关键词:大型语言模型、多 GPU 分布式执行、细粒度融合、三税分析框架、Triton、跨 GPU 通信

图1:相关研究论文《消除多GPU性能税:一种实现高效分布式大语言模型的系统方法》
本文针对分布式大语言模型在多GPU系统中普遍存在的性能瓶颈,提出了全新的分析框架与解决方案。
研究指出,传统批量同步并行模型所遵循的“计算-等待-通信-等待-计算”模式会带来三种系统性性能损耗,即“三税”:核函数启动开销税、批量同步税和核间数据局部性税。
为消除这些损耗,论文倡导突破BSP模型的限制,通过细粒度融合技术将通信逻辑直接嵌入计算内核。研究团队基于 AMD 开发的 Iris 库,利用其内建的远程内存访问原语,在 Triton 编程环境中实现了两种创新的融合模式:消费者驱动的“拉取”模型和生产者驱动的“推送”模型。这些模式能够构建瓦片级生产者-消费者流水线,以数据流同步替代全局屏障,从而显著重叠计算与通信。
实验评估表明,该方法在基础算子 All-Gather+GEMM 和前沿推理算法 Flash Decode 上均取得显著成效。相比传统 RCCL 基线,融合内核在多种负载规模下实现了10-20%的端到端延迟降低,并展现出良好的多GPU扩展性。
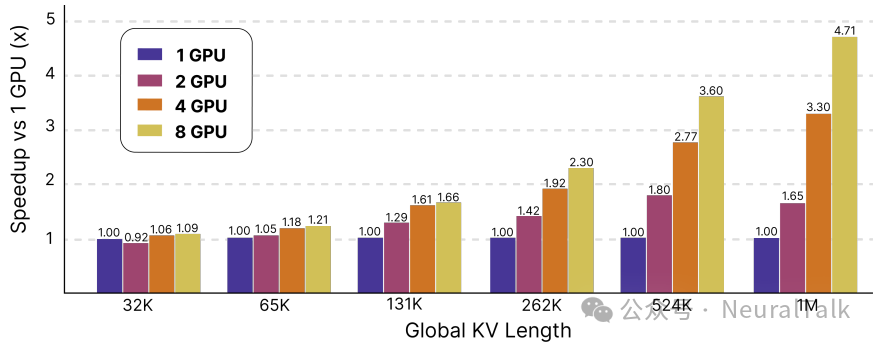
图2:融合Flash Decode内核在多GPU下的扩展性表现
这项工作不仅提供了一套具体的性能优化工具,更确立了一种更高效、更可编程的分布式AI计算新范式,为大规模模型的高效推理与训练奠定了系统基础。
一、多 GPU 协作的“隐形税”
传统的批量同步并行模型(Bulk Synchronous Parallel) 是一种并行计算的编程与执行模型,虽然易于编程,却引入了显著的性能损耗,这些损耗被研究人员形象地称为 “三种税”。
因为所有参与计算的处理器或节点,必须在完成当前超步的所有操作后,才能进入下一个超步,同步屏障(Barrier Synchronization) 是其核心特征。
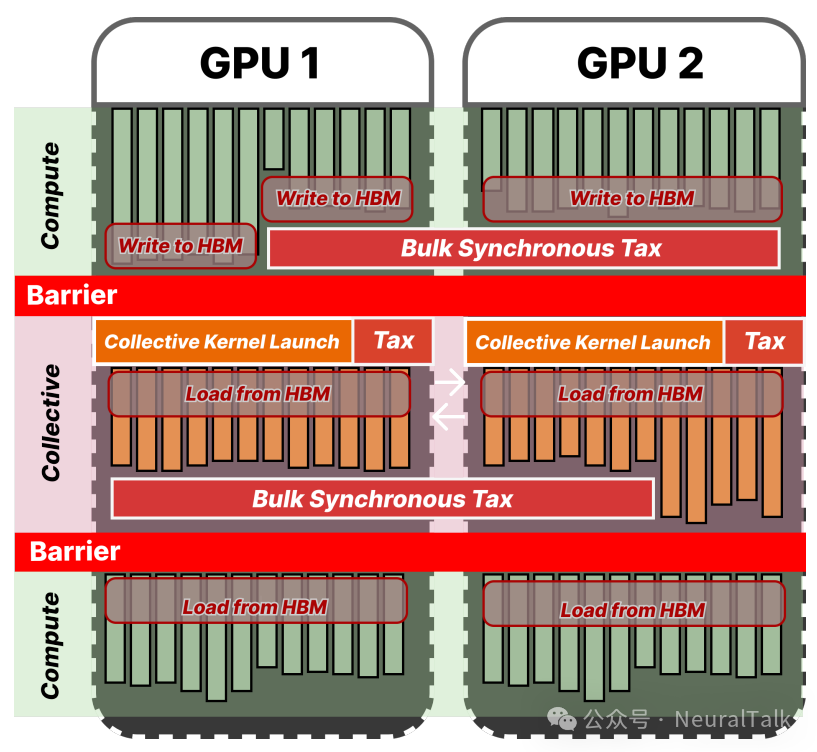
图3:BSP模型中的“三税”:核启动开销、强制同步等待、数据局部性破坏
- 第一种是核函数启动开销税。每一次计算或通信都需要通过主机端启动一个 GPU 核函数,频繁启动带来的固定延迟在短时任务中尤为明显。
- 第二种是批量同步税。在每一次全局同步点,速度快的 GPU 必须停下来等待最慢的那一个,这种强制等待造成了硬件资源的闲置,形成了执行流水线中的“气泡”。
