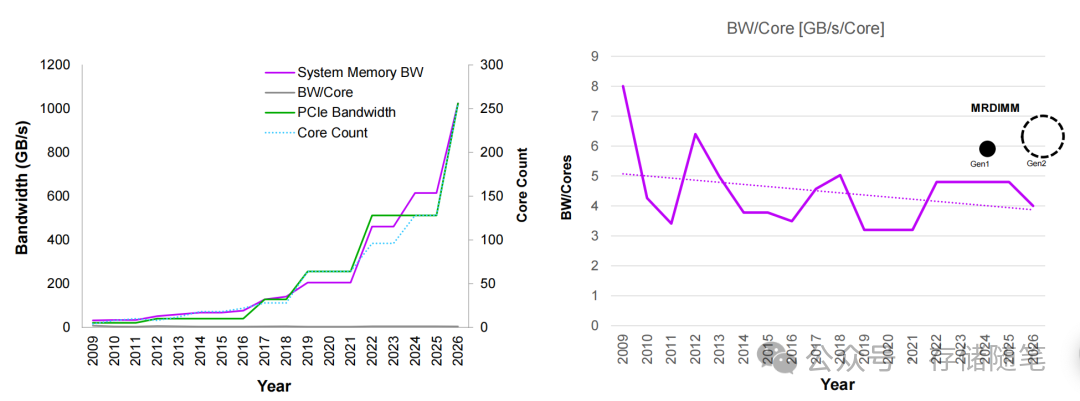
当AI大模型训练迈入千亿参数时代,当数据中心CPU核心数突破百核大关,一个沉寂多年的“老问题”再次成为行业瓶颈——内存墙。

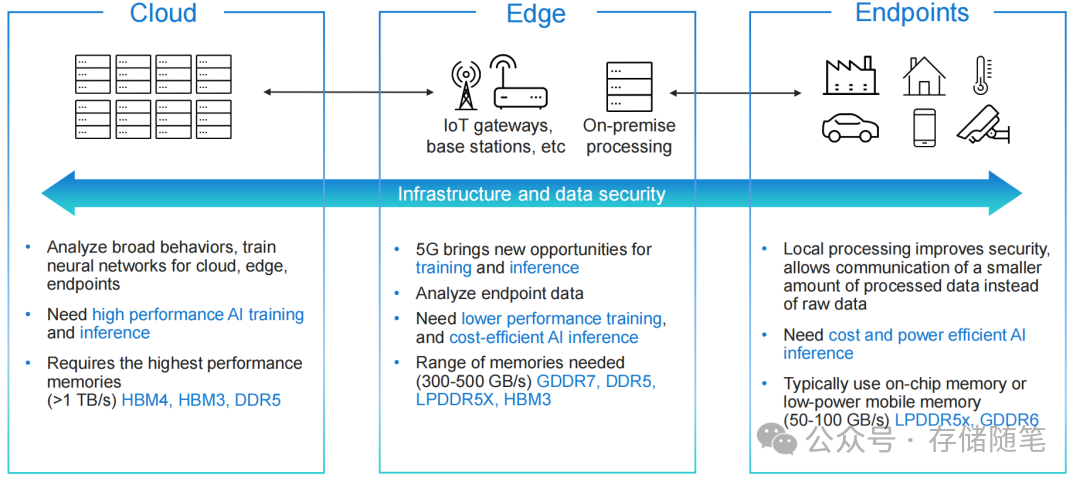
CPU算力、PCIe带宽每年都在以两位数增速狂飙,但传统内存的带宽、容量、功耗平衡始终难以跟上节奏。在此背景下,三款重量级内存技术登上舞台:MRDIMM、GDDR7、LPDDR5X。它们并非简单的替代关系,而是分别瞄准了数据中心高性能计算、边缘AI推理、低功耗云原生三大核心场景,共同掀起一场内存技术的革新。本文将对这三款“性能利器”进行深度拆解,剖析其核心技术原理与适用的实际场景。
一、MRDIMM:数据中心的“带宽猛兽”,专治百核CPU的“饥饿症”
对于数据中心运维工程师而言,面对128核的GNR-AP CPU时,常会遇到一个尴尬场景:CPU算力过剩,但内存带宽成为瓶颈,导致程序在数据传输环节“空转”。这正是典型的“内存墙”困境,而MRDIMM正是为破解此难题而生。
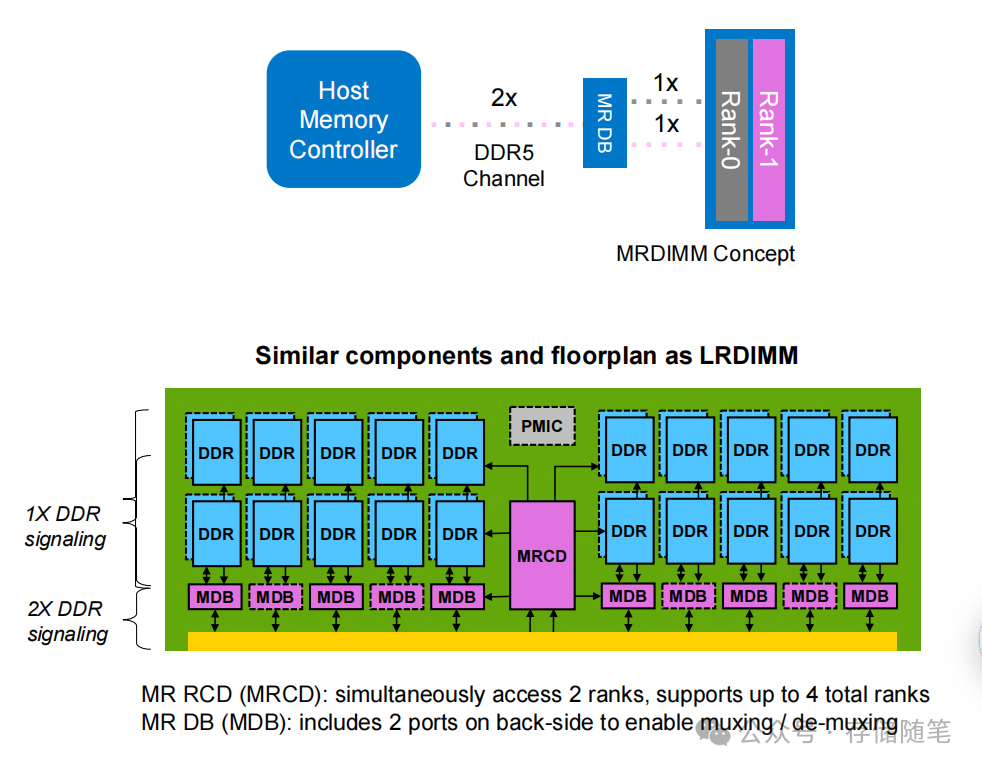
