英伟达(NVIDIA)以约9亿美元的价格完成了对Enfabrica核心团队的“人才并购”并获得了其核心技术的授权。这意味着在不久的将来,英伟达的超节点服务器有望实现:
「物理层协议大一统」与「算力/访存深度解耦」,从而彻底打破PCIe、以太网与CXL之间的协议壁垒,将成千上万颗离散的GPU融合为一台延迟更低、资源可弹性调度的「机架级单体巨型计算机」。
在AI计算领域,一个长期被忽视的残酷现实是:数据中心最昂贵的资源——“有效的计算周期”,正被物理层协议的不兼容性悄然侵蚀。这种协议间的“翻译代价”已成为AI算力扩张中最大的隐形税收。
成立仅四年的初创公司Enfabrica,凭借其ACF-S芯片技术,正从第一性原理出发重构AI数据中心网络。其核心突破在于实现了物理层协议的彻底收敛,将数据从“多级跳”转变为“一跳直达”,为下一代AI算力基础设施奠定了新的基础。
协议摩擦:AI算力的隐形天花板
在传统AI服务器架构中,数据移动面临物理层的断层。当一个GPU需要与远程GPU通信时,数据必须经历冗长的协议转换之旅:从GPU通过PCIe协议传输至PCIe交换机,再进入网卡芯片封装成以太网协议,最后通过光模块发向网络。
这种架构产生了三重致命的“协议税”:
- SerDes功耗陷阱:每一次跨芯片的物理连接都需要经过串行/解串器,数据在GPU-PCIe交换机、PCIe交换机-网卡之间的反复穿梭,使得SerDes功耗占据网络系统近30%的电力,并带来难以优化的纳秒级物理延迟。
- 缓冲区拷贝瓶颈:每层协议都维护独立的内存缓冲区,数据在不同芯片间的拷贝操作导致严重的尾延迟。在万卡集群进行大规模参数同步时,这种延迟会导致整个集群因“等待数据”而空转,极大降低了有效计算周期。
- 物理拓扑冗余:传统的“烟囱式”结构需要大量独立芯片实现各层功能,不仅增加了系统复杂性和成本,更导致了PCB空间和散热资源的低效利用。
这些问题的本质在于,现有网络架构是基于协议分层和功能分离的传统理念设计的,未能适应AI计算对极致效率和低延迟的苛刻要求,这也是现代云原生与高性能计算基础设施共同面临的挑战。

架构革命:ACF-S的物理层收敛创新
Enfabrica的ACF-S芯片采用了一种颠覆性的设计哲学:在单颗硅片内实现协议原生融合,从物理层面消除数据迁移的摩擦力。
ACF-S芯片将8Tbps以太网MAC、PCIe Gen5控制器和CXL 2.0+逻辑原生集成在同一硅片上。这种高度集成的设计带来了根本性优势:
- 硅内互联取代片外通信:数据从PCIe通道进入后,无需经过PCB走线到达独立的网卡芯片,而是在ACF-S内部的总线层级直接完成协议转换。这种“物理层坍缩”节省了大量高功耗的SerDes模块,使每比特数据的传输功耗大幅降低。