- 第三种是核间数据局部性税。当生产者和消费者操作被分割到不同的核函数中时,中间数据不得不从高速的片上缓存写入慢速的高带宽内存,消费者又需要从 HBM 中重新读取,导致数据局部性被破坏。
这些“税”并非硬件本身的限制,而是编程模型强加的开销。如果能将通信和计算逻辑融合到同一个核函数中,让数据在 GPU 芯片内部直接流动,就能从根本上避免这些损耗。
二、融合模式:Pull 与 Push 的较量
为了验证细粒度融合的效果,研究团队选择了一个经典且重要的基础算子——All-Gather + GEMM作为测试对象。这是分布式模型中的常见模式,例如在张量并行中,需要先收集所有设备上的权重分片,再进行矩阵乘法。
他们实现了两种不同的细粒度融合策略:Pull 模型和Push 模型。
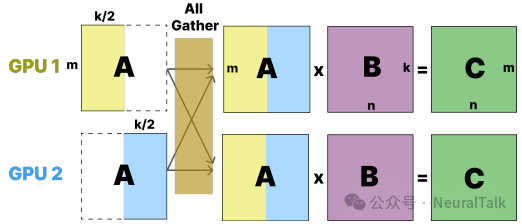
图4:分布式矩阵乘法中All-Gather操作的数据流
- Pull 模型是消费者驱动的:GEMM 核函数在需要数据时,主动从远程 GPU 加载所需的数据块。这通过将原本的本地加载操作
tl.load() 替换为支持远程访问的 iris.load() 来实现,通信与计算完全交织,无需显式同步。
- Push 模型则是生产者驱动的:一个专门的“推送”核函数先将本地的数据分片推送到所有远程 GPU 的收件箱,并更新同步标志;GEMM 核函数在计算前先轮询检查标志,数据就绪后再从本地收件箱加载。
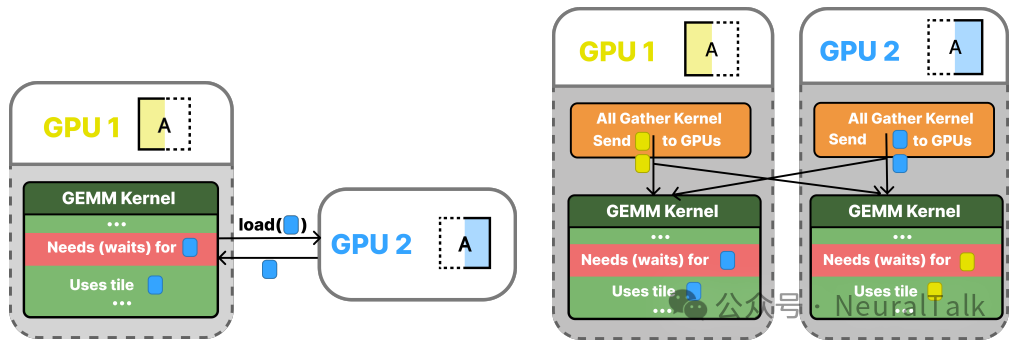
图5:Pull(消费者拉取)与Push(生产者推送)两种融合模式的对比
实验发现,对于小矩阵,Pull 模型更优,因为它彻底消除了独立的通信核启动开销。对于大矩阵,Push 模型则凭借其更高效的数据移动操作胜出,其初始启动开销被掩盖。
三、挑战复杂任务:Flash Decode 的优化之旅
为了证明方法的通用性,团队将这套思路应用到了一个复杂且实际的生产级算法——Flash Decode 上。这是当前 LLM 解码阶段的前沿算法,其多 GPU 版本天然包含 All-Gather 操作。
他们采取了循序渐进的优化路径:
- 独立 All-Gather 核:用 Iris 实现一个功能等价但透明的 All-Gather 核,替换掉黑盒的 RCCL 调用。这一步并未改变 BSP 模式,三税仍在。
- 细粒度等待:改造消费者核,使其不再一次性等待全部数据,而是为每个需要的数据块设置标志并轮询。这样,计算可以与尚未完成的通信重叠,初步缓解了同步税。