MRDIMM的巧妙之处在于它并未颠覆DDR5生态,而是进行了“底层优化”。它基于标准DDR5的机械和电气接口,兼容现有服务器平台,通过“Rank多路复用”技术实现了带宽的翻倍:
- 核心原理:将2个DDR5 Rank通过MRCD(MR Rank控制器)和MDB(多路复用器)整合成“伪通道”,使内存控制器能同时访问2个Rank,相当于将DDR5的“单车道”拓宽为“双车道”。
- 性能参数:Gen1版本初始速度即达8800 MT/s,容量覆盖32GB至256GB,支持2Rx4、4Rx8等多种配置,生态兼容性极佳。
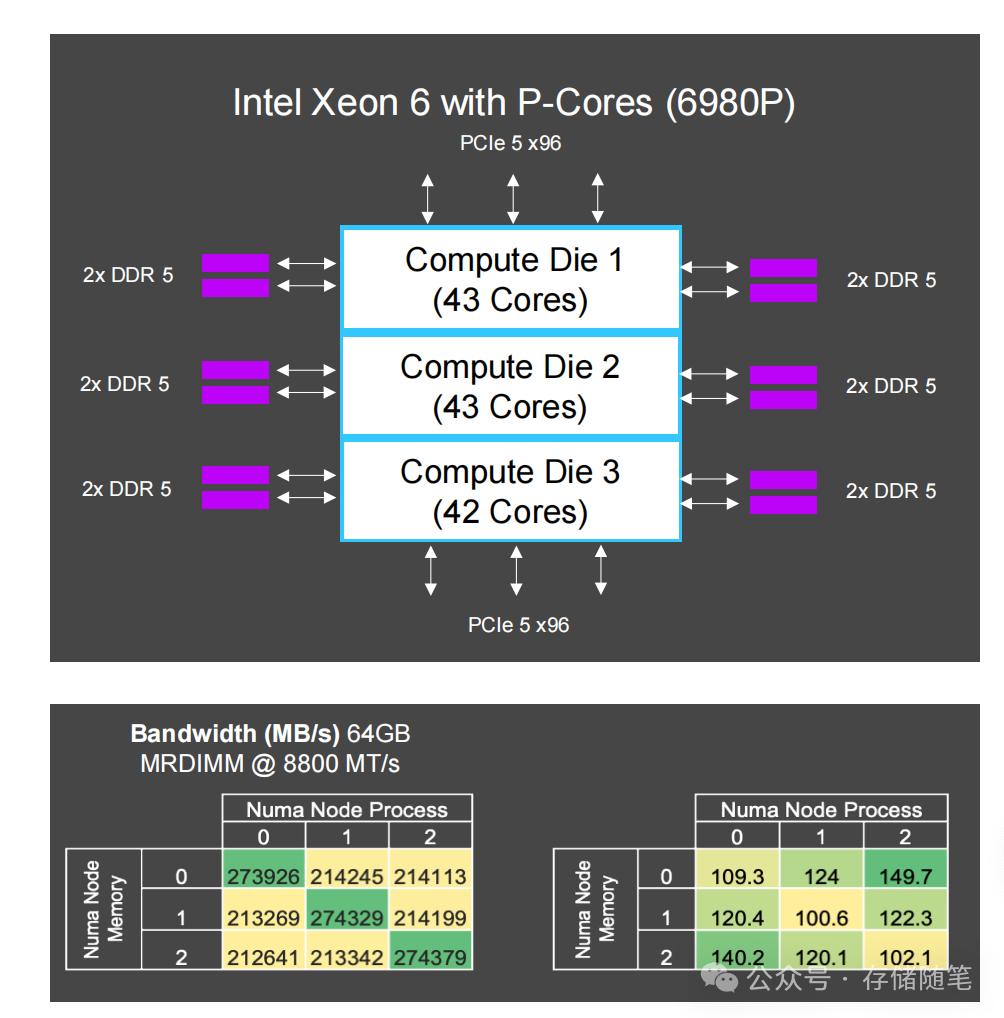
技术原理之外,实测数据更具说服力。在GNR-AP 128核CPU平台上,MRDIMM展现出了“碾压级”的性能:
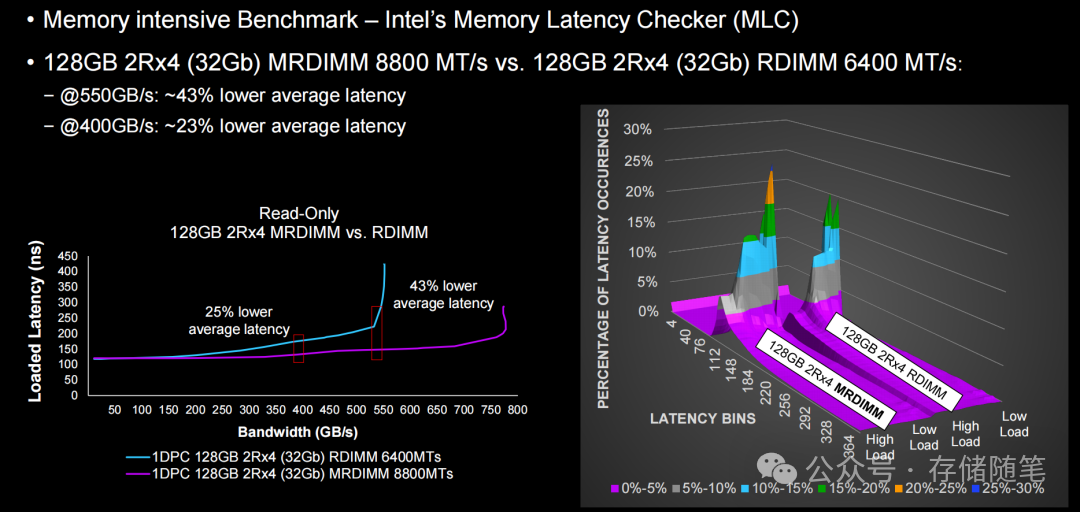
- 带宽表现:在Intel MLC只读测试中,128GB MRDIMM(8800 MT/s)带宽突破780 GB/s,比传统RDIMM(6400 MT/s)提升37%,完美匹配百核CPU的数据吞吐需求。
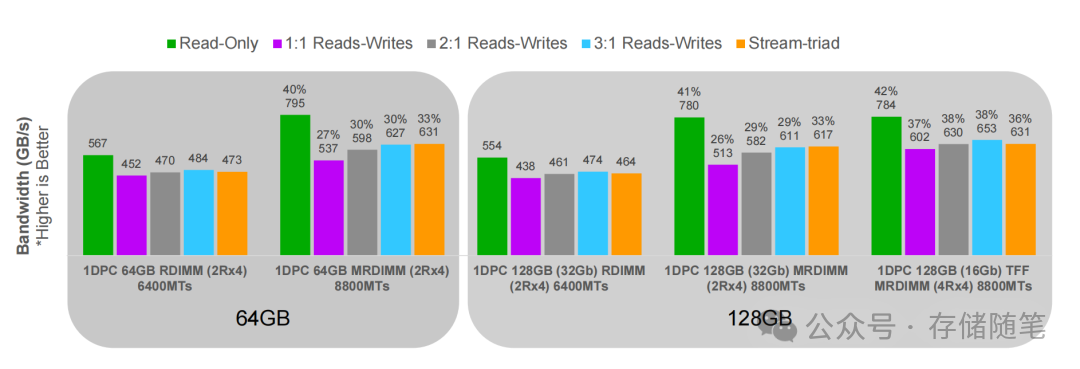
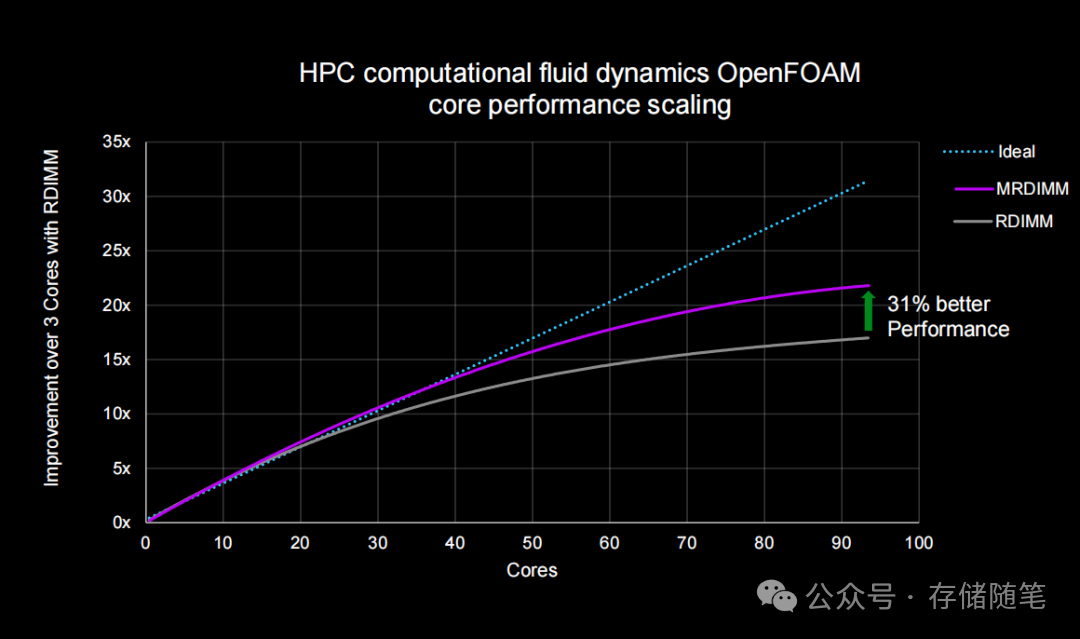
