在工业质检场景中,部署在产线的轻量级检测模型常常因语义理解能力不足而误判,而具备强大理解能力的多模态大语言模型又因计算开销过大而难以实时部署。传统边缘-云协作方案则受限于静态、僵化的任务调度,难以应对异构设备与动态网络环境的挑战。
近期,来自中国科学院的研究团队提出了一种名为AIVD的自适应边云协同框架。该框架通过精巧的三层流水线设计、视觉-语义协同增强策略、高效的LoRA微调方法以及异构资源感知的动态调度算法,旨在实现工业视觉检测中高精度与高效率的平衡。

核心痛点:工业检测中精度与效率的失衡
在高速产线上,每分钟可能需要对上百块PCB板进行实时检测,每个缺陷可能只有微米级。轻量级模型(如YOLO)速度虽快,但面对视觉相似、语义不同的缺陷(如“焊锡桥接”与“焊锡不足”)时,往往因缺乏深层理解而“犯迷糊”,误报率高。
若转而使用多模态大语言模型,其强大的语义理解能力虽能生成精确的缺陷描述,但推理延迟可能飙升十倍以上,GPU内存需求巨大,完全打乱产线节奏。这便是当前工业视觉检测的双重困境:
- 轻量模型:速度快但“语义盲”,仅能输出类别标签。
- 大模型:理解强但“行动慢”,计算开销大,难以实时部署。
传统“边缘-云”方案常采用静态调度,在设备性能与网络条件各异的真实环境中,极易导致资源利用不均——强节点“饿死”,弱节点“撑爆”,整体吞吐量与延迟表现不稳定。
问题的根源在于视觉与语义的割裂以及资源的僵化调度。要系统性地解决这些问题,需要一个全局的协同设计视角。下图揭示了AIVD框架如何通过三层协同机制来应对这些挑战。
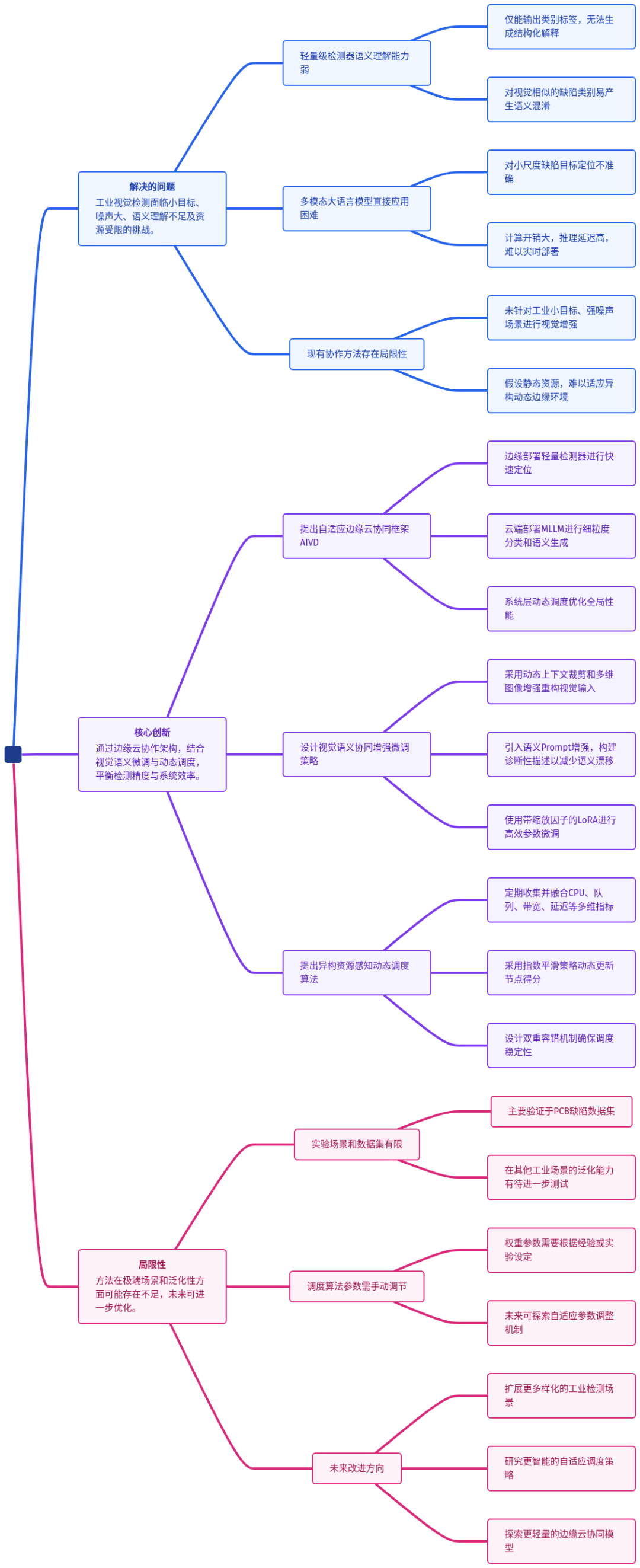
原理拆解:AIVD的三层协同艺术
三层流水线:各司其职,效率倍增
AIVD并未将任务简单分配给边缘或云端,而是设计了一个分工明确的三层流水线。
-
第一层:边缘高频定位
- 角色:多个异构边缘节点(如产线相机、工控机)。