- 完全融合:彻底取消独立的 All-Gather 核,将数据推送逻辑直接融合进生产者核。一旦计算出结果的一个数据块,就立即推送给所有消费者。
至此,生产者-消费者管道在数据块级别建立,三种税被系统性地消除。
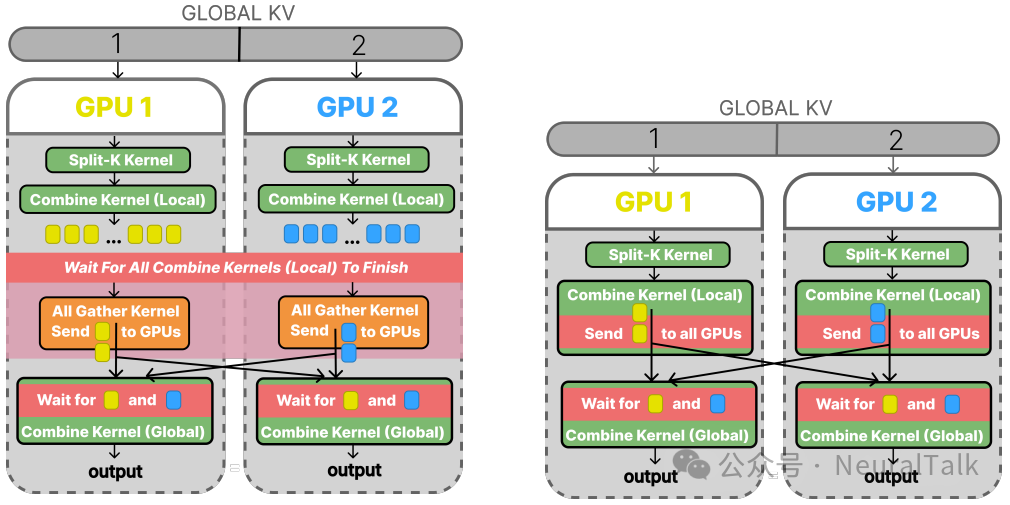
图6:Flash Decode优化路径:从细粒度等待(左)到完全融合(右)
四、性能收益:10-20%的端到端延迟降低
实验在 8 块 AMD MI300X GPU 上进行。
- 对于 All-Gather + GEMM,融合内核在大多数矩阵尺寸下都优于 RCCL+PyTorch 的基线。
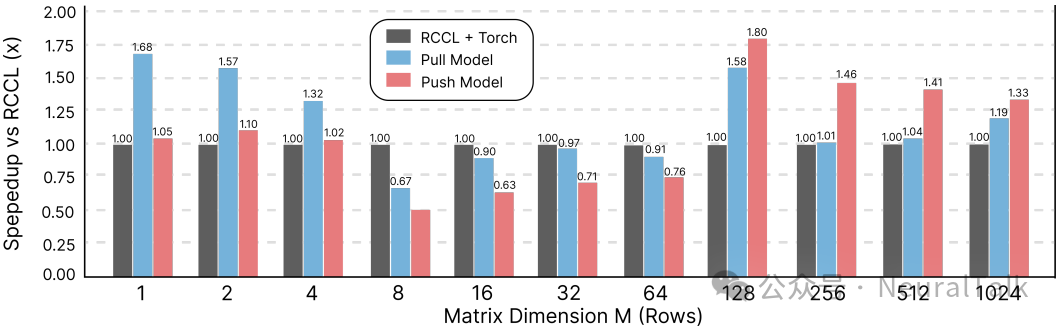
图7:All-Gather+GEMM算子在不同矩阵维度下的性能提升
- 对于Flash Decode,最终的融合内核实现在广泛的序列长度范围内,相比 RCCL 基线实现了10-20%的端到端延迟降低。
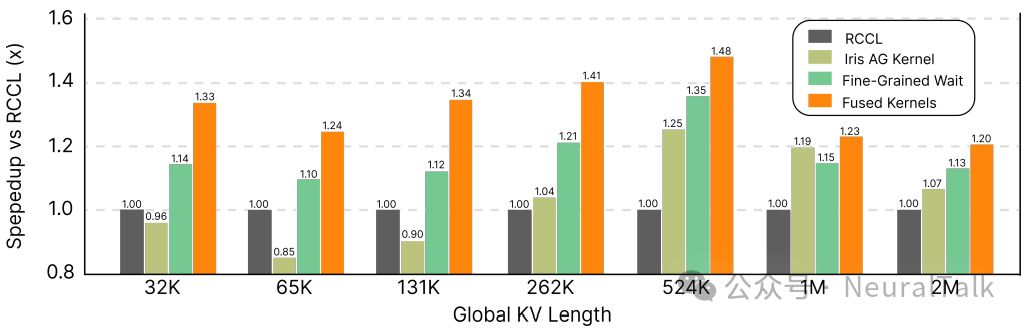
图8:Flash Decode算法逐步优化带来的性能收益累加
- 更值得关注的是可扩展性。随着 GPU 数量从 1 增加到 8,融合方法有效避免了严重的同步瓶颈,在长序列任务上执行时间大幅减少,证明了其支撑更大规模 LLM 推理的潜力。
五、可编程性与通用性:Iris 库的关键作用
这项工作的成功离不开Iris 库的支持。Iris 在 Triton 中无缝集成了类似 SHMEM 的远程内存访问原语,使多 GPU 编程成为 Triton 的一等公民。
其 API 设计非常巧妙,iris.load()和iris.store()函数签名与 Triton 原有的tl.load()/tl.store()高度一致。开发者只需将原本用于本地内存访问的函数替换为 Iris 的对应函数,并指定远程设备编号,就能将一个本地计算核轻松改造成支持细粒度通信的融合核。
这种设计大幅降低了编程复杂度,使得从 All-Gather+GEMM 到 Flash Decode 的模式复用成为可能。
这项技术不仅限于 All-Gather,其核心的“三税”分析框架可应用于任何遵循“计算-等待-集体通信-等待-计算”模式的算法。这意味着,在深度学习训练中常见的All-Reduce、Reduce-Scatter等操作,同样可以从中受益。
六、相关工作:现有技术的局限与突破
在细粒度融合通信与计算领域,已有一些相关工作,但各有局限:
