在视频生成领域,传统扩散模型面临着生成速度慢、画面随生成时间推移而逐渐失稳的难题,这使得它们难以胜任实时、连续的音频驱动虚拟人场景。阿里提出的 Live Avatar 框架,通过算法与系统的协同设计,成功让一个140亿参数级别的大模型实现了高质量、实时、无限时长的虚拟人生成。
其核心技术之一是 Timestep-forcing Pipeline Parallelism (TPP) 并行推理策略。该策略将扩散模型的多步去噪过程分配给多张 GPU 同时处理,从根本上突破了传统顺序计算的瓶颈,实现了低延迟的流式生成,这是人工智能模型在部署优化上的重要实践。
为了确保长序列生成中画面的一致性,避免出现“崩脸”或颜色漂移,Live Avatar 引入了 RSFM (Reference-based Self-Correction Module) 机制。该机制持续利用参考图像进行动态校准,确保长视频画面的稳定性。同时,框架采用了自适应蒸馏技术,使得大模型在流式输出时依然能维持高保真画质。最终,整个系统仅需5张 H800 GPU即可达到20 FPS 的实时生成速度。
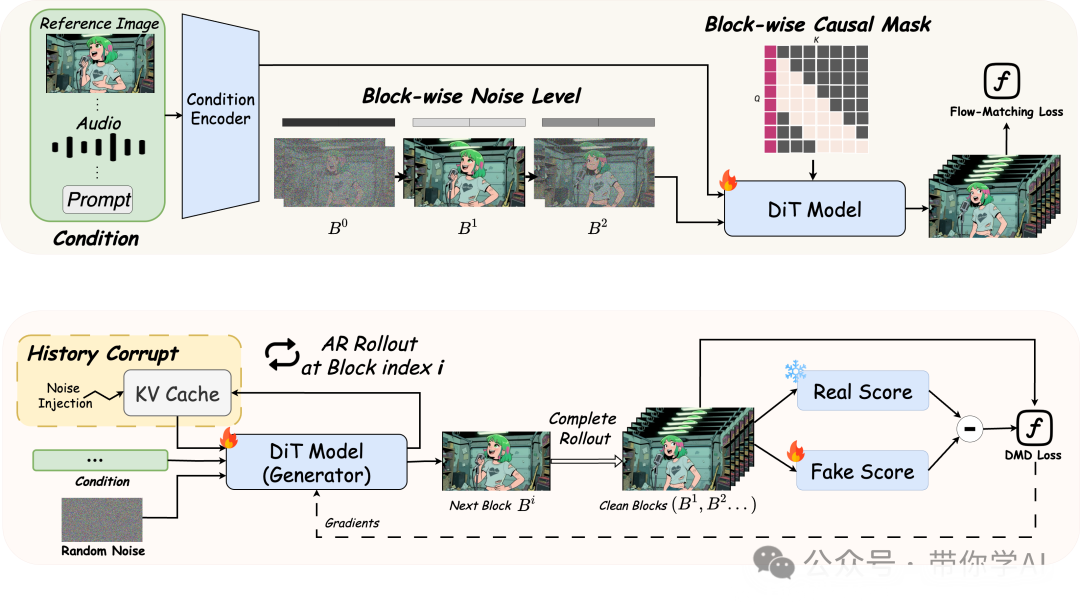
Live Avatar 训练框架概述:
- (a) 阶段 1:Diffusion Forcing 预训练,展示了块级噪声的设置方式以及所使用的注意力掩码。
- (b) 阶段 2:Self-Forcing 训练,通过强制保持 KV 缓存与噪声潜变量之间的噪声等级一致性来完成知识蒸馏。
TPP (Timestep-forcing Pipeline Parallelism) 工作流程:在预热阶段填满流水线后,所有 GPU 将在完全流水化阶段同步执行去噪操作,从而将顺序执行的扩散链转变为异步的空间流水线。例如,GPU2 始终负责处理 t2 → t1 时间步的去噪:它会复用本地的 KV 缓存以极速获取历史信息,并仅将处理后的潜变量发送给 GPU3,通信开销极小。
凭借其实时与流式特性,Live Avatar 具备了强大的交互潜力。用户可以借助麦克风和摄像头与虚拟人进行自然的“面对面”对话,并获得实时的视觉反馈,观察虚拟人对语音和表情的即时反应。将 Live Avatar 与 Qwen3-Omni 等大型语言模型集成,便能构建出真正意义上的全交互式对话体代理。
技术效果展示:
- 真人视频生成:能够根据输入生成高度逼真、口型同步的真人视频。
- 动画视频生成:同样适用于风格化、卡通形象的实时生成与驱动。
存在的挑战与局限:
尽管提出的 TPP 推理策略显著提升了帧率(FPS),但并未降低TTFF(Time To First Frame,首次帧延迟),这在某种程度上限制了极致的交互响应性。此外,系统对 RSFM 机制的高度依赖,可能在极其复杂的场景下对长时序的全局一致性构成挑战。
相关资源:
|  发表于 2025-12-7 22:44:49
|
查看: 314|
回复: 0
发表于 2025-12-7 22:44:49
|
查看: 314|
回复: 0