- HPC场景:在OpenFOAM流体力学仿真中,96核满负载下,MRDIMM比RDIMM性能提升31%,意味着用同等电力可完成更多计算任务。
- AI场景:在RAG向量数据库测试中,128GB MRDIMM实现了1.2倍QPS提升,同时延迟降低30%;在Apache Spark SVM机器学习任务中,256GB MRDIMM更是实现了1.7倍的提速,并减少了70%的存储I/O。


MRDIMM不仅在速率(8800 MT/s)上高于RDIMM(6400 MT/s),还能在高带宽、高负载场景下,同时实现更低的延迟和更稳定的延迟表现——这正是数据中心、HPC等场景最需要的内存特性。
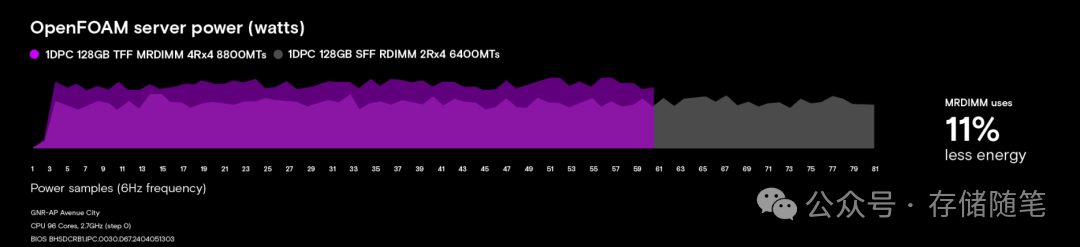
功耗表现同样值得关注:虽然MRDIMM的峰值功耗略高于RDIMM(128GB版本18.2W vs 11.4W),但由于任务完成速度更快,单位任务能耗反而降低了11%。对于24小时不间断运行的数据中心而言,这意味着可观的电费节省,是运维/DevOps工作中需要重点考量的效率提升点。

MRDIMM并非“万金油”,它是为“性能优先”场景量身定制的解决方案,主要适用于:
- 配备百核/多核CPU的服务器、HPC集群(如流体力学、气象模拟);
