你是否想过,你的Transformer模型可能在无效地消耗算力?NeurIPS 2025的最佳论文揭示了一个巧妙的改进:为Attention机制添加一个简单的“门控”,就能以极小的参数量代价换取显著的性能提升。
本文将深入解析来自Qwen团队的Gated Attention(门控注意力)机制的核心思想,并提供清晰的PyTorch实现代码。
核心问题:注意力需要“节制”
Transformer的核心是自注意力(Self-Attention)机制。然而,一个潜在的问题是,模型是否对所有输入词元(Token)都给予了必要且恰当的“关注”?不加区分的注意力分配不仅会浪费计算资源,还可能引入不必要的噪声,影响模型的表示能力。
Qwen团队的Gated Attention,本质上是为注意力机制引入了一个数据依赖的“调节阀”,让模型学会动态地抑制或增强信息流。
原理一图览
传统的注意力计算在得到注意力权重后,会直接与值(Value)向量加权求和。而Gated Attention则在输出前增加了一个门控步骤,该门控信号由输入自适应生成。
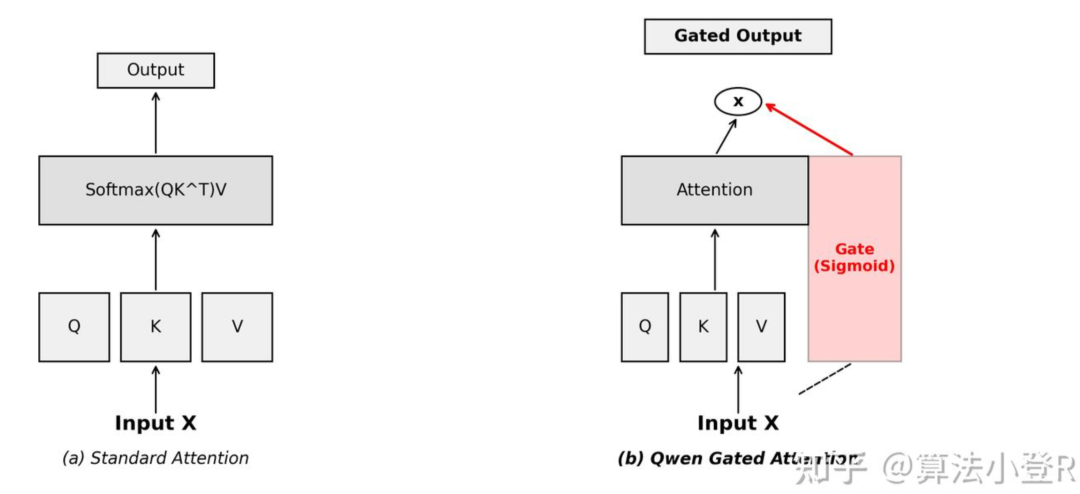
标准Attention与Qwen Gated Attention的架构对比。右侧红色的Gate模块如同一个智能水龙头,控制着信息流的通断与强弱。
PyTorch核心代码实现
该方法的实现非常优雅,仅在标准注意力模块的基础上增加了一个轻量的门控投影层。这个门控值介于0到1之间,起到非线性调节作用:
- 门控值 ≈ 1:重要信息,畅通无阻。
- 门控值 ≈ 0:冗余或噪声信息,有效拦截。
以下是根据论文思想简化的PyTorch实现:
import torch
import torch.nn as nn
import torch.nn.functional as F
class GatedAttention(nn.Module):
"""
Qwen Gated Attention (简化实现版)
基于 NeurIPS 2025 Best Paper 的核心思想。
传统 Attention: Output = Softmax(QK^T) * V
门控 Attention: Output = (Softmax(QK^T) * V) * Gate
"""
def __init__(self, d_model, n_head):
super().__init__()
self.n_head = n_head
self.d_head = d_model // n_head
# 标准的 Q, K, V, O 投影层
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_o = nn.Linear(d_model, d_model)
# 门控投影层:参数量增加极少
self.w_gate = nn.Linear(d_model, d_model)
def forward(self, x):
batch, seq, _ = x.shape
# 1. 标准 Attention 计算流程
q = self.w_q(x).view(batch, seq, self.n_head, self.d_head)
k = self.w_k(x).view(batch, seq, self.n_head, self.d_head)
v = self.w_v(x).view(batch, seq, self.n_head, self.d_head)
# 计算注意力分数
attn_scores = torch.einsum(‘bqhd,bkhd->bhqk‘, q, k) / (self.d_head ** 0.5)
attn_probs = F.softmax(attn_scores, dim=-1)
# 聚合上下文信息
context = torch.einsum(‘bhqk,bkhd->bqhd‘, attn_probs, v)
context = context.reshape(batch, seq, -1)
# 2. 核心创新:数据依赖的门控机制
# 根据输入 x 动态计算门控值 (范围在0~1)
gate = F.sigmoid(self.w_gate(x))
# 3. 门控输出
gated_context = context * gate
return self.w_o(gated_context)
技术价值与意义
Gated Attention的贡献远不止于参数微调,它是对经典Transformer架构一次有深刻见解的修正:
- 提升数值稳定性:随着网络层数加深,信号在传统Transformer中可能发生衰减或爆炸。门控机制引入了非线性的调节作用,有助于稳定信息流动,这对训练更深、更稳定的AI大模型尤为重要。
- 实现隐式稀疏化:尽管计算仍是稠密的,但门控使模型学会了“选择性忽略”,这等效于一种软稀疏(Soft Sparsity),能提升计算效率。
- 极高的性价比:门控投影层增加的参数量通常不到1%,但在实验中能带来可观的损失(Loss)下降,对于研究者构建或微调模型是一个值得尝试的改进点。
对于使用PyTorch进行模型开发的工程师和研究者而言,将Gated Attention模块集成到现有架构中是一个低成本、高潜在收益的优化策略。
本文内容基于NeurIPS 2025最佳论文《Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free》进行解读,论文链接:https://arxiv.org/abs/2505.06708
 发表于 2025-12-15 13:27:52
|
查看: 400|
回复: 0
发表于 2025-12-15 13:27:52
|
查看: 400|
回复: 0