- 任务:运行轻量级检测器(如YOLO),进行快速、低成本的缺陷定位。
- 输出:一组候选边界框,指示“哪里可能有缺陷”。
- 优势:计算量小、延迟低,适用于高频扫描。
-
第二层:云端深度理解
- 角色:云端服务器,部署多模态大语言模型。
- 任务:接收边缘上传的裁剪后缺陷区域,进行细粒度分类与结构化语义生成。
- 输出:不仅给出缺陷类别,还生成“为什么是这个缺陷”的可解释描述。
- 优势:语义能力强,能区分视觉相似的细微缺陷。
-
第三层:系统动态调度
- 角色:统一的任务管理与监控服务。
- 任务:实时监测各边缘节点的资源状态(CPU、内存、带宽、延迟),并动态分配检测任务。
- 输出:最优任务分配决策,确保全局吞吐量最大、延迟最低。
- 优势:自适应异构环境与动态负载,实现负载均衡。
这种设计类似于高效工厂:边缘是流水线工人快速初筛,云端是质检专家深度分析,调度系统则是生产主管灵活派活。
视觉-语义协同增强:让MLLM“看得清、说得准”
直接让MLLM处理整张图像中的微小缺陷效率低下,而简单裁剪又会丢失上下文导致语义漂移。AIVD创新性地从视觉和语义两个维度进行协同增强。
-
视觉增强:动态上下文裁剪
根据缺陷尺度智能扩展裁剪区域,为小缺陷补充关键上下文,为大缺陷保留细节。扩展核根据缺陷尺度和模型感受野动态调整。
-
视觉增强:多维扰动模拟
在HSV色彩空间中,通过组合增强算子模拟工业环境中常见的光照、对比度、饱和度变化,让模型在训练阶段就“见多识广”,提升鲁棒性。
-
语义增强:诊断性Prompt
为每个缺陷样本构建包含类别和缺陷机制描述的Prompt(例如:“焊锡桥接:由于焊锡过量或焊盘间距过小,导致相邻焊点之间形成非预期的导电连接,可能引起短路。”)。这不仅能隐式地进行语义聚类,还能强化相似类别间的语义边界。
高效微调:LoRA的智慧改造
