
摘要
本文介绍了DeepSeek提出的Engram,这是一种创新的条件记忆模块,通过引入静态知识查找机制作为稀疏性的新维度,与专家混合(MoE)架构形成互补。研究揭示了神经计算与静态记忆之间的U型分配规律,27B参数的Engram模型在知识检索、推理和长文本处理上显著超越同等参数的MoE基线。
一、研究背景:语言模型的双重任务困境
在人工智能领域,稀疏性一直是智能系统设计的核心原则,从生物神经回路到现代大语言模型都遵循这一规律。当前,这一原则主要通过专家混合(MoE)架构实现,它通过条件计算来扩展模型容量。由于能够在不成比例增加计算量的情况下大幅扩大模型规模,MoE已成为前沿模型的事实标准。
然而,语言信号的内在异质性表明结构优化仍有巨大空间。具体而言,语言建模包含两个性质截然不同的子任务:组合推理和知识检索。前者需要深度的动态计算,而大量文本——如命名实体和公式化模式——则是局部的、静态的、高度刻板化的。经典N-gram模型在捕获此类局部依赖关系方面的有效性表明,这些规律性自然地表示为计算成本低廉的查找操作。
由于标准Transformer缺乏原生的知识查找机制,当前的大语言模型被迫通过计算来模拟检索。例如,解析一个常见的多token实体需要消耗多个早期层的注意力和前馈网络。这个过程本质上相当于对静态查找表进行昂贵的运行时重建,浪费了宝贵的序列深度在本可分配给更高层次推理的琐碎操作上。
二、核心创新:条件记忆的新范式
为了使模型架构与这种语言双重性相匹配,研究团队提出了条件记忆这一互补的稀疏性维度。条件计算通过稀疏激活参数来处理动态逻辑,而条件记忆则依赖稀疏查找操作来检索固定知识的静态嵌入。