- 零拷贝跨层访问:ACF-S支持以太网帧直接映射到CXL/PCIe地址空间,外部网络的远程数据可以“一步到位”直接写入GPU内存或CXL内存池,无需CPU干预或多级缓冲转发,从根本上消除了尾延迟问题。
- 统一交换架构:ACF-S充当通用数据移动器,在同一芯片上实现GPU、CPU、加速器和内存之间的多TB级别数据交换,消除了对多种独立交换和网络芯片的需求。
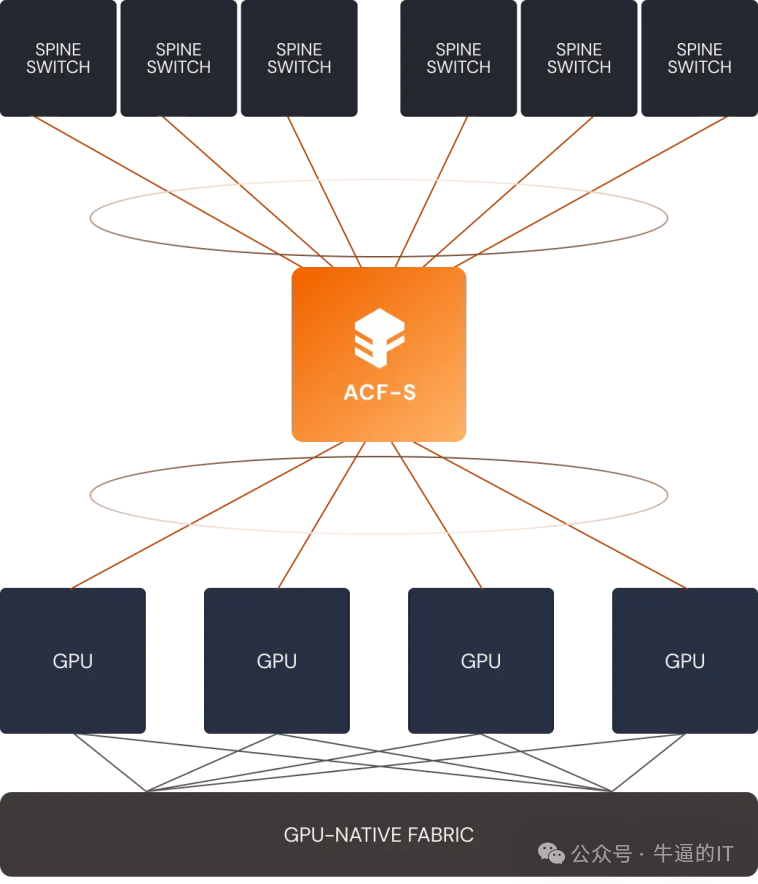
Enfabrica首席执行官Rochan Sankar指出:“这不是CXL架构,不是以太网交换机,也不是DPU——它可以做所有这些事情。我们解决的是数据在物理层移动的根本效率问题。”
性能突破:从“堆砌硬件”到“架构重构”
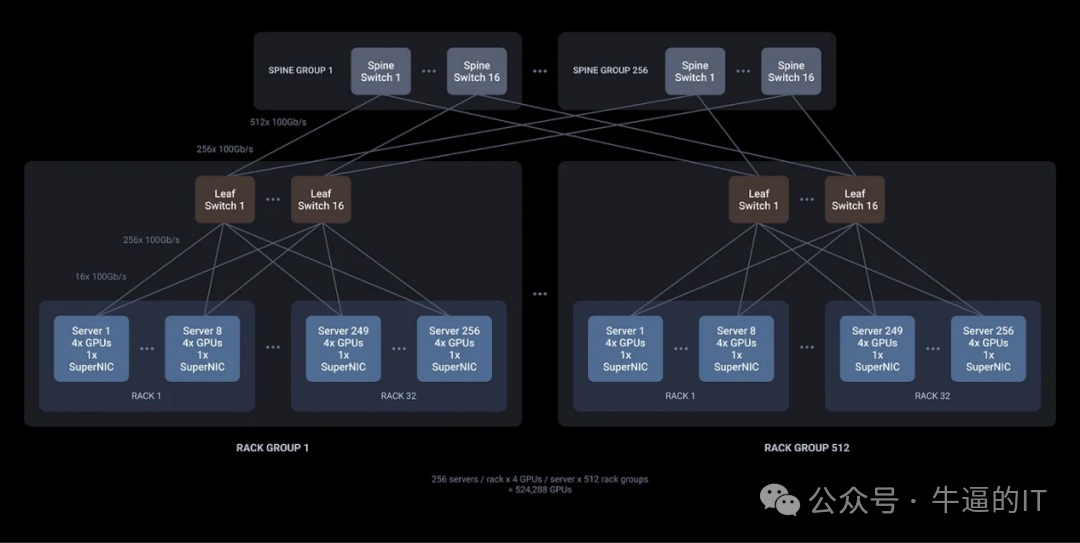
在2024年超级计算大会上,Enfabrica发布的3.2Tbps ACF SuperNIC芯片“Millennium”展现了架构创新的巨大潜力。该芯片支持32个网络端口和160个PCIe通道的高基数设计,首次实现仅需两层网络拓扑即可构建50万GPU集群。
与传统方案相比,Millennium的性能优势源于其物理层创新:
- 延迟降低一个数量级:通过消除协议转换和缓冲区拷贝,跨节点通信延迟接近本地PCIe通信水平,使大规模参数同步效率显著提升,这对于训练大型人工智能模型至关重要。
- 功耗效率大幅提升:SerDes模块的减少和整体架构的简化,使得单位比特数据的传输功耗降低约40%,为GPU留出更多电力预算。
- 算力密度显著增加:节省的PCB空间和功耗使单个机架能够容纳更多GPU,直接提升整体算力密度。
在实际应用场景中,这种架构革新转化为显著的成本效益。测试数据显示,ACF-S架构可使大型语言模型推理的GPU计算成本降低约50%,深度学习推荐模型推理成本降低75%。

内存访问革新:打破GPU内存墙
除了网络优化,ACF-S还通过CXL内存桥接技术解决了AI训练中的另一个关键瓶颈——内存容量限制。
传统GPU受限于高带宽内存容量,大规模模型训练需要频繁的数据交换。ACF-S的突破在于:
- 无头内存扩展:ACF-S可为任何加速器提供直接、低延迟的CXL DDR5 DRAM访问,内存容量是GPU原生HBM的50倍以上,极大缓解了内存墙问题。
- 统一内存空间:通过CXL协议,ACF-S实现了GPU与扩展内存之间的统一地址空间,使数据交换对软件透明,简化了编程模型。
- 弹性内存池:支持根据工作负载需求动态调整内存容量,提高资源利用率并降低总体拥有成本。
这种内存架构创新与网络优化相结合,使ACF-S能够为AI工作负载提供端到端的性能优化,从数据获取到计算完成形成完整的高效闭环。
生态布局:巨头的战略考量与行业未来
英伟达对Enfabrica的投资是一个深具象征意义的行业信号。尽管Enfabrica的技术可能对英伟达旗下的Mellanox解决方案构成竞争,但英伟达显然更看重其在下一代AI基础设施生态中的战略价值。