为了高效微调百亿参数的MLLM,AIVD采用改进的LoRA(低秩自适应)技术。在传统LoRA公式 W' = W + BA 的基础上,引入了缩放因子s,使更新更可控:W' = W + s·BA。
- 缩放因子s:如同“油门控制器”,训练初期可设小值让模型平稳适应,后期增大以加速收敛。
- 零初始化策略:将
B初始化为零,确保训练开始时W' = W,模型行为与预训练模型一致,避免初期不稳定。
- 正则化项:约束低秩空间的学习,防止过拟合。
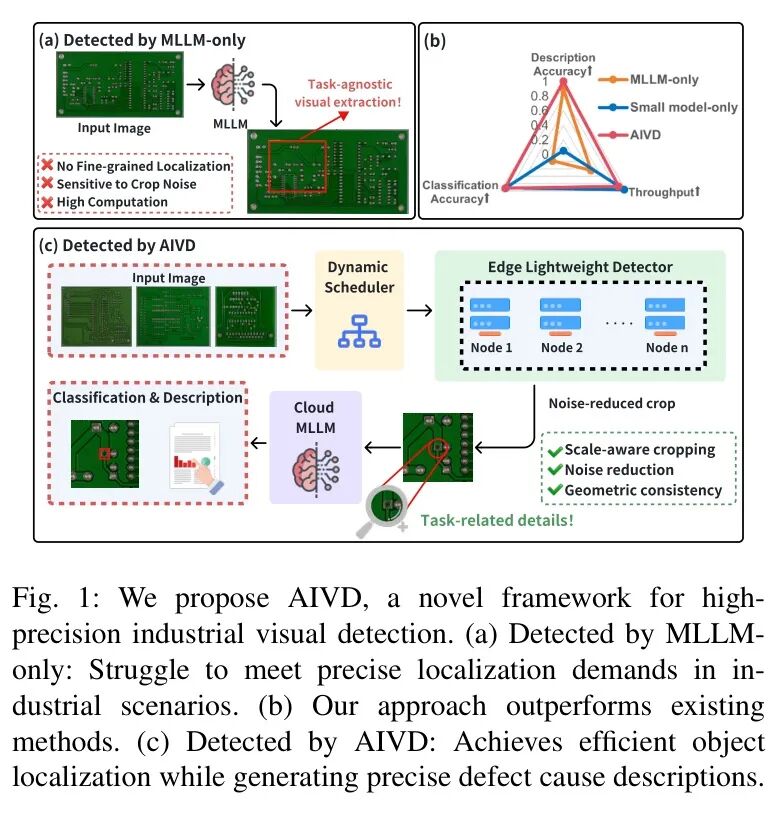
微调效果验证
如表1所示,在DeepPCB和HriPCB数据集上,AIVD提出的视觉-语义协同增强策略,在Qwen2-VL-7B、LLaVA1.6-mistral和InternVL3.5等多个MLLM上均取得了最优性能。例如,它将Qwen2-VL-7B在DeepPCB数据集上的准确率从0.712显著提升至0.847。
异构资源感知调度:动态平衡的艺术
在设备性能参差不齐的真实工厂中,固定调度策略必然失败。AIVD的调度算法核心是多指标融合与动态平滑。
- 资源状态监控:每个边缘节点
i定期上报四个归一化指标:CPU空闲率U_i、队列拥塞得分Q_i、可用带宽B_i、网络延迟L_i,形成资源向量R_i。
- 多指标融合评分:采用加权综合评分
score_i = αU_i + βQ_i + δB_i + εL_i。权重α, β, δ, ε可根据业务需求(如更看重实时性或带宽)灵活调整。
- 指数平滑更新:为避免瞬时波动影响,使用指数平滑更新节点得分
S_i,为其增加“惯性”。
- 容错保护:当节点过载时,自适应降低其得分
S_i,并设置得分下限确保其不会永久“掉线”,待恢复后可快速重新参与调度。

实验验证:数据驱动的性能展示
系统调度性能:吞吐量与延迟的显著优化
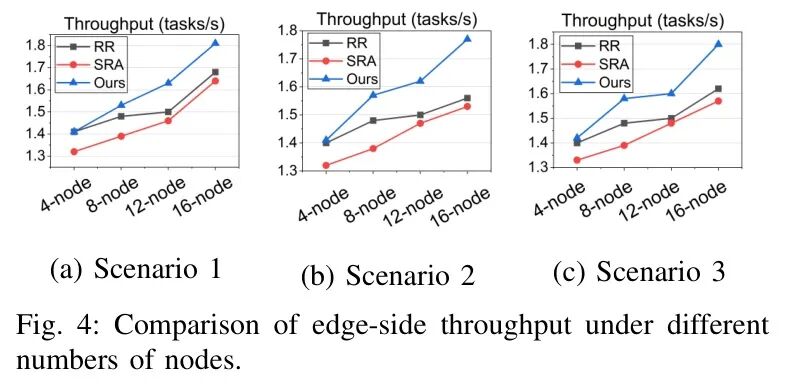
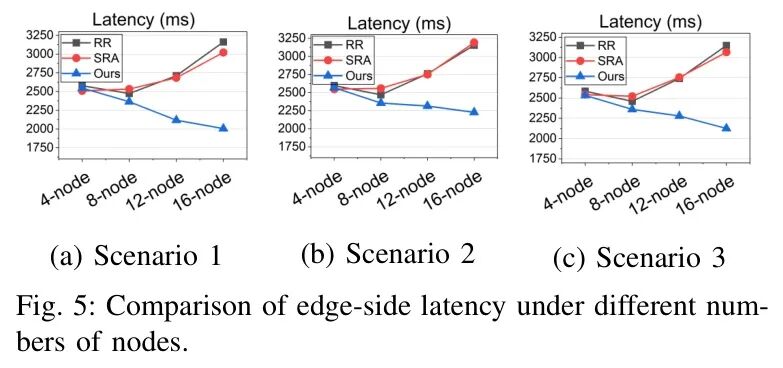
