Vosk是一款由阿尔汉格尔斯克国立技术大学团队开发的开源、离线优先语音识别工具包。其核心优势在于模型轻量、支持多语言且完全本地运行,无需网络连接。本文将解析Vosk如何在嵌入式设备和隐私敏感场景下,以极低的资源占用成为云端服务的替代方案,并探讨其技术实现与适用边界。
当智能音箱必须联网才能执行指令,或车载语音助手在信号盲区失效时,我们是否默认了高精度的语音识别必然依赖云端?Vosk的出现,正在挑战这一固有认知。它凭借完全离线、超轻量级、开源免费三大特性,成为在隐私、成本和可靠性敏感场景下,一个强有力的本地化解决方案。
其最小的英语识别模型仅约50MB,中文模型也在百兆级别。这个极小的体积意味着硬件门槛大幅降低:树莓派、老旧安卓手机乃至各类嵌入式开发板,都能流畅运行并实现实时识别,让AI能力真正下沉到物联网终端。由于模型完全本地加载,从音频输入到文本输出的延迟可控制在毫秒级,为需要实时交互的应用提供了可能。对开发者而言,成本结构得以重塑:无需为API调用付费,一次部署即可无限次使用,边际成本趋近于零。Vosk的轻量化并非以牺牲核心功能为代价,而是在精度与体积间找到了专为“边缘计算”场景设计的平衡点。
“离线”是Vosk最核心的优势。所有语音数据处理均在设备本地完成,音频数据无需离开用户设备。这带来了三重根本价值:绝对的数据隐私,消除了医疗、法律、会议等敏感场景下的信息泄露风险;无网络依赖的高可靠性,在工厂、野外、车载等弱网或无网环境下保证服务连续性;以及近乎零网络延迟的响应体验,实现真正的实时流式识别。然而,必须正视其代价:离线也意味着无法利用云端海量数据进行持续迭代优化,这导致Vosk在复杂口音、强噪声环境和专业术语识别上,其精度通常低于顶级的商业云端API。它用隐私和可靠性,交换了部分精度的上限。
Vosk在GitHub上完全开源,并提供了超过20种语言的预训练模型。开源带来的真正力量是极致的定制自由度:开发者可以深入其基于Kaldi的架构,甚至使用自有数据对模型进行领域自适应训练,以提升特定行业术语的识别率。项目还提供了Python、Java、C#等多达七种编程语言的API绑定,极大降低了集成门槛。但开源同样是一把双刃剑:不同语言模型的精度并不均衡,主流语言模型相对成熟,而一些小语种模型可能因训练数据不足而效果一般;同时,其模型更新速度与官方支持力度相比商业公司存在不确定性。选择Vosk,也意味着需要承担一部分自行研究和解决问题的责任。
技术架构解析:轻量化与高效识别的平衡术
