在当前人工智能浪潮中,多智能体系统(MAS)与强化学习(RL)的结合展现出巨大潜力。本文深入探讨了如何利用一种面向策略的强化学习新方法——AT-GRPO,来优化协作型大型语言模型(LLMs)的性能,特别是在处理复杂、长序列任务时的应用与效果。
研究背景
大型语言模型(LLMs)已在编程、科学推理等多个领域展现出卓越的决策能力。然而,在多任务协同环境中,如何有效组织并驱动多个LLM智能体,以实现更高的整体效率和准确性,仍是一个挑战。当前,多智能体系统与强化学习虽各自发展成熟,但二者的深度结合,尤其是在需要角色精细化分工的协作场景中,其训练流程优化与性能提升仍有大量研究空白。因此,开发一种新的、能够有效支撑MAS的强化学习算法至关重要,它能显著增强角色特定协作的有效性,并提升模型的泛化与决策精度。
研究方法
为解决上述问题,本文提出了AT-GRPO(Agent- and Turn-wise Grouped Policy Optimization)算法。该算法包含两大核心部分:(i)专门针对多智能体系统设计的、基于智能体和回合分组的RL优化机制;(ii)支持单策略与多策略训练的灵活系统架构。
AT-GRPO采用了一种独特的分组比较方法:在每个决策回合,它将候选动作按相同角色和相同回合进行分组,从而在组内实现更有效的优劣比较与策略梯度计算。在训练过程中,系统收集交互经验构建数据集,通过多次迭代优化,分别更新每个智能体的策略,从而强化模型间的协作效能。
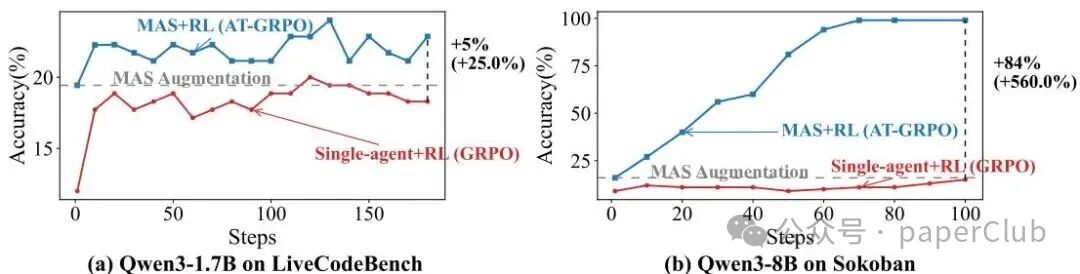 图1: AT-GRPO算法与传统单智能体GRPO的对比示意图,凸显其在复杂任务环境中的结构性优势。
图1: AT-GRPO算法与传统单智能体GRPO的对比示意图,凸显其在复杂任务环境中的结构性优势。
研究结果
实验结果表明,AT-GRPO在长序列规划任务上表现尤为突出。其准确率从单智能体基线的14%大幅提升至96%至99.5%之间,充分体现了强化学习与多智能体系统结合的巨大威力。
此外,在需要多步决策推理的任务上,AT-GRPO也带来了显著提升。在编程和数学问题求解任务中,模型的平均性能提升率分别达到3.87%-7.62%和9.01%-17.93%。这一突破性进展表明,面向特定角色的策略训练有效增强了系统的专业化能力,并从机制上改善了传统模型的协作效率。
| 方法 |
游戏 |
规划任务 |
编码任务 |
数学任务 |
| 单智能体 |
7.00 |
5.00 |
11.60 |
13.40 |
| 单智能体+GRPO |
29.00 |
11.00 |
18.80 |
16.70 |
| MAS + AT-GRPO (角色专属策略) |
99.00 |
96.00 |
20.90 |
39.60 |
表1: 不同方法在四类任务上的性能对比(数值越高越好)。
结论与展望
本文通过AT-GRPO算法,成功构建并验证了一种强化学习与多智能体系统深度结合的新范式,证明了其在多领域复杂任务中的显著效能。本研究目前聚焦于合作型任务并取得了成功,未来可进一步探索该方法在竞争性或混合型环境中的适应性,以及如何将这种角色特定政策训练范式扩展到更庞大、更复杂的环境与模型集群中。迈向多模态学习与大规模模型协同训练,将是发掘其更广泛应用潜力的关键方向。
📚 文献信息
- 文献作者:Yujie Zhao, Lanxiang Hu, Yang Wang, Minmin Hou, Hao Zhang, Ke Ding, Jishen Zhao
- 发表时间:2025-10-13
- arxiv:arxiv.org/abs/2510.11062
|  发表于 2025-12-7 00:27:39
|
查看: 241|
回复: 0
发表于 2025-12-7 00:27:39
|
查看: 241|
回复: 0