作为这一范式的初步探索,研究重新审视了N-gram嵌入作为典型实例:局部上下文作为键,通过恒定时间O(1)查找来索引大规模嵌入表。研究发现,这种静态检索机制可以成为现代MoE架构的理想补充——但前提是设计得当。
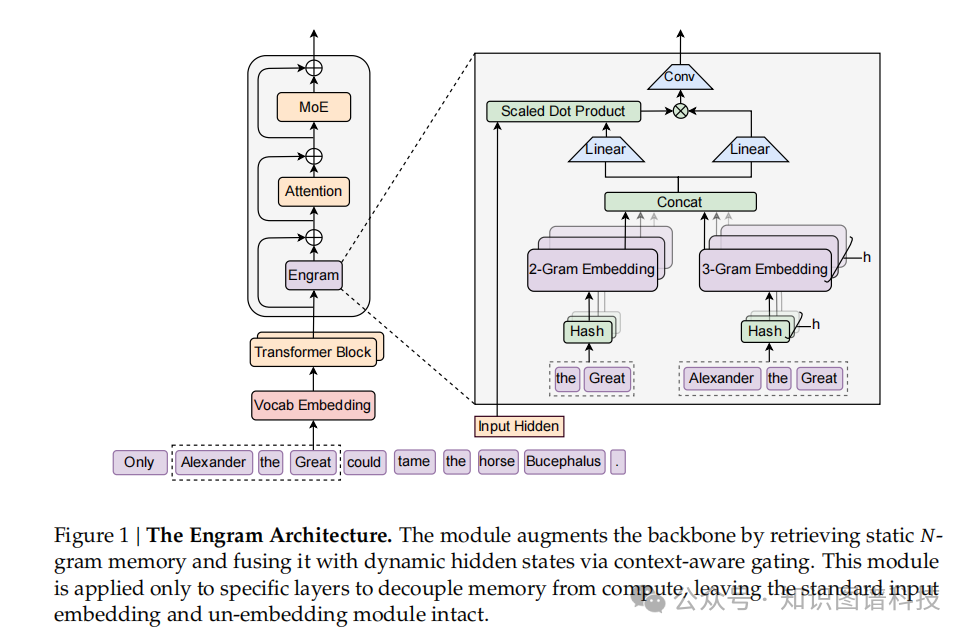
Engram架构详解
Engram是一个条件记忆模块,旨在通过结构化分离静态模式存储和动态计算来增强Transformer主干。该模块具有以下现代化适配特性:
- 分词器压缩:高效处理输入序列
- 多头哈希:实现快速查找
- 上下文化门控:动态调节嵌入权重
- 多分支集成:与现有架构无缝整合
如图1所示,该模块通过检索静态N-gram记忆并通过上下文感知门控与动态隐藏状态融合来增强主干网络。值得注意的是,该模块仅应用于特定层以解耦记忆和计算,保持标准输入嵌入和反嵌入模块不变。
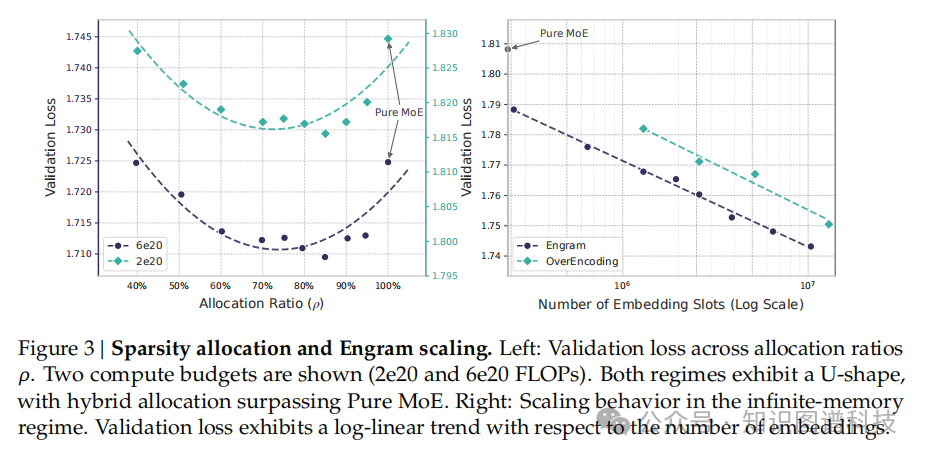
三、稀疏性分配定律:U型曲线的发现
为了量化这两种原语之间的协同作用,研究团队提出了稀疏性分配问题:在固定的总参数预算下,容量应如何在MoE专家和Engram记忆之间分配?
实验揭示了一个独特的U型扩展定律,表明即使是简单的查找机制,当作为一流建模原语对待时,也能作为神经计算的重要补充。在这一分配定律的指导下,研究团队将Engram扩展到27B参数模型。
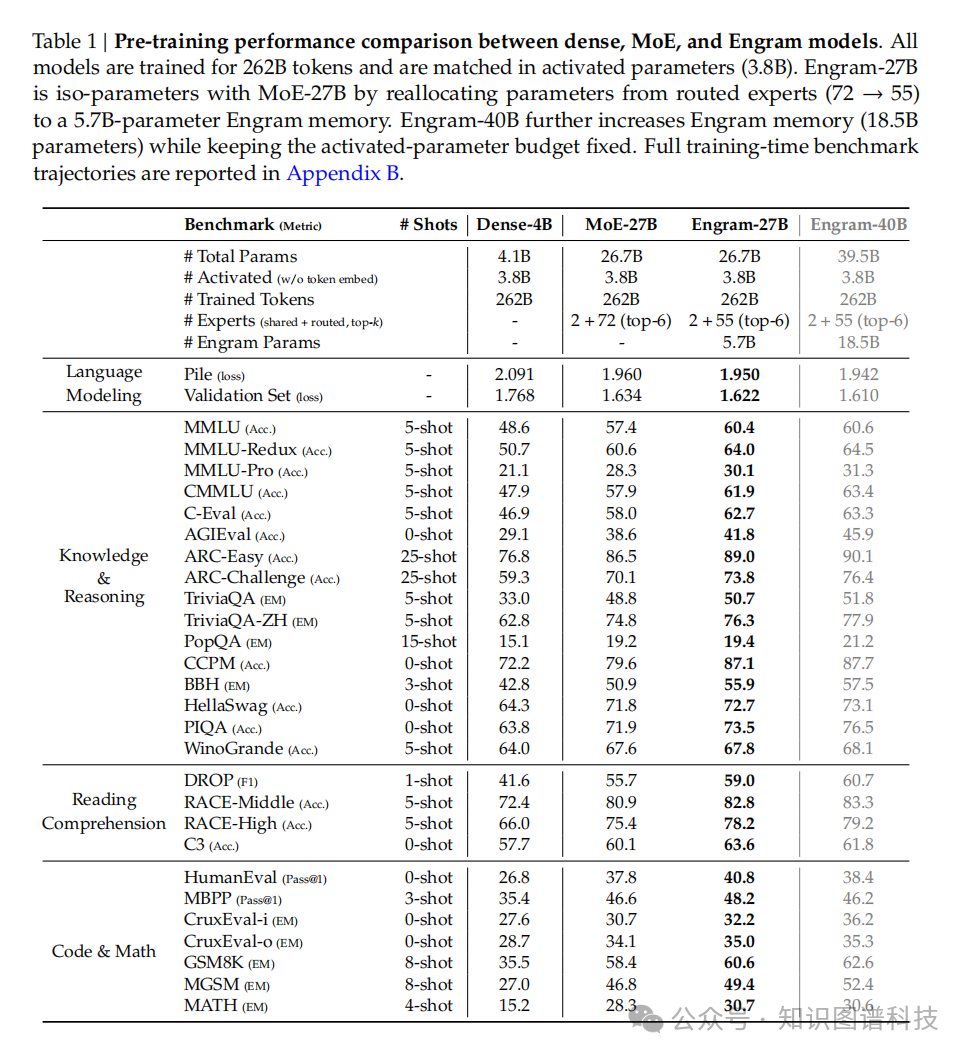
实验配置与模型对比
所有模型在2620亿token上进行预训练,并在激活参数数量(3.8B)上严格匹配:
- Dense-4B:总参数4.1B
- MoE-27B:总参数26.7B(2个共享专家 + 72个路由专家,top-6)
- Engram-27B:总参数26.7B(2个共享专家 + 55个路由专家,top-6,+ 5.7B Engram参数)
