在前20篇中我们对PCIe的基本知识做了一些梳理,有了一个大体的了解。接下来的章节我们来到硬件工程师的基本盘:PCIe物理层,抽丝剥茧,揭开物理层神秘的面纱。
这一篇我们将了解PCIe Gen6新引入的FLIT mode。PCIe Gen6(第六代)是 PCI Express 标准的一个重大飞跃,其最核心的变化之一就是引入了 FLIT(Flow Control Unit,流控制单元)模式。在 PCIe Gen6 之前(Gen1 到 Gen5),数据传输是基于变长数据包的;而从 Gen6 开始,为了配合 PAM4 信号 和 FEC(前向纠错),引入了固定大小的 FLIT 模式。
一、为什么在PCIe Gen6中要引入FLIT mode?
2021 年发布的 PCIe 6.0 规范将性能翻倍,传输速率提升至 64GT/s,采用 PAM4(四电平脉冲幅度调制)调制,并使用 FLIT(流控制单元)作为通信单位以提高效率。
在 PCIe 6.0 的众多新特性和变化中,我们将在此章节重点讨论一个重要的新特性:FLIT。
1. 效率提升
在之前的版本中,事务的大小长度是可变的,被称为传输层包(TLP)。它们可能具有固定的头部大小,但数据有效载荷的长度各不相同。无论 TLP 的长度如何,它都由 32 位循环冗余校验(CRC)进行保护,即使只有一个DWord的数据负载。这就造成了在协议层面的极大浪费。
图二是用PCIe Analyzer捕获的PCIe trace,图中的这个TLP只含有一个DWord的payload data,然而Message ID, Requester ID和 LCRC也分别占用一个DWord。因此造成极大的浪费。
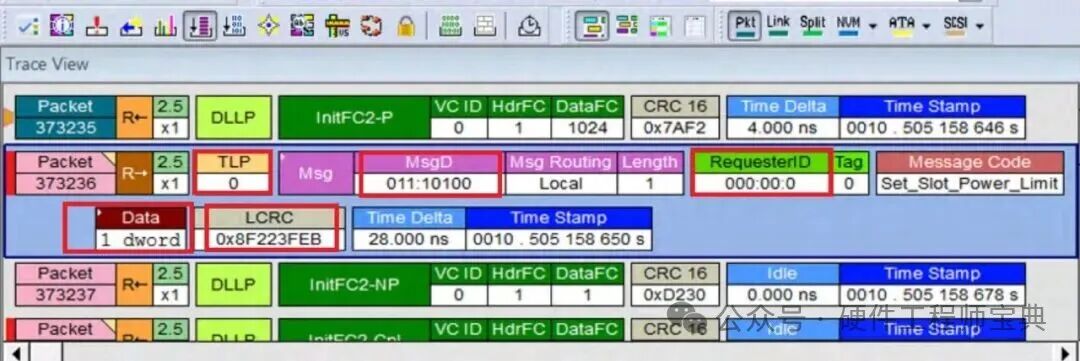
图二. PCIe Trace的组成
2. PAM4 信号
PCIe Gen6 将速率翻倍至 64 GT/s,由于物理限制,不再使用传统的 NRZ(非归零)信号,而是改用 PAM4。PAM4 可以在一个时钟周期内传输 2 位信息,但其信噪比更低,误码率(BER)显著升高。
在 PCIe 6.0 中,PAM4 的额外信号状态导致其信号比 NRZ 更脆弱。
3. FEC(前向纠错)
为了修正 PAM4 带来的高误码率,必须引入 FEC。FEC 算法在处理固定大小的数据块时效率最高且延迟最低。
新的调制方式需要前向纠错(FEC)来补偿 PAM4 更高的误码率,而纠错需要在固定大小的数据包上进行操作,因此 PCIe 6.0 采用了流控制单元(FLIT)。
二、在 PCIe 6.0 中,FLIT 是什么?