研究团队构建了包含4-16个异构节点的真实边缘环境,并设置了从正常到极端的三个测试场景。对比轮询(RR)、静态资源感知(SRA)和AIVD动态调度(Ours)三种策略。
- 吞吐量对比:如图4所示,在16节点的高负载极端场景下,AIVD策略的吞吐量比RR和SRA分别高出11.1%和14.6%。节点越多、环境越异构,其优势越明显。
- 延迟对比:如图5所示,同样在16节点场景,AIVD策略的平均延迟比RR和SRA降低了36.5%和32.5%,显著提升了系统响应速度与稳定性。
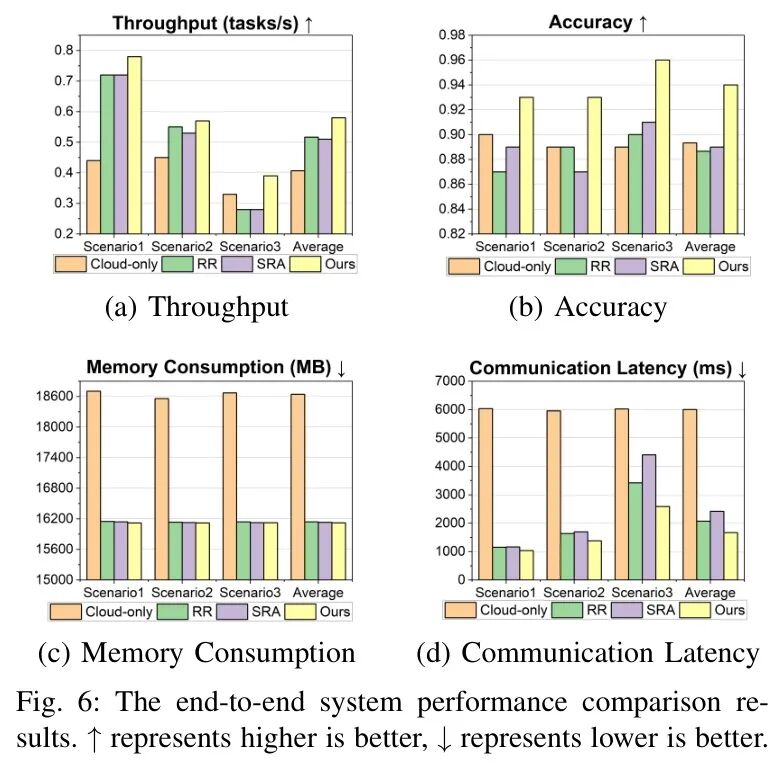
端到端框架效果:全面的帕累托改进
AIVD的终极价值在于端到端的协同优化。如图6所示,与纯云方案、传统边云方案相比,AIVD在多个关键指标上实现了全面领先:
- 相比纯云方案:吞吐量提升77%,准确率从0.85提升至0.93,资源消耗降低13.8%。
- 相比传统边云方案:通信延迟降低57.1%,内存使用显著减少。
这表明AIVD通过平衡计算、通信与内存资源,实现了真正的帕累托改进——所有指标同步优化。
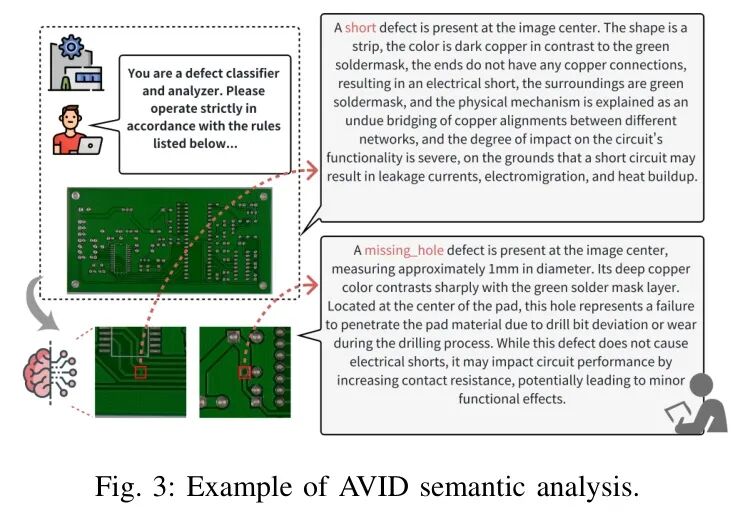
语义生成质量:从分类到诊断的飞跃
AIVD框架下的云端MLLM能够生成连贯、细致的缺陷描述,实现了可解释性的突破。如图3示例,模型不仅能分类,还能描述缺陷形态、分析潜在原因、甚至给出维修建议。这对于工业质检的价值在于:
- 加速根因分析:维修人员可快速定位工艺问题。
- 反馈工艺优化:积累的描述数据可用于指导生产参数调整。
- 完善质量追溯:建立结构化、细粒度的产品质量档案。
客观评价:优势、局限与展望
核心优势
- 架构创新性:首次在工业检测中深度协同“边缘定位-云端理解-动态调度”。
- 性能全面提升:在准确率、吞吐量、延迟、资源消耗上实现多目标优化。