- Engram-40B:总参数39.5B(增加Engram参数至18.5B)
四、性能突破:全方位的显著提升
与严格等参数和等FLOPs的MoE基线相比,Engram-27B在多个领域实现了卓越性能。关键发现是,性能提升不仅限于知识密集型任务,在一般推理和代码/数学领域观察到更显著的改进。
4.1 知识检索任务
在知识密集型基准测试中,Engram展现出预期的优势:
- MMLU:+3.4(60.4 vs 57.4)
- CMMLU:+4.0(61.9 vs 57.9)
- MMLU-Pro:+1.8(30.1 vs 28.3)
- C-Eval:+4.7(62.7 vs 58.0)
4.2 推理能力提升(超预期发现)
更引人注目的是,在一般推理任务上的巨大提升:
- BBH(Big-Bench Hard):+5.0(55.9 vs 50.9)
- ARC-Challenge:+3.7(73.8 vs 70.1)
- DROP(阅读理解推理):+3.3(F1分数:59.0 vs 55.7)
- AGIEval:+3.2(41.8 vs 38.6)
4.3 代码与数学领域
在技术计算任务上同样表现出色:
- HumanEval:+3.0(40.8 vs 37.8)
- MATH:+2.4(30.7 vs 28.3)
- GSM8K:+2.2(60.6 vs 58.4)
- MGSM(多语言数学):+2.6(49.4 vs 46.8)
4.4 语言建模基础指标
在核心语言建模任务上:
- 验证集困惑度:1.622 vs 1.634(MoE-27B)
- Pile测试集:1.950 vs 1.960
五、机制分析:为何Engram如此有效?
