在 AI 驱动的内容分发时代,爱奇艺的业务逻辑已从“看过去”向“知未来”演进。无论是剧集热度的实时预判、广告效果的秒级反馈,还是会员运营的精准触达,都对数据时效性提出了严苛要求。然而,其传统大数据架构存在明显瓶颈:
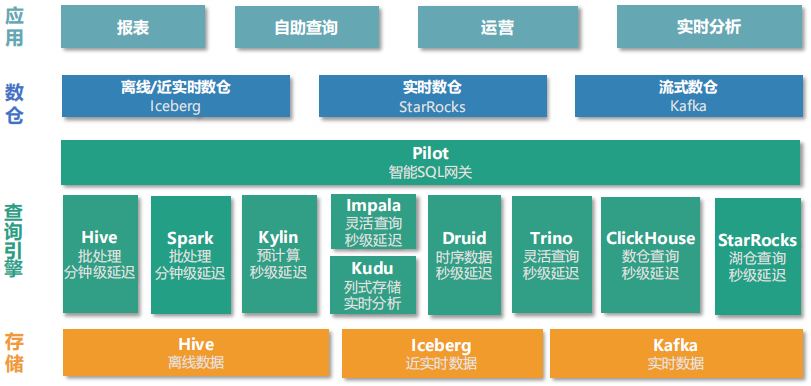
- 离线链路(Hive/Spark):T+1 或小时级延迟,无法满足实时场景。
- 实时链路(Kafka + ClickHouse/Druid):架构复杂,多套系统并存导致数据孤岛、运维成本高、查询体验割裂。
- 近实时探索(Trino on Iceberg):虽灵活但性能不足,难以支撑高并发、低延迟的运营报表。
面对这些挑战,爱奇艺亟需一个统一、极速、高并发的分析引擎。StarRocks 凭借其全面向量化引擎、CBO 优化器、实时更新模型及对开放数据湖的原生支持,成为其构建“流式数仓”的理想核心。
一、核心应用场景:StarRocks 在爱奇艺的价值落地
爱奇艺的实践聚焦于高价值、高时效性要求的核心场景:
-
实时运营与报表:
- 痛点:传统 BI 报表依赖 T+1 离线数据,无法指导当日运营动作。
- 方案:通过 Flink 消费 Kafka 实时日志,写入 StarRocks。运营人员可随时查看分钟级甚至秒级的用户活跃、内容播放、活动参与等核心指标,实现“所见即所得”的敏捷决策。
-
自助查询与数据探寻:
- 痛点:分析师使用 Trino 查询 Iceberg 近实时数据,常因性能问题(分钟级响应)而中断分析思路。
- 方案:将 StarRocks 作为统一的自助查询网关。分析师可直接对 StarRocks 内表或通过 External Catalog 查询湖上数据,获得秒级响应,极大提升数据探寻效率。
-
构建数据产品底座:
- 痛点:搜索、推荐、广告等数据产品需要低延迟、高可靠的特征和指标服务。
- 方案:StarRocks 为上游数据产品提供稳定、快速的数据 API 服务,支撑实时个性化体验,承担了关键的数据服务底座角色。
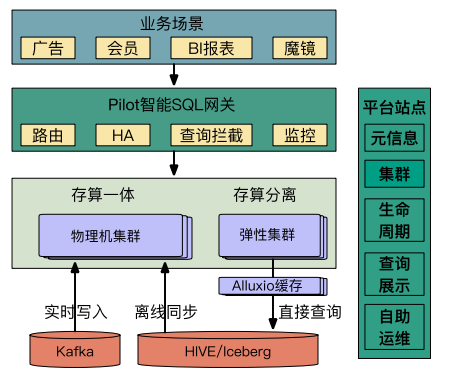
二、实践步骤:从 Pilot 到全量的架构演进
爱奇艺的落地遵循了稳健的演进路径:
阶段一:Pilot 验证 —— OLAP 数据库模式
- 目标:验证 StarRocks 在核心报表场景的性能与稳定性。
- 架构:通过
StreamLoad(小表)和 SparkLoad(大表)将 Hive 离线数据批量导入 StarRocks 内部表。
- 成果:平均查询耗时从 20 秒降至 1.5 秒,性能提升超 10 倍,初步验证了技术可行性。
阶段二:架构升级 —— 流式数仓模式
- 目标:解决数据导入滞后性问题,打通实时数据链路。
- 架构:
- 实时接入:Flink 作业消费 Kafka 中的实时事件流,通过
Routine Load 直接写入 StarRocks。
- 统一查询:构建 “流式数仓”,StarRocks 成为实时与准实时数据的唯一查询入口。
- 冷热分离:历史冷数据下沉至 Iceberg/Hive,通过 StarRocks 的 External Catalog 能力进行联邦查询,实现“仓湖融合”。
阶段三:湖仓一体 —— Lakehouse 新范式
