2024 年 GPT-5 迟迟没有发布,社区里已经开始认真讨论一个问题:预训练是不是已经遇到瓶颈了?当算力堆不出新的数量级提升时,模型能力还能从哪里来?
就在这个时间点,OpenAI 的 o1 和 DeepSeek 的 R1 相继亮相,让大家把注意力转向了 test-time scaling——在推理阶段继续“用算力换效果”。这让我第一次非常明确地意识到:强化学习在大模型时代,可能还远没有走到尽头。
在老板的支持下,我们很快组建了一支小队:我 + 3 位北大的实习生,目标很明确——复现 o1 和 R1,并搞清楚它们真正 work 的地方在哪。
01 从复现开始,先解决“工具不趁手”的问题
复现的第一步,其实不是算法,而是工具。我们需要一套能跑得动、能对齐、能 debug 的 RL 框架。
是从零开发,还是直接基于现有开源工作?这个问题我想得很清楚:我已经做 RL 四年多,前两年也搭过上一家公司完整的 RL 数据飞轮系统,搭框架本身并不难,真正难的是:
- 讲清楚要解决什么问题?
- 和开源的框架相比,我们要做的系统独特性和优势在哪里?
我系统性地调研了当时几乎所有主流开源 RL 框架,其中影响力最大、工程完成度最高的,无疑是字节的 verl。坦率讲,verl 在 RL 训练效率上确实做得很好:rollout 阶段用 vLLM 做推理加速,训练支持 FSDP 和 Megatron,工程优化也非常激进。
但在深度使用之后,我们也遇到了几个绕不过去的痛点:
1. 通信架构问题
verl 使用 Ray 做通信,数据会通过网卡集中发往一个进程再转发。卡数和数据规模一上来,通信本身就成了系统瓶颈——这个问题后来我们在千卡集群上得到了验证。
2. 算法组件高度耦合
rollout、actor、reference 的逻辑全部写在同一个 ActorRolloutRefWorker 里,短期看方便,长期看几乎不可扩展,也很难支持灵活调度或分离式部署。
3. 正确性验证严重不足
早期 verl 留下了大量 bug 和坑没有填,时至今日还有。作为一个大厂项目,对系统正确性验证上做得这么差,从拉到夯我只能给评到 NPC(后面有机会单开一个帖子吐槽)。
所以结论其实很自然:如果我们真的想把 RL 当成长期能力建设,而不是一次性复现,那就必须有一套自己完全可控、经过严格验证的系统。 于是,从零搭建,成了最理性的选择。
02 3个月,Infini-RL的第一个版本
前期我们 4 个人,大概花了 3 个月,完成了 Infini-RL 的第一个可用版本。这个阶段我们刻意做了取舍:
- 只支持 SGLang 作为推理后端。
- 只支持 Megatron-LM 作为训练后端。
- 只实现 GRPO 一个算法。
但在系统设计上,我们从一开始就解决了现有开源框架的问题:
- 通信层:直接使用 NCCL + CUDA IPC 做数据和权重传输,避免不必要的中转。
- 算法解耦:每个算法组件都有独立类,负责各自的逻辑。
- 引擎抽象:训练 / 推理通过 hybrid engines 的 manager 统一接入。
- 核心算法函数(loss、advantage 等)全部集中在 algorithms 模块。
这样做的结果是:我们得到了一套 通信高效、组件可复用、调度和部署极其灵活 的 RL 系统雏形。
03 正确性验证:真正“劝退人”的3个月
如果说前 3 个月是兴奋期,那接下来的 正确性验证阶段,就是纯粹的折磨。一开始我们用的是 DeepScaleR 的 recipe,但到 2025 年 5 月,这套方案已经不再是最优。深入梳理 verl 之后,我们发现其中存在不少问题,即便修完,也很难保证完全对齐。
最后我们决定直接与 AReal 做严格对齐。 这里必须点名感谢 AReal 的大哥们,系统正确性上非常扎实靠谱!一开始我尝试端到端对齐,结果训练效果始终不稳定;最后被逼无奈,只能做 逐行级别的细粒度对齐。那段时间基本每天要开 3–4 个日会,对齐其他模块的开发进度,同时自己还在一点点抠细节。对齐 AReal 后,效果立竿见影,reward 曲线的稳定上涨给了我很大的信心。