这一投资反映了AI计算市场正在经历的深刻变革:竞争焦点从单纯的GPU性能转向系统级效率。随着摩尔定律放缓,架构创新成为推动AI算力增长的关键动力。
超级以太网联盟的成立及其技术路线图与Enfabrica的高度契合,进一步验证了物理层收敛的技术方向。UEC倡导的加速器、网卡和交换机协同设计理念,正是Enfabrica技术的核心价值主张。

更为深远的影响可能体现在计算生态的多元化上。Enfabrica的技术通过高速数据移动能力,使CPU和其他加速器在AI工作负载中更具竞争力,这有助于打破当前GPU供应紧张和市场集中度高的局面。
Constellation Research副总裁Andy Thurai指出:“Enfabrica的独特优势在于它使用现有的接口、协议和软件堆栈,因此无需重新连接基础设施。这为计算生态的多元化打开了新可能。”
市场前景:200亿美元芯片市场的格局重构
根据650 Group预测,到2027年,数据中心高性能I/O芯片市场规模将超过200亿美元。这一增长不仅由AI算力需求驱动,更反映了数据中心架构正在发生的根本性范式转移。
Enfabrica代表的技术方向——物理层协议收敛——正在成为网络芯片设计的新范式。未来的成功芯片需要具备三大核心能力:
- 异构计算原生支持:能够无缝连接GPU、CPU、专用加速器等多元算力资源,消除协议鸿沟。
- 内存-网络协同设计:打破内存与网络的传统界限,实现数据在计算资源间的无缝流动。
- 软件定义硬件:在保持线速性能的同时提供足够的灵活性,适应快速演进的AI工作负载。
随着2025年Millennium芯片的批量供货,Enfabrica技术有望在超大规模数据中心率先落地。但其长期成功不仅取决于技术优势,更需要构建完整的软件生态和合作伙伴网络。
对于云计算厂商和超大规模数据中心运营商而言,Enfabrica技术提供了打破现有供应链依赖的战略选项。在AI基础设施竞争日益激烈的背景下,这种架构级创新可能成为决定市场格局的关键变量。
物理层协议的收敛不是简单的性能优化,而是对AI计算本质的重新思考。当有效计算周期成为最稀缺资源时,消除数据移动的“隐形税收”比提升峰值算力更有价值。
Enfabrica的创新表明,下一代AI基础设施的竞争正在从“堆砌硬件”转向“架构重构”。那些能够实现计算、网络和内存资源原子级整合的技术,将定义AI算力的未来格局。在摩尔定律放缓的时代,真正的突破将来自于对网络与系统架构的重新理解与设计,物理层协议的彻底收敛,正是这一趋势的集中体现。
 发表于 2025-12-24 03:43:16
|
查看: 239|
回复: 0
发表于 2025-12-24 03:43:16
|
查看: 239|
回复: 0