FLIT 固定长度为 256 字节,其中包括 236 字节的传输层包(TLP)、6 字节的数据链路包(DLP)、8 字节的循环冗余校验(CRC)和 6 字节的前向纠错(FEC)。如图一所示。它去除了 1b/1b 编码中的同步头、帧令牌等。FLIT 还具有类似的序列号概念,其中 DLP 的前 2 字节携带专门用于 FLIT 级别序列号、确认/否定确认(Ack/Nak)、重试机制等的信息。如图三所示。

图三. FLIT数据包的结构。
在 PCIe Gen6 中,一个标准的 FLIT 大小固定为 256 字节。其内部结构精确划分如下:
| 组成部分 |
大小 |
说明 |
| TLP (Transaction Layer Packets) |
236 Bytes |
包含实际的事务层数据(如读写请求)。 |
| DLP (Data Link Layer Packets) |
6 Bytes |
包含链路管理信息,如 Ack/Nak、序列号、流量控制等。 |
| CRC (Cyclic Redundancy Check) |
8 Bytes |
强大的 64 位循环冗余校验,用于检测 TLP 和 DLP 中的错误。 |
| FEC (Forward Error Correction) |
6 Bytes |
前向纠错码。采用 3 路交织设计,可纠正单字节错误。 |
| 总计 |
256 Bytes |
固定长度 |
前向纠错(FEC)的设计会随着要纠正的符号数量增加而导致延迟和复杂度呈指数级增长。6 字节的 FEC 负责 3 个交织组,每个组有 2 个 FEC 字节。这是为了防止突发错误,如果小于 3 字节的话。
在链路训练、轮询和配置的初始阶段,通过在 TS1 的“数据速率标识符”字段中的“FLIT 模式支持”位,启用 FLIT 机制并进行协商。一旦协商完成,它将适用于所有数据速率,这意味着 FLIT 也支持 8b/10b 和 128b/130b(混合模式)。
在 FLIT 模式下,我们正在使用一种全新的 TLP 头部格式。之前的 TLP 头部存在诸多限制,比如没有空间来增加标签大小。PCI-SIG 重新设计了头部以适应 FLIT 模式。挑战在于测试所有新的组合。
TLP 头由 3 至 7 个双字节的 TLP 头基组成,其后可跟 0 至 7 个双字节的 OHC(正交头内容)。
这种新型字段具有完全解码的 8 位包类型字段。这意味着所有 256 种类型值都被定义或预留给了特定的组,以实现正确的帧定界和转发。
此外,还为 FLIT 模式设计了新的完成规则。非定序 TLP 的完成也有重大更新,包括 14 位标签、使用 OHC-A5 进行错误报告等。
三、256字节FLIT数据流的Layout布局
一个256字节的FLIT数据如果在一个Lane上传输,那么一次排开,很容易理解;如果在x8或x16通道上传输,这256字节是怎么分布和布局的呢?