- AI训练与推理(如RAG向量库、大模型微调);
- 高并发数据库、分布式计算等对内存带宽敏感的负载。
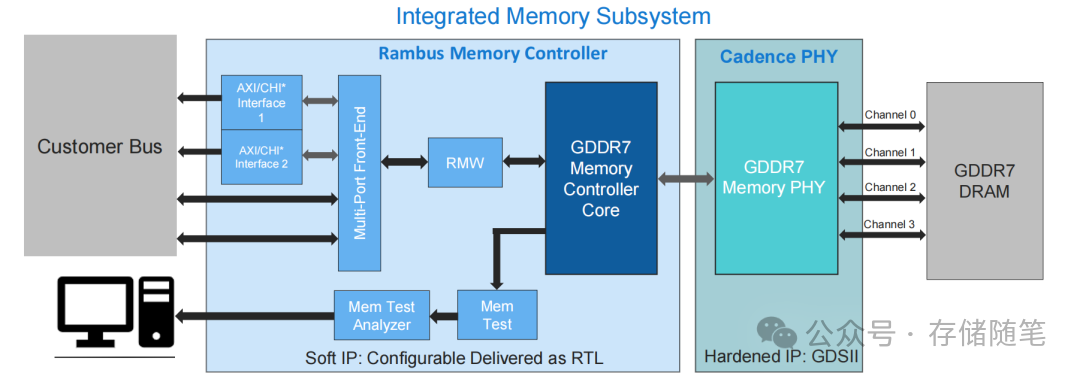
二、GDDR7:边缘AI的“性价比王者”,无需2.5D封装也能飙速
如果说MRDIMM是数据中心的“重型装备”,那么GDDR7就是边缘AI的“轻量化神器”。随着5G基站、IoT网关、边缘服务器对AI推理需求的爆发式增长,市场亟需一种“高性能、低成本、易部署”的内存解决方案——GDDR7应运而生。
GDDR7的最大突破在于采用了PAM3(三电平脉冲幅度调制)信号技术,这是JEDEC DRAM标准中首次引入该技术:
- 传统NRZ调制:每个周期只能传输1位数据(0或1);
- PAM3调制:通过+1、0、-1三个电平,实现每2个周期传输3位数据,在相同时钟频率下带宽提升50%。
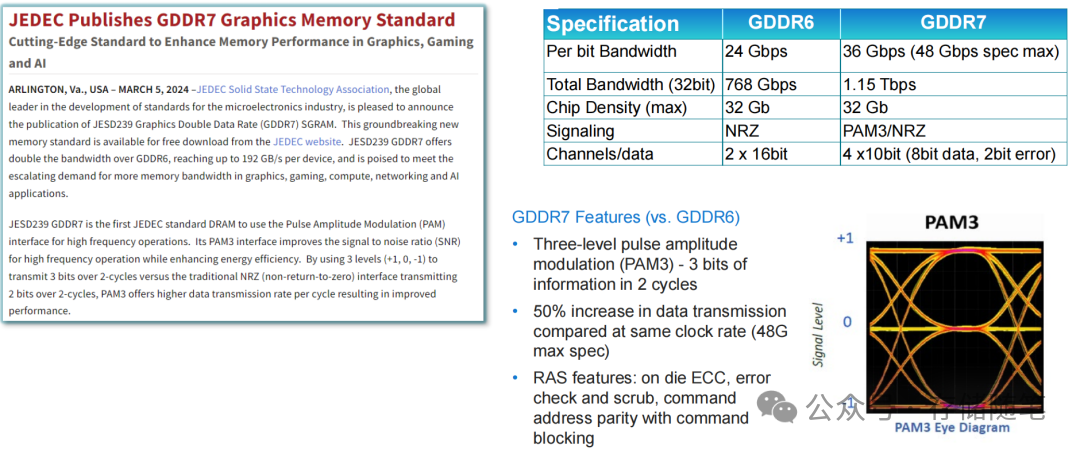
配合4通道x10bit(8bit数据+2bit纠错)的架构,GDDR7单芯片带宽可达192 GB/s,32bit配置下总带宽更是突破1.15 Tb/s,是GDDR6的两倍。更重要的是,它保留了GDDR系列“直接贴装PCB”的优势,无需HBM所需的2.5D/3D高级封装,大幅降低了系统成本。