Vosk能在50MB的微型身材里实现实用的语音识别能力,其技术架构的精妙设计是关键。它并非从零创造,而是通过巧妙的取舍与优化,在资源、精度和实时性之间找到了独特的平衡点。
基于Kaldi的DNN-HMM混合架构:轻量背后的技术实力
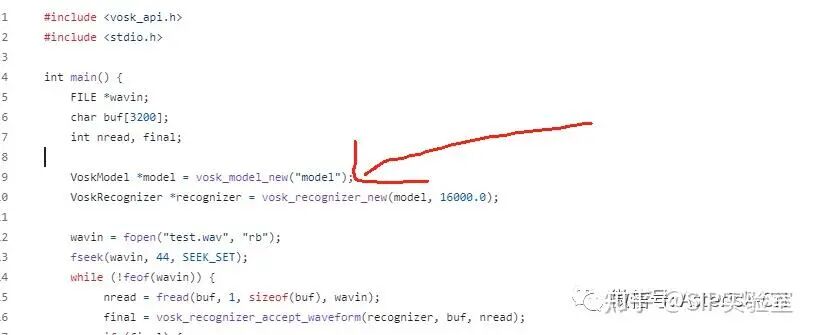
Vosk的核心引擎源于Kaldi——一个在学术界和工业界广泛使用的开源语音识别工具包。它采用了经典的DNN-HMM(深度神经网络-隐马尔可夫模型)混合架构,这是一条成熟且务实的技术路线。
- DNN负责“听清”:深度神经网络处理原始音频,提取高维声学特征,识别音素。
- HMM负责“听懂”:隐马尔可夫模型对音素序列进行时序建模,结合语言模型,将其组合成连贯的词句。
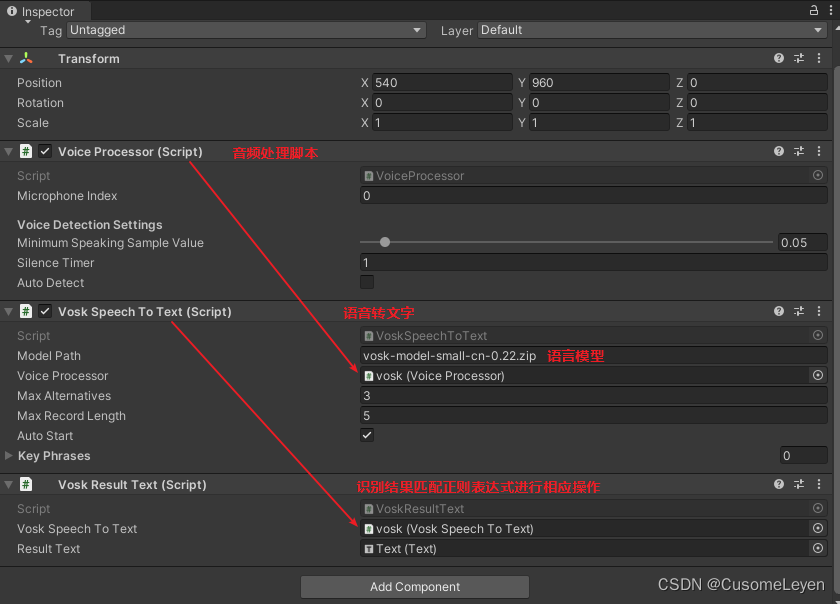
Vosk的“轻量化”魔法,并非阉割了Kaldi的核心能力,而是进行了极致的工程优化和模型压缩。通过剪枝、量化等技术,将原本数GB的模型“瘦身”至50MB左右,使其能在树莓派等资源受限设备上运行。这是一种面向边缘计算的“定向优化”,其代价是部分牺牲对复杂场景的泛化能力,更专注于在有限资源下提供稳定、可用的识别结果。
流式识别与低延迟处理:实现实时交互的关键
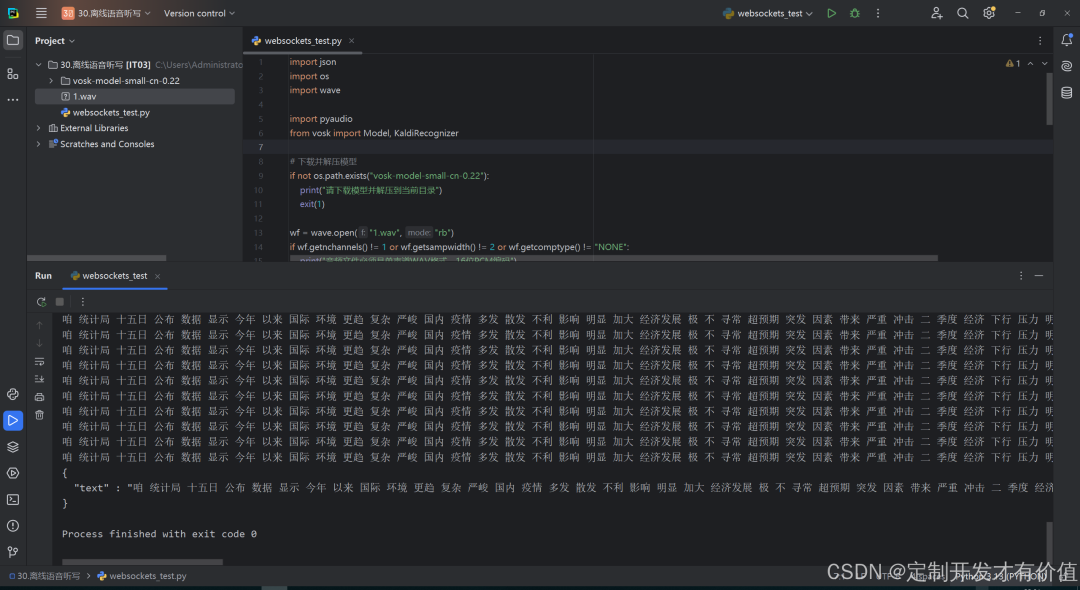
离线语音识别的核心挑战之一是实时性。Vosk的原生流式API(Streaming API)使其能够实现“边说边识”,达到极低的延迟体验。
其低延迟的实现依赖于几个关键设计:
- 增量解码:模型能够对输入的音频帧进行即时解码,生成部分文本假设,并随着更多语音信息的到来不断修正。
- 高效的声学特征提取:快速将原始音频转换为梅尔频率倒谱系数等模型可理解的特征。
- 精简的语言模型:使用较小的n-gram语言模型,在有限资源下有效约束识别路径,加速搜索过程。
这使得Vosk在树莓派或老旧手机上,也能实现延迟低于500毫秒的近乎实时语音转文字,为语音指令、实时字幕等交互场景提供了可能。
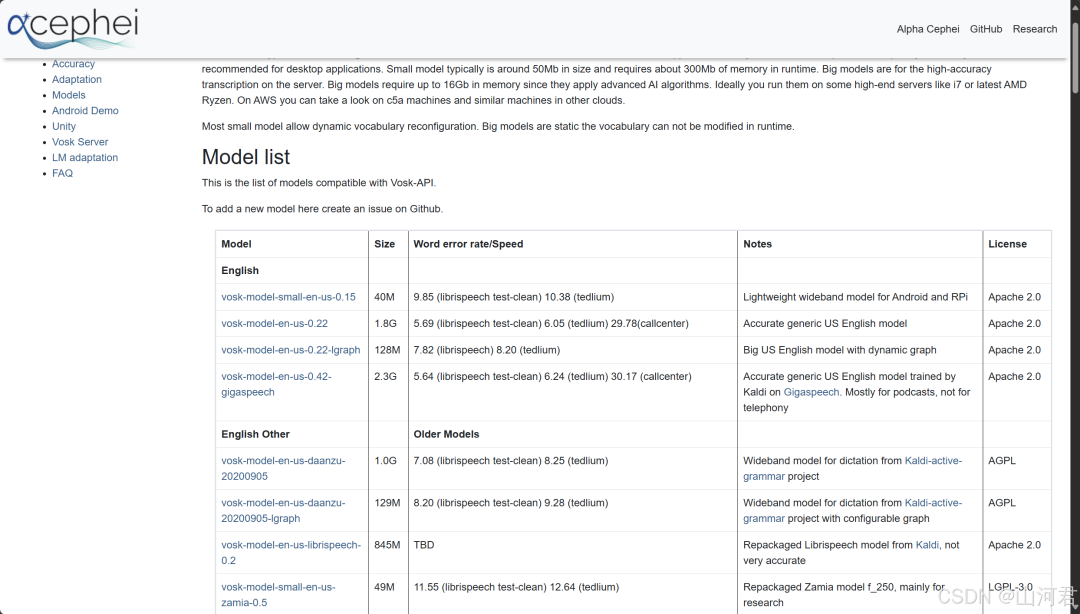
大小模型策略:从移动端到服务器级的灵活部署

Vosk没有追求单一通用模型,而是提供了阶梯式的模型家族,这是其部署灵活性的关键所在,也让开发者必须在“体积、速度、精度”之间做出明确取舍。
- 超轻量模型(~50MB):如
vosk-model-small-en-us-0.15。针对极致资源受限场景,如树莓派、低端安卓设备。识别词汇量有限,但对特定命令词或简单句子的识别效率极高。