数据的传输以一个字节为单位,一个字节我们认为是一个Symbol。256字节在同一个Lane上传输,总共 256 bytes x 8 = 2048 bits。如图四所示。
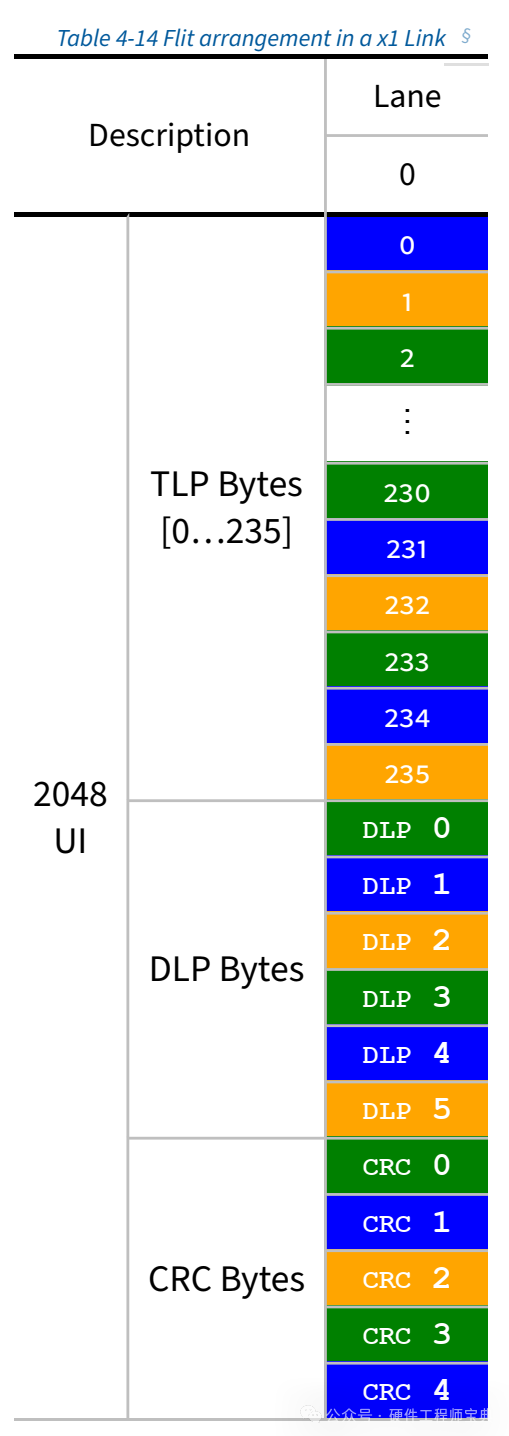
图四. 一个FLIT的256Byte在x1 Lane上的分布
当在x16通道下传输时,Symbol的分布采用Interleave交织模式,在0~15个Lane上一次分配Symbol,直至全部256个Symbol分配完毕。如图五所示。这样Symbol 0、16、32、48将被分配到Lane 0上,以此类推。每个Lane上分配了16个Symbol,共128个bits。
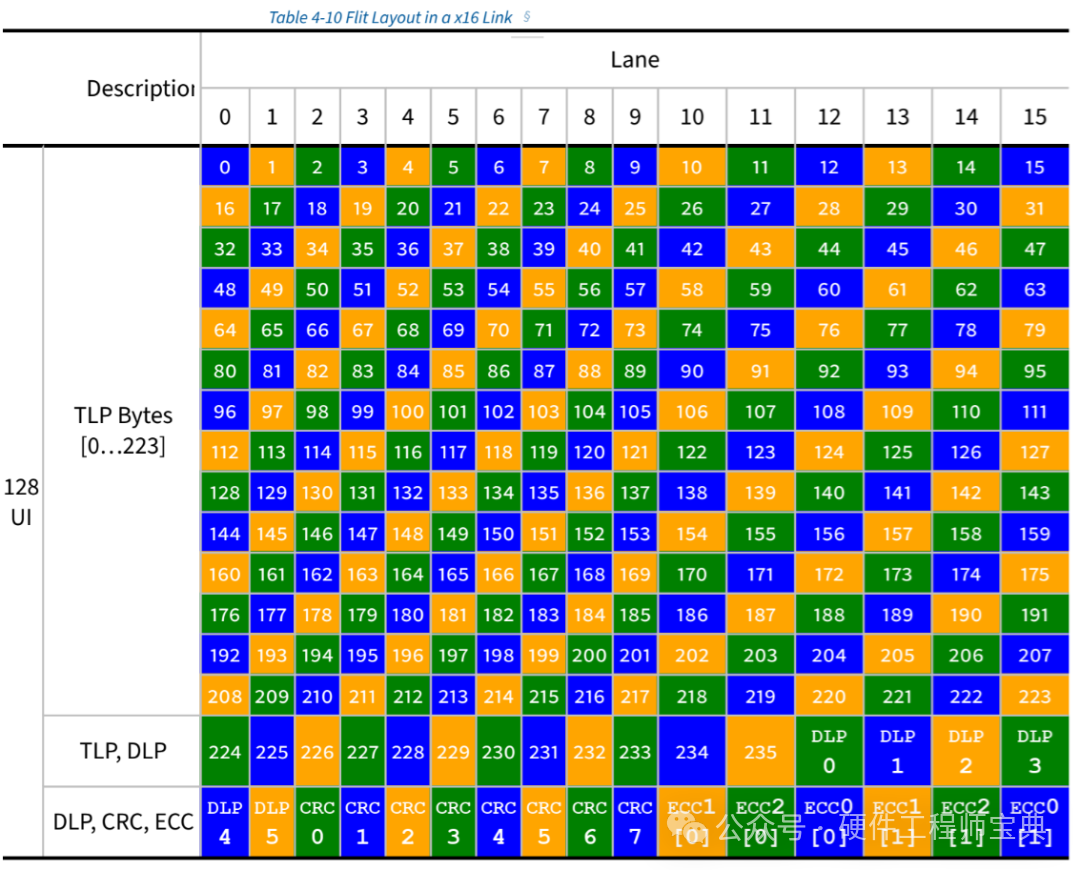
图五. 一个FLIT的256Byte在x16 Lane上的分布
四、FLIT 模式的关键特性
1. 1b/1b 编码(零开销编码)
在 FLIT 模式下,PCIe 彻底放弃了之前的 128b/130b 编码,转而使用 1b/1b 编码。这意味着物理层不再添加额外的同步位,256 字节的数据直接映射到物理通道上,传输效率接近 100%。
2. 极低延迟的 FEC
PCIe 是一种对延迟极其敏感的协议。Gen6 采用的是一种“轻量级”FEC,其增加的延迟小于 2ns。它与 CRC 配合工作:FEC 负责纠正大部分常见错误,而 CRC 负责检测 FEC 无法纠正的错误。
3. FLIT 级重传
在旧版本中,如果 TLP 损坏,需要重传整个 TLP(可能很大)。在 FLIT 模式下,重传是以 FLIT 为单位进行的。由于 FLIT 大小固定且较小,重传效率更高,对带宽的影响更小。