- 目标:进一步简化架构,大幅降低人工 ETL 开发与维护成本。
- 架构:全面拥抱 StarRocks Lakehouse 能力。对于无需极致性能的场景,直接通过 Hive/Iceberg Catalog 查询湖上数据;对于高性能要求场景,则利用 物化视图 自动将湖上数据加工并同步至内表,实现透明加速。
三、关键优化与避坑指南:来自一线的实战经验
爱奇艺的实践沉淀了诸多宝贵的优化与避坑经验:
-
避坑 1:盲目追求“湖上直查”
经验:虽然 StarRocks 支持 External Catalog,但远端 I/O 和文件格式未优化会导致性能不如内表。
策略:对高频、低延迟要求的查询,务必使用物化视图将数据同步至内表;对低频、探查类查询,再考虑湖上直查。
-
避坑 2:忽略数据模型设计
经验:StarRocks 的高性能依赖于合理的数据模型(如 Aggregate Key, Unique Key)。
策略:针对不同场景(聚合、明细、更新)选择正确的模型,并精心设计分区(Partition)和分桶(Bucket)策略,以最大化 Colocate Join 和向量化执行的优势。
-
优化 1:物化视图的威力
经验:物化视图是爱奇艺实现“湖仓加速”的核心。它不仅支持自动刷新,还能进行透明查询改写,让业务 SQL 无感地命中预计算结果。针对 16 亿行数据的聚合查询,耗时被缩短至 2.5 秒以内,性能提升 30-40 倍。
-
优化 2:Data Cache 提升湖上性能
经验:通过开启 Data Cache 功能,将远端 OSS/S3 上的热数据缓存至 BE 节点本地,可显著减少网络 I/O。
注:该优化效果在其他企业的实践中得到验证——开启 Data Cache 后,StarRocks 对 Hive 的查询性能可达 Trino 的 7.4 倍,进一步佐证其普适价值。
四、未来展望:走向统一的 Lakehouse 架构
爱奇艺的实践清晰地指向了一个未来:Lakehouse 是终极形态。
- 存算分离:进一步解耦计算与存储,利用云原生存储降低成本,同时通过计算节点弹性伸缩应对业务高峰,这正契合了云原生架构的发展趋势。
- 开放生态:StarRocks 将更深度地融入大数据生态,不仅作为查询引擎,还将支持与 Spark/Flink 的双向数据互通,成为真正的“湖仓枢纽”。
- AI Native:随着 AI 应用的普及,StarRocks 正在探索对向量检索、ML 推理等能力的支持,使其不仅能“知未来”,更能“创未来”。
结语
爱奇艺的案例证明,从“分钟级”到“秒级”的跨越,并非仅仅依靠一个新引擎的引入,而是一场涉及架构理念、技术选型、工程实践的系统性变革。StarRocks 以其“极速统一”的核心价值,成功帮助爱奇艺弥合了离线与实时之间的鸿沟,构建了真正服务于“知未来”业务目标的数据基础设施。对于所有正走在实时化、智能化道路上的企业而言,爱奇艺的经验无疑是一份极具参考价值的行动指南。
想了解更多关于数据驱动与架构演进的深度讨论?欢迎访问云栈社区,与更多技术同行交流心得。 |  发表于 2026-1-10 18:45:24
|
查看: 242|
回复: 0
发表于 2026-1-10 18:45:24
|
查看: 242|
回复: 0