- 标准及大型模型(200MB - 数GB):适用于服务器或高性能计算环境,追求接近商用云端服务的识别准确率,可用于长篇转录。
这种策略让开发者可以根据硬件算力、存储空间和精度需求进行精准匹配。选择Vosk,本质上是在资源约束、隐私安全和绝对识别精度之间做出权衡。
实战应用与局限:Vosk并非万能解药
Vosk的轻量化与离线特性,使其在特定领域成为理想选择。然而,开发者必须清醒认识其能力边界。选择Vosk,是在特定约束条件下寻找最优解。
最佳应用场景:嵌入式设备、隐私敏感转录、实时字幕生成
Vosk的真正价值,在于那些云端服务难以触及或成本过高的“边缘地带”。
- 嵌入式与边缘计算设备:这是Vosk的“主场”。在树莓派、工控机、Android/iOS移动设备等资源受限平台,其50MB级模型是少数能流畅运行的方案,非常适合构建离线语音控制的智能家居中枢或工业指令系统。
- 实时交互与字幕生成:凭借其流式API和低延迟,Vosk适合需要即时反馈的应用。例如,为视频会议提供实时字幕、开发本地语音助手,或在网络不稳定环境下实现语音指令的即时响应。
核心洞察:Vosk的核心竞争力并非“最强”,而是“最合适”。它在成本、隐私和部署灵活性上建立了优势,专为“有网络限制或数据隐私要求”的场景而生。
正视局限:与顶级云端API的精度差距、模型定制复杂性
然而,开源与免费的另一面,是开发者必须正视的技术折衷。
- 识别精度存在客观差距:尽管日常场景下表现良好,但在复杂口音、强噪声环境、专业领域术语识别上,其准确率与Google、微软等顶级商业云端API存在可感知的差距。
- 模型定制门槛高:虽然支持自定义,但深度定制或训练新语言模型需要深入理解其底层Kaldi架构,过程复杂,不如调用云端定制化API简便。
- 功能完整性需补充:例如,其原生输出可能缺少智能分段和标点,对音频格式有严格要求。像语音活动检测(VAD)等后处理模块,需要开发者自行集成,增加了工程复杂度。
最终的选型逻辑:
- 如果项目强需求是离线、隐私、低成本或嵌入式部署,Vosk是当前非常优秀的选择。
- 如果追求极致的识别准确率、需要复杂定制化、且没有离线硬性要求,成熟的商业云端服务仍是更强大、省心的方案。
技术选型没有银弹,关键在于找到最契合场景的工具。
 发表于 2025-12-15 21:54:30
|
查看: 426|
回复: 0
发表于 2025-12-15 21:54:30
|
查看: 426|
回复: 0