4. 简化的分帧
由于 FLIT 是固定长度的,接收端不再需要通过寻找特殊的“开始”和“结束”符号来定位数据包。接收端只需每隔 256 字节处理一次即可,这极大地简化了控制器逻辑并降低了功耗。
5. 低功耗状态 L0p
FLIT 模式引入了新的低功耗状态 L0p。它允许链路在流量负载较低时关闭部分通道,而无需重新训练链路。这种动态带宽调节功能仅在 FLIT 模式下有效。
6. 兼容性与协商
- 强制性: 当 PCIe 链路运行在 64 GT/s(Gen6 速率)时,必须使用 FLIT 模式。
- 向下兼容: 虽然 FLIT 模式是为 Gen6 设计的,但它也支持在较低速率下运行。如果链路两端都支持 FLIT 模式,它们可以在链路训练阶段协商进入“FLIT Mode”,即使在 32 GT/s 下也能享受 FLIT 带来的高效率。
五、总结
PCIe Gen6 的 FLIT 模式是底层传输架构的一次革命。它将固定长度、1b/1b 编码、轻量级 FEC 和强力 循环冗余校验 结合在一起,解决了 PAM4 信号带来的可靠性挑战,同时在不增加延迟的前提下,将有效带宽提升到了前所未有的水平。
在下一章中,我们将继续深入 PCIe 物理层,介绍 PCIe 链路增益均衡(Equalization)技术。
本文旨在技术探讨,欢迎在云栈社区交流更多关于PCIe和硬件设计的见解。
 发表于 2026-1-18 00:15:47
|
查看: 344|
回复: 0
发表于 2026-1-18 00:15:47
|
查看: 344|
回复: 0