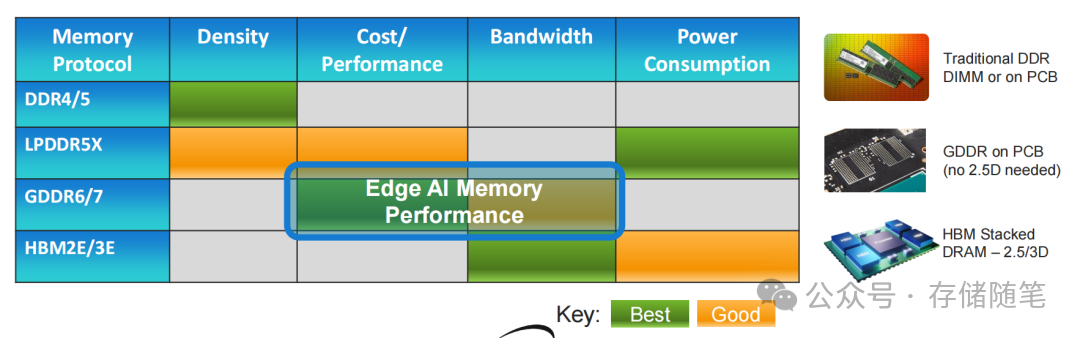
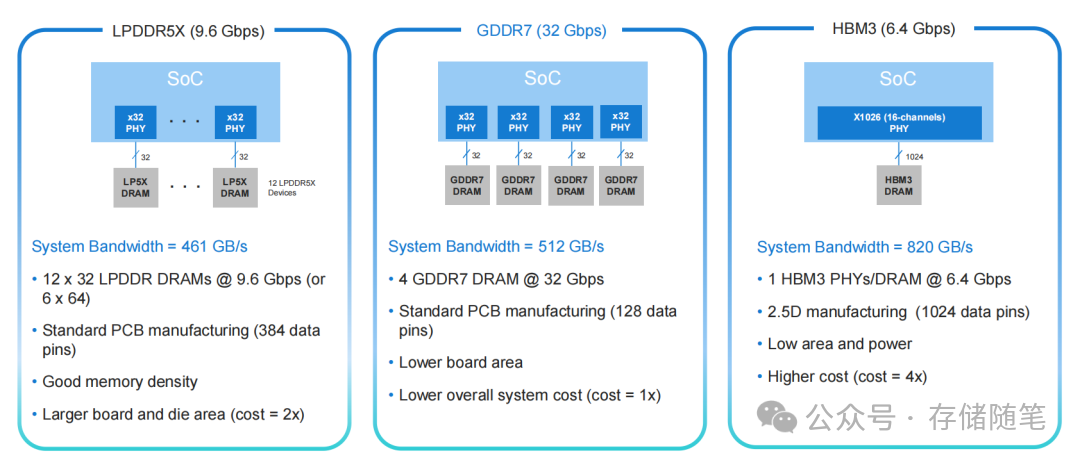
以边缘AI推理典型的500 GB/s带宽需求为例,对比不同内存方案:
- LPDDR5X:需要12颗芯片+384个数据引脚,主板面积大,成本约为GDDR7的2倍;
- HBM3:虽然只需1颗芯片,但2.5D封装成本是GDDR7的4倍,小批量部署不经济;
- GDDR7:仅需4颗芯片+128个数据引脚,采用标准PCB制造工艺,带宽达512 GB/s,完美满足需求,成本优势显著。
此外,GDDR7还继承了完善的RAS(可靠性、可用性、可服务性)特性:包括片上ECC、错误检查与擦洗、命令地址奇偶校验等,有效解决了边缘设备“无人值守”时的稳定性痛点。对于安防监控、工业质检、边缘网关等场景而言,“高性能+低成本+高可靠”的组合堪称量身定制。
GDDR7的定位非常清晰,主要瞄准以下应用:
- 边缘AI推理(如图像识别、语音助手、工业AI);
- 中端AI训练(如小模型微调、边缘节点协同训练);
- 游戏主机、高端显卡、网络交换机等对带宽敏感的设备。