Triton Distributed 是 OpenAI Triton 编译器的扩展,旨在解决多 GPU 场景下计算与通信的重叠问题。它提供基于块的编程原语,允许在计算逻辑中嵌入通信。然而,其设计存在显著不足:
- 编程复杂性高:直接暴露底层 C 风格 API 到 Python/Triton 代码中,需要开发者手动管理线程标识符和同步
- 运行时黑盒:缺乏对执行行为的深入控制和可观察性
- 内存模型不统一:继承了 OpenSHMEM 的无一致性内存模型,增加了分布式内核开发的复杂性
相比之下,Iris 提供了更优雅的解决方案:
- 高级抽象:提供 Pythonic 的 API 和统一的内存模型
- 易用性:无缝集成到 Triton 编程模型中,保持开发效率
- 灵活性:支持细粒度的计算-通信重叠,同时保持代码简洁
传统通信库如 RCCL 和 NCCL 虽然提供了高性能的集体操作实现,但它们遵循严格的 BSP 模型,将通信封装为黑盒操作,无法与计算逻辑深度融合,这正是“三税”问题的根源。
本工作的创新之处在于,不仅指出了 BSP 模型的性能问题,还通过 Iris 提供了一条可行的解决路径,在保持编程易用性的同时,实现了显著的性能提升。
七、未来:统一自动调优与更广阔的蓝图
融合通信与计算打开了一扇新的大门:统一自动调优。传统上,计算核的瓦片大小和通信的数据传输粒度是分开优化的。
现在,它们处于同一个核函数的作用域内,这使得扩展 Triton 现有的自动调优器成为可能,使其能在一个联合搜索空间中同时优化计算和通信参数,找到全局最优配置,从而最大化硬件利用率和延迟隐藏。
未来,这套细粒度融合模式将被应用到更广泛的 LLM 工作负载中,包括推理的其他关键阶段和各种训练核,最终目标是构建一个全面的高性能分布式原语库。
这项研究通过打破批量同步并行模型的桎梏,系统性揭示了性能损失的根源并提供了切实的解决方案。它不仅仅是一个针对特定算子的优化,更是一种新的分布式 AI 编程范式的开端。
当计算与通信的界限变得模糊,当数据流替代了全局屏障,GPU 集群才能真正像一个协调高效的“大脑”一样工作,而不是在无尽的等待中消耗宝贵的算力与时间。随着大模型规模的持续增长,这类系统层面的创新,将是释放其全部潜能的关键。
本文由 云栈社区 进行技术内容优化与分享。关注分布式系统与AI性能优化,获取更多深度技术解析。
 发表于 2025-12-30 06:29:59
|
查看: 272|
回复: 0
发表于 2025-12-30 06:29:59
|
查看: 272|
回复: 0