- 强工程落地性:设计充分考虑了真实的异构资源与动态网络约束。
- 可解释性突破:推动工业检测从“黑盒判断”走向“白盒分析”。
潜在局限
- 依赖云端网络:若云端完全断连,系统将无法进行精细分类与语义生成。
- 初始部署成本:需搭建边云协同基础设施,对小型产线可能门槛较高。
- MLLM微调门槛:尽管使用了LoRA,但仍需一定的多模态模型调优经验。
未来改进建议
- 边缘缓存机制:在边缘节点缓存常见缺陷语义模板,支持弱网降级模式。
- 渐进式部署:在关键工位先行试点,验证效果后推广。
- 自动化工具链:提供更易用的微调与部署Pipeline,降低技术门槛。对这类人工智能与边缘系统结合的工程实践,开发者社区中常有深入探讨。
总结:不仅是技术,更是思维革新
AIVD框架的价值超越了一个优化方案本身,它体现了AI工程化的三个关键思维转变:
- 从“单体模型”到“协同系统”:摒弃万能模型的幻想,通过系统设计让专业组件协作,达成整体最优。
- 从“静态配置”到“动态适应”:承认工业环境的动态本质,让系统具备资源感知与实时调度的自调节能力。
- 从“结果输出”到“过程解释”:在工业领域,可解释性不是点缀,而是实现质量管控与工艺优化的刚性需求。
这项技术有望在电子制造(PCB/芯片)、精密加工(航空叶片/医疗器械)、新能源(电池/光伏)及食品医药等对检测精度与可解释性要求高的领域率先落地。其边云协同、动态调度的核心思想,对于其他面临类似效率与精度平衡问题的运维与AI应用场景也具有重要的借鉴意义。
参考文献
AIVD: Adaptive Edge-Cloud Collaboration for Accurate and Efficient Industrial Visual Detection
 发表于 2026-1-20 10:01:06
|
查看: 175|
回复: 0
发表于 2026-1-20 10:01:06
|
查看: 175|
回复: 0