三、LPDDR5X:数据中心的“节能先锋”,低功耗下的高性能担当
提及LPDDR,许多人首先联想到“手机内存”。但实测数据表明,这款“低功耗选手”在数据中心场景下同样能“挑大梁”。尤其在AI推理、HPC等领域,LPDDR5X以“77%的功耗降低搭配36%的带宽提升”的表现,重新定义了“绿色计算”。
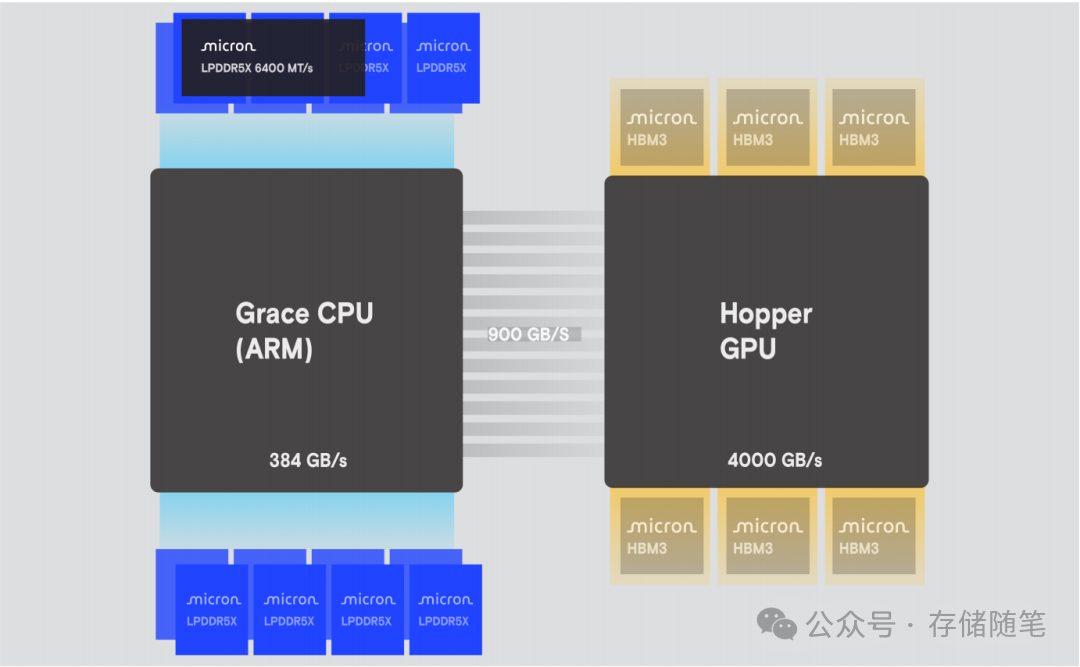
LPDDR5X并非简单地从移动端移植,而是针对数据中心进行了关键优化:
- 带宽强化:最高速率达9.6 Gbps,通过多通道配置,单系统带宽可突破293 GB/s;
- 功耗优化:采用1.1V低电压设计,配合动态频率调节,其DRAM功耗比DDR5降低77%;
- 互联增强:在NVIDIA GH200系统中,支持CPU-GPU高速互联,设备间传输速度达346 GB/s,是DDR5的6倍。
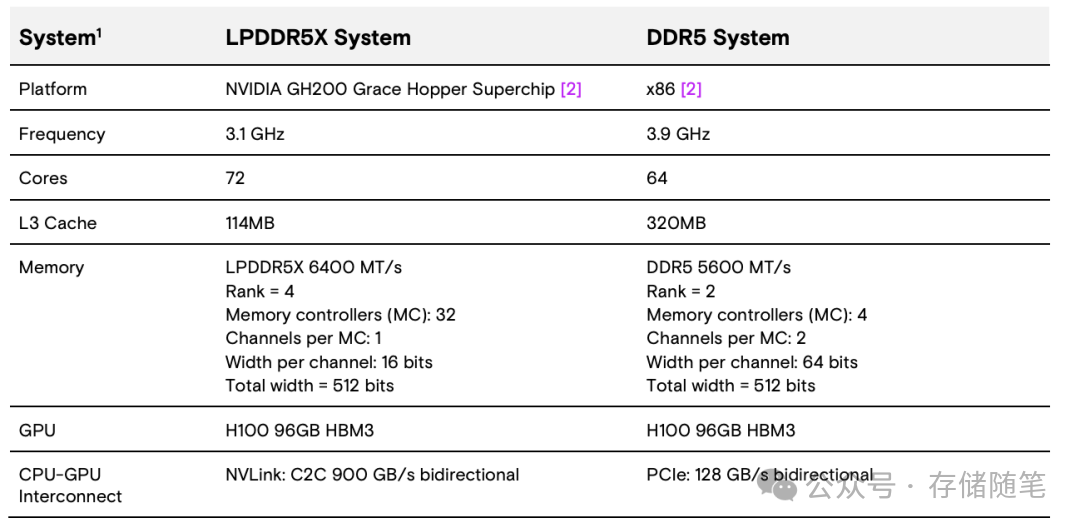
在NVIDIA GH200(ARM CPU + H100 GPU)平台上,LPDDR5X的表现令人印象深刻:
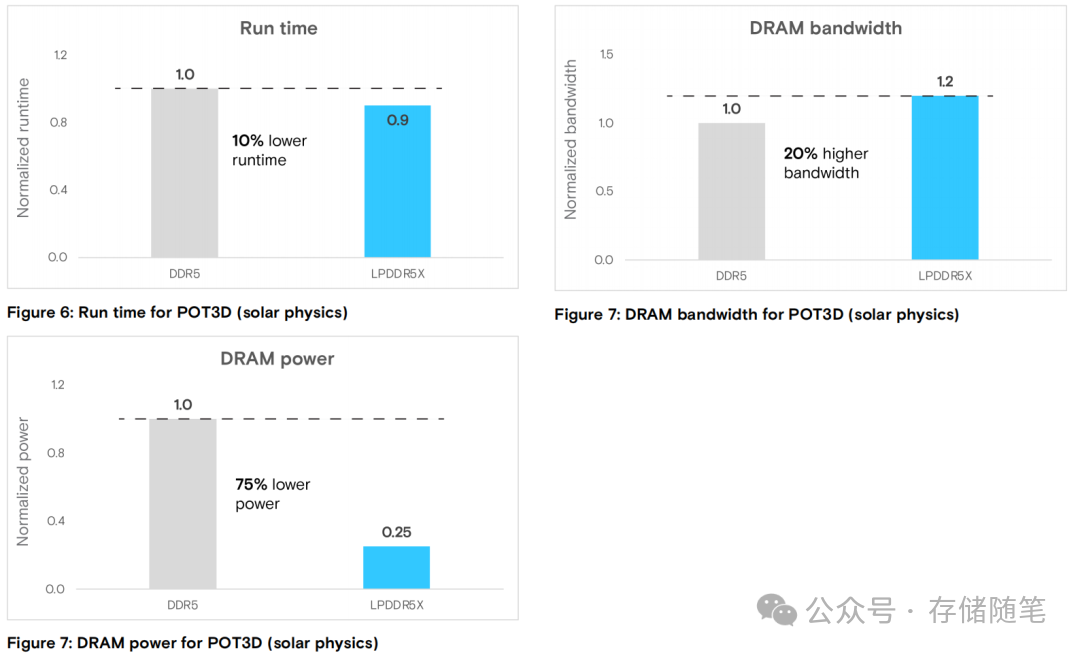
- HPC场景(太阳物理POT3D模拟):运行时间缩短10%,带宽利用率提升20%,DRAM功耗降低75%;