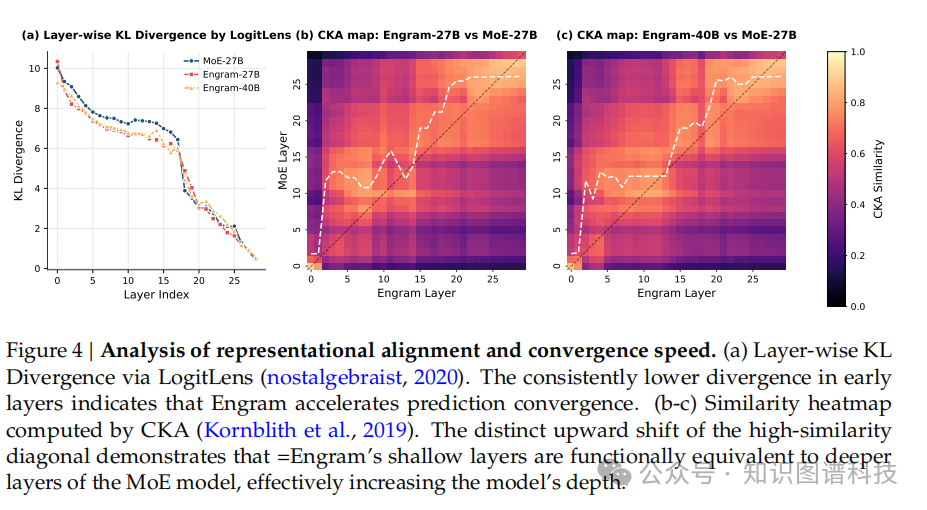
通过LogitLens和CKA(中心核对齐)等机制分析工具,研究团队揭示了性能提升的根源:
5.1 释放早期层计算资源
Engram将主干网络从早期层的静态知识重建中解放出来,从而增加了可用于复杂推理的有效深度。传统Transformer必须使用多个早期层来“重建”常见的命名实体或固定模式,而Engram通过O(1)查找直接检索这些信息。
5.2 注意力容量重新分配
通过将局部依赖关系委托给查找操作,Engram释放了注意力容量以专注于全局上下文。这种机制使模型能够将宝贵的注意力资源集中在真正需要动态推理的部分。
5.3 长文本处理的飞跃
这种注意力重新分配在长文本场景中效果尤为显著:
- Multi-Query NIAH(大海捞针):97.0 vs 84.2(+12.8)
- Variable Tracking:89.0 vs 77.0(+12.0)
- LongPPL和RULER基准:全面超越基线
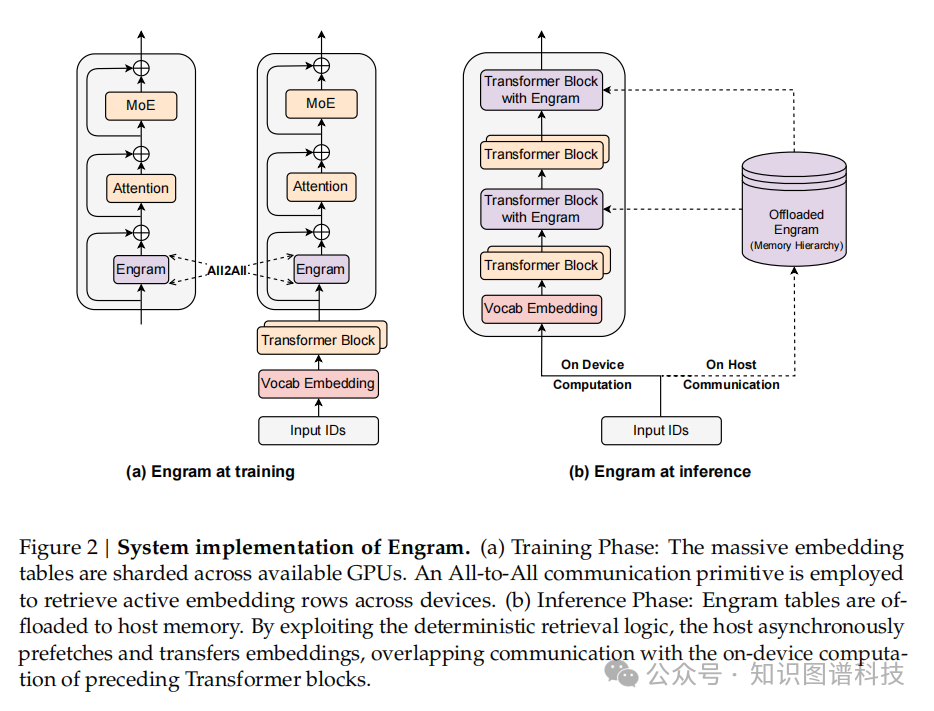
六、基础设施感知效率:突破GPU内存限制
研究团队确立了基础设施感知效率作为一流原则。与MoE的动态路由不同,Engram采用确定性ID来实现运行时预取,将通信与计算重叠。
关键技术优势
实证结果显示,将100B参数表卸载到主机内存产生的开销可以忽略不计(< 3%)。这表明Engram有效绕过了GPU内存约束,促进了激进的参数扩展。
这一特性使得Engram能够:
- 在不增加GPU内存压力的情况下扩展到超大规模参数
- 通过确定性寻址实现高效的内存管理
- 在实际部署中保持极低的延迟开销
七、理论贡献:重新定义稀疏性
Engram的成功不仅在于性能提升,更在于开创了一个新的理论框架:
7.1 稀疏性的两个维度
- 条件计算(MoE):稀疏激活参数处理动态逻辑
- 条件记忆(Engram):稀疏查找操作检索静态知识
7.2 U型分配定律
研究发现,神经计算和静态记忆之间存在最优平衡点。既不是纯MoE,也不是纯记忆,而是两者的精心组合才能达到最佳性能。
7.3 架构与语言特性的对齐