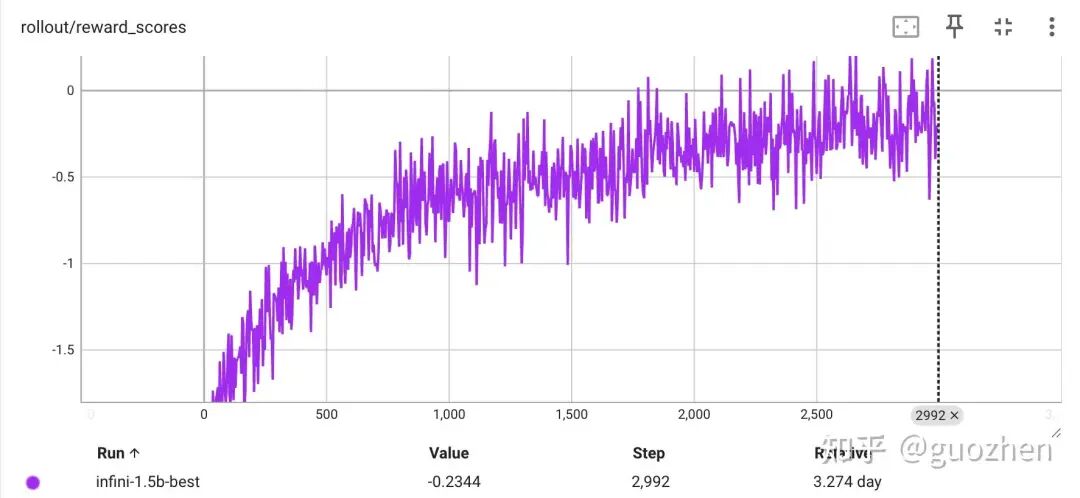
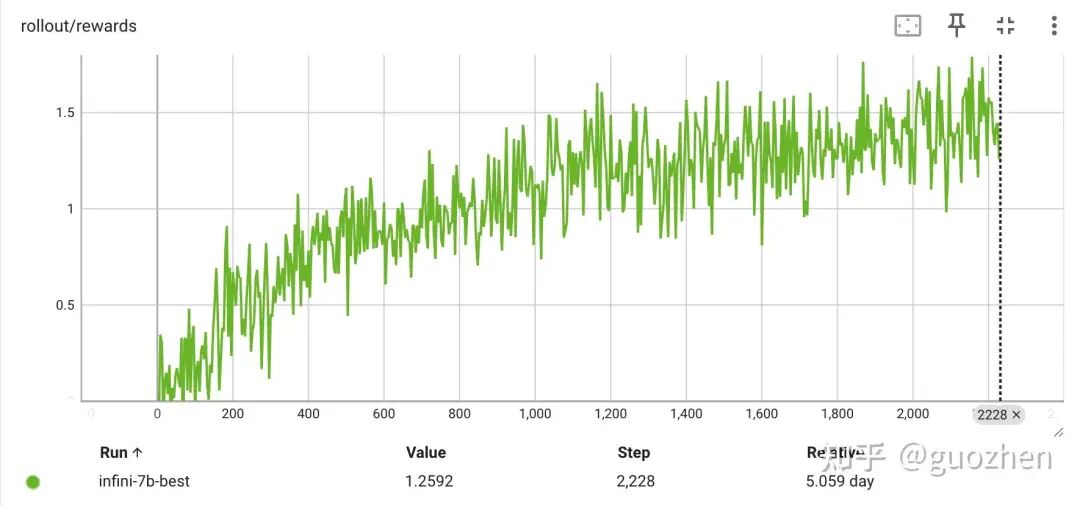
在这个基础上,我又加了一些 trick,做了一轮系统性的调参,最终我们用 Qwen 2.5 1.5B 和 7B,在 AIME 24、AIME 25、GPQA-Diamond 上的平均成绩都做到了 SOTA。
也是从这个阶段开始,越来越多同事加入了 RL 框架开发。特别是来自清华的大佬加入后,调度和通信模块被重构到一个非常夸张的水准——无论是编程接口、调度、部署还是扩展能力,都遥遥领先其他开源工作(这块真的值得单独吹一篇)。
04 把RL的scale能力,带到具身智能
在系统正确性基本站稳之后,我们迎来了最关键的一步——接入具身智能。年初定第一版方案时,我们就有幸和清华 于超老师 的课题组展开了深入合作。于老师团队在 RL 和具身领域积累非常深,这个过程中我自己也在快速补课、反思:一个面向具身的 RL 框架,和 LLM-RL 到底应该有什么本质不同?
思考这个问题的同时,也没有停着,我们首先从 VLA + 仿真环境 做起,把 RL 在 LLM 上的 scale 能力,尽可能迁移过来。
具身领域的训练范式和 LLM 稍有不同,表面上看有这么几点:
- 交互方式不同
- LLM:一次性 rollout,一条 prompt → 一段 token。
- 具身:模型与环境 多轮交互,每个 action 对应一个 observation。
- 数据形态不同
- LLM:token 序列,天然离散、统一。
- 具身:多模态 observation(视觉 / proprio / state),连续或混合 action。
- 接口碎片化
- 不同模拟器、不同 VLA 模型,几乎没有统一标准。
为了不把系统写死,我们为具身场景设计了统一的数据接口 + 多层组件封装,尽可能保证系统组件的可复用性,以及不同模型和环境接入的灵活性(这部分之后也值得单独展开)。
再往深层次看,具身相比于 LLM 面临的其实是学习信号极其稀疏的问题。
在完成一次比较彻底的重构之后,我们在 2025 年 8 月 19 日 正式开源了这套框架,并将其命名为 RLinf。
05 开源之后,事情开始“失控”了
开源后的几个月,是 RLinf 真正爆发的阶段。
1. 具身方向
截止 2025 年底,我们接入了:
- 7 种模拟器。
- 1 种真机机械臂。
- 5 种 VLA 模型。
- 7 种 RL 算法。
并在其中 4 个模拟器上训练出 SOTA 模型;v0.2 pre 已支持真机训练并展示 demo;系统性能相比同类工作 快 1.434×。
2. Agent 方向
- 10 月开源了第一个代码补全的 online RL agent。
- 年底合入了 Search-R1 agent 复现,相比其他框架 提速 55%。
3. 系统层面
- 支持多训练 / 推理后端。
- 支持自动调度与动态调度。
最后我们在 12 月正式 release 了 RLinf v0.1。
06 写在最后
回顾 2025 年,绝对是打好基础的一年。算法、系统、具身、agent,看起来方向很多,但底层逻辑其实是一致的:把强化学习从“一次性实验”变成可持续放大的能力。
2026 年,我更期待继续去探索 RLinf 系统的边界——更快、更稳、更可验证、更值得被长期使用,更具有开创性和引领性。关于强化学习与开源系统的更多深度讨论,欢迎在 云栈社区 交流分享。
 发表于 2026-1-5 23:57:32
|
查看: 286|
回复: 0
发表于 2026-1-5 23:57:32
|
查看: 286|
回复: 0