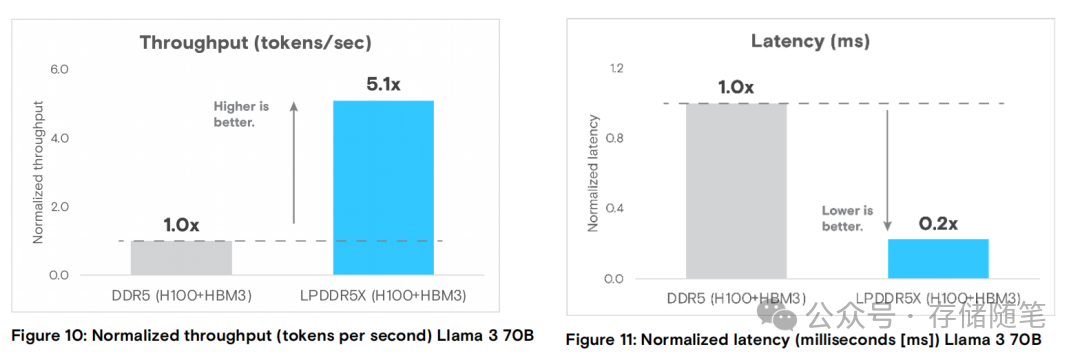
- AI推理场景(LLaMA-3 70B模型):吞吐量是DDR5的5倍,延迟降低80%,系统能耗减少73%。这对于大规模人工智能模型的部署与推理服务至关重要。
- 统一内存支持:借助GH200的缓存一致性架构,LPDDR5X能支持相当于传统内存2.5倍的工作负载规模,无需开发者手动进行复杂的内存分配,极大简化了应用开发。
对数据中心而言,LPDDR5X的价值远超“省电”。按当前电价估算,一台采用LPDDR5X的服务器每年可节省电费数千元,大规模部署则能减少上万吨碳排放,高度契合“双碳”战略目标。
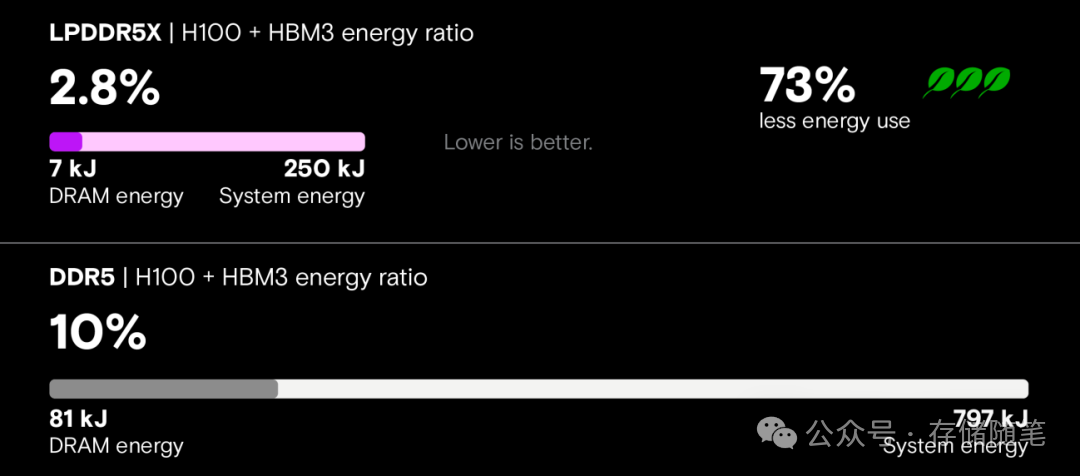
LPDDR5X的核心优势在于其卓越的“功耗-性能比”,主要瞄准以下场景:
- 云原生AI推理(如大模型部署、API服务);
- 低功耗HPC(如气象模拟、天体物理计算);
- 绿色数据中心、边缘云节点及高密度服务器集群。
总结与展望
简单来说,这三款内存技术各有侧重:
- 若您运营超算中心或大型云平台,追求极致性能,MRDIMM是首选。
- 若您是边缘设备厂商或中型AI企业,追求高性价比,GDDR7更为合适。