Engram体现了“架构应与任务特性对齐”的设计哲学。语言的双重性(动态推理 + 静态知识)要求模型架构也相应地分化为两个互补系统。
八、实践意义与未来展望
对产业界的启示
- 模型训练效率:在相同计算预算下获得更强性能
- 部署灵活性:通过主机内存卸载突破GPU限制
- 任务适应性:在知识检索和复杂推理之间自动平衡
对学术界的启示
- 新研究方向:条件记忆作为独立研究领域
- 架构设计范式:从单一稀疏性到多维稀疏性
- 评估方法论:需要更全面的机制分析工具
下一代模型的必备组件
研究团队认为,条件记忆将成为下一代稀疏模型不可或缺的建模原语。随着模型规模持续增长,高效的知识存储和检索机制将变得越来越重要。
九、技术细节:如何实现Engram
9.1 稀疏检索机制
通过哈希N-gram实现稀疏检索,涉及分词器压缩和多头哈希设计,确保O(1)时间复杂度的高效查找。
9.2 动态融合策略
检索到的静态嵌入通过上下文感知门控进行动态调节,并经过轻量级卷积进行精炼。这确保了静态记忆与动态计算的无缝集成。
9.3 多分支架构集成
Engram模块与多分支架构集成,允许灵活部署在特定层,而不干扰整体模型结构。
9.4 系统级优化
采用确定性寻址实现运行时预取,通过重叠通信与计算最小化延迟。这是Engram能够处理超大参数表的关键。
结论
Engram代表了大语言模型架构设计的重要突破。通过引入条件记忆作为稀疏性的新维度,它不仅提升了模型在知识检索任务上的表现,更重要的是显著增强了一般推理能力和长文本处理能力。
U型分配定律的发现为未来模型设计提供了理论指导,而基础设施感知效率的实现则展示了实用性。随着代码的开源,研究社区可以进一步探索条件记忆的潜力,推动下一代智能系统的发展。
对于企业、研究机构和投资者而言,Engram不仅是一项技术创新,更是理解未来AI架构演进方向的重要参考。它揭示了在追求更大模型规模的同时,架构创新与任务特性对齐的重要性。这项研究也启发我们,对Deep Learning基础架构的深刻思考,往往能带来超越简单参数堆叠的性能飞跃。欢迎在云栈社区继续探讨大模型前沿架构与技术实践。
 发表于 2026-1-20 09:55:42
|
查看: 219|
回复: 0
发表于 2026-1-20 09:55:42
|
查看: 219|
回复: 0
