向传播可概括为:编码器(DeepEncoder V2)通过因果流查询对视觉Token进行基于语义的逻辑重排;解码器(沿用前代的DeepSeek-MoE 3B模型)则对这个已经符合逻辑顺序的特征序列进行自回归推理,生成最终答案。 这实质上构建了一个“两阶段级联的因果推理”系统:第一阶段负责阅读逻辑推理,第二阶段负责具体的视觉任务推理。
实验结果:全面超越前代,性能达到SOTA
研究团队在主流的文档理解综合基准 OmniDocBench v1.5 上对DeepSeek-OCR 2进行了全面评估。该基准包含杂志、学术论文、报告等9大类共1355页复杂文档,覆盖中英双语。
主要结果
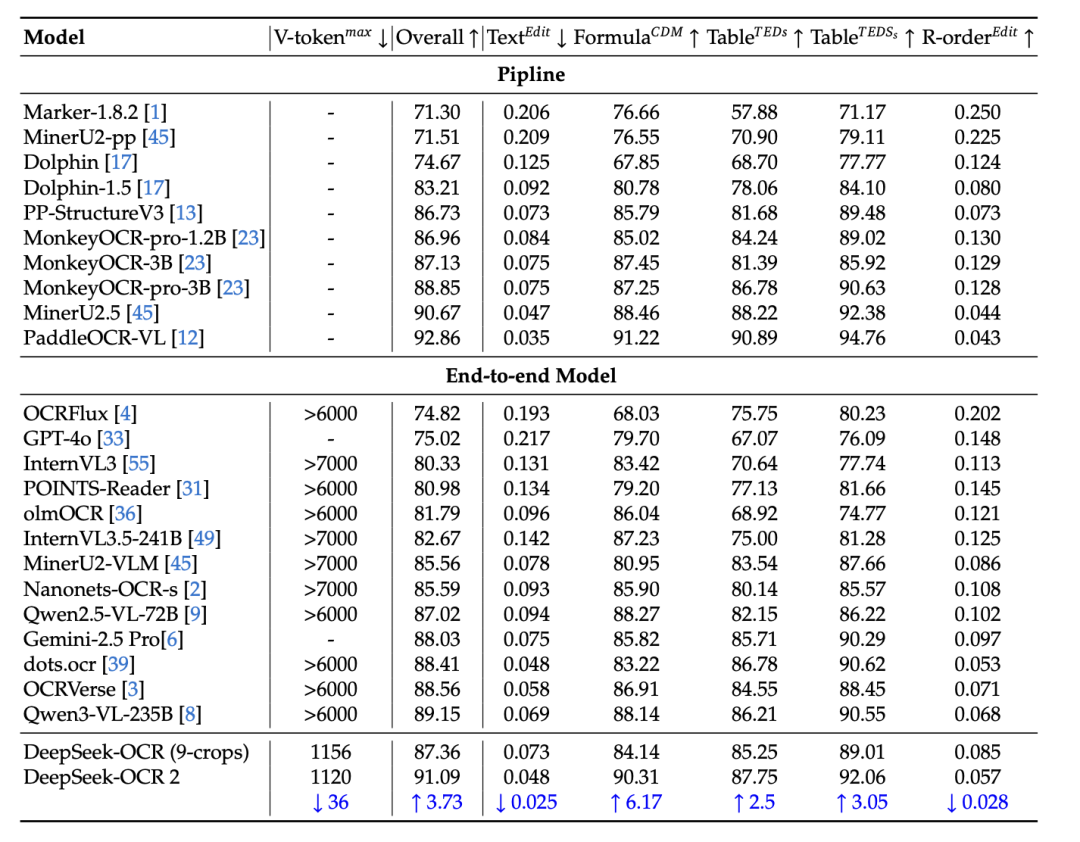
如上表所示,DeepSeek-OCR 2在所有端到端模型中,使用了最小的视觉Token上限(1120个),却取得了 91.09% 的SOTA综合得分。与基线模型DeepSeek-OCR(训练数据源相似)相比,性能提升了 3.73%。
最关键的是阅读顺序(R-order)的编辑距离指标,该值从DeepSeek-OCR的 0.085 大幅降低至DeepSeek-OCR 2的 0.057(降低了约32.9%)。这一结果强有力地证明了DeepEncoder V2能够有效理解图像信息,并对视觉Token进行智能选择和排序,显著提升了模型对文档逻辑结构的理解能力。
与顶级闭源模型对比
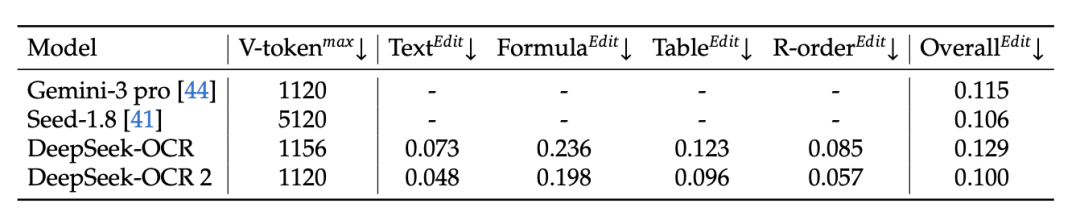
在与Gemini 3 Pro的直接比较中,DeepSeek-OCR 2在视觉Token预算相当(均为1120)的情况下,其整体编辑距离为 0.100,优于Gemini 3 Pro的 0.115,展现了更高的信息压缩效率和更强的综合性能。
实用性验证:重复率显著下降
在实际应用场景中,“重复率”是衡量模型是否真正理解内容逻辑、而非机械记忆的关键指标。

结果显示,无论是在处理在线用户日志图像还是预处理PDF数据时,DeepSeek-OCR 2的文本重复率均显著低于前代模型。这从实践角度印证了其新架构在提升逻辑视觉理解能力方面的有效性。
未来展望:迈向真正的2D推理与原生多模态
DeepSeek-OCR 2的探索意义并不仅限于OCR性能的提升。研究团队认为,这种架构为更宏大的目标奠定了基础。
1. 迈向真正的2D推理
“编码器负责重排阅读逻辑,解码器负责执行具体视觉任务”——这种将2D图像理解分解为两个互补的1D因果推理子任务的模式,可能为实现真正的2D推理提供了新的思路。未来,通过使用更长的因果流Token序列,模型或许能够实现对视觉内容的多次审视和多跳推理。
2. 迈向原生多模态
DeepEncoder V2成功验证了采用LLM风格编码器处理视觉任务的可行性。其更大的潜力在于,它可能演化为一个统一的全模态编码器。可以设想,未来只需要一个共享参数的编码器主干,通过为不同模态(文本、图像、语音、视频)加载专属的可学习查询前缀,就能统一处理所有类型的信息输入。DeepSeek-OCR 2在光学压缩和LLM风格编码器上的实践,标志着向原生多模态架构迈出了坚实的一步。
目前,DeepSeek-OCR 2的代码和模型权重均已在其GitHub仓库中开源,为社区研究和应用提供了宝贵的资源。对文档理解、多模态架构创新感兴趣的研究者和开发者,不妨深入了解这一前沿工作,共同探索视觉与语言融合的更多可能性。也欢迎大家在云栈社区的相关板块分享你的见解与实践经验。
项目地址:
http://github.com/deepseek-ai/DeepSeek-OCR-2
 发表于 2026-1-28 05:15:33
|
查看: 213|
回复: 0
发表于 2026-1-28 05:15:33
|
查看: 213|
回复: 0