- 若您致力于建设绿色数据中心或提供云服务,追求低功耗与高性能的平衡,LPDDR5X值得考虑。
这三款内存技术的崛起,标志着内存行业从“单一迭代”迈入了“场景化创新”的新阶段。未来几年,我们有望看到更多进展:
- MRDIMM Gen2:速度将突破12800 MT/s,在进一步提升性能的同时优化功耗。
- GDDR7普及:随着JEDEC标准完善,更多厂商将推出相关产品,持续降低边缘AI部署成本。
- LPDDR6:下一代低功耗内存将实现更高带宽与更低功耗,或将成为数据中心的更优选。
更重要的是,内存技术正从“被动适配”CPU/GPU,转变为“主动定义”计算架构的关键一环。无论是MRDIMM的“带宽优先”、GDDR7的“性价比优先”,还是LPDDR5X的“功耗优先”,其本质都在于解决“快速增长的计算需求与有限系统资源”之间的矛盾。
这场内存革命才刚刚开始。对于云原生/IaaS及整个计算产业而言,它意味着更高效的资源利用、更普惠的算力以及更智能的边缘应用,最终将深刻影响技术发展的轨迹与数字生活的体验。
 发表于 2025-12-15 09:58:45
|
查看: 334|
回复: 0
发表于 2025-12-15 09:58:45
|
查看: 334|
回复: 0
