一、背景
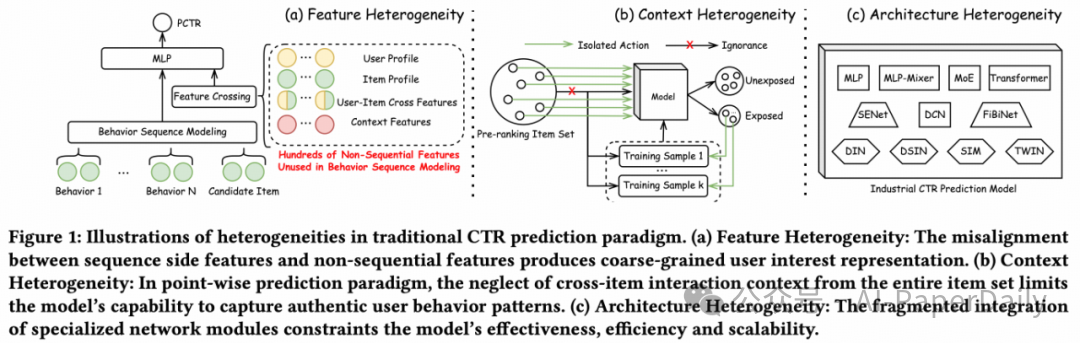
CTR预测是推荐系统的核心环节,其性能直接影响用户体验和平台收益。然而,现有的工业级模型在实践中常面临三类异质性问题的制约:
- 特征异质性:用户历史行为序列通常只用少量侧面特征(如物品类别)表示,而非序列特征则极为丰富,导致模型对用户兴趣的表征存在粒度差异和不一致。
- 上下文异质性:传统的点预测模式独立预估每个物品的点击率,忽视了同一次推荐曝光中物品之间的相互影响。
- 架构异质性:为了处理复杂问题,工业模型往往由多个专业化模块堆砌而成,这种碎片化结构在效果和效率上均存在瓶颈。
针对上述挑战,本文介绍HoMer,一种面向同质化设计的Transformer架构。其核心创新在于:通过构建全景序列实现精细化的兴趣建模,采用集合式预测捕获物品间的上下文交互,并以统一的编码器-解码器(Encoder-Decoder)架构整合功能,实现性能与效率的双重突破。
论文地址:https://arxiv.org/pdf/2510.11100
二、方法
模型结构概览
HoMer采用了统一且完整的Encoder-Decoder架构,形成一个从用户历史行为到待预测物品集合的建模闭环:
- 序列编码器:负责从整合了完整特征的用户历史行为序列(即全景序列)中,提取出细粒度的用户兴趣表征。
- 集合式解码器:同时建模待预测物品之间的交互关系,以及每个物品与用户兴趣表征之间的交互。
这种设计将传统方案中分散的特征工程、序列建模、上下文建模等组件整合为同质化的统一架构,通过共享计算减少冗余,并允许灵活地独立扩展用户侧与物品侧的计算能力,对于构建高效的大规模推荐系统具有重要意义。
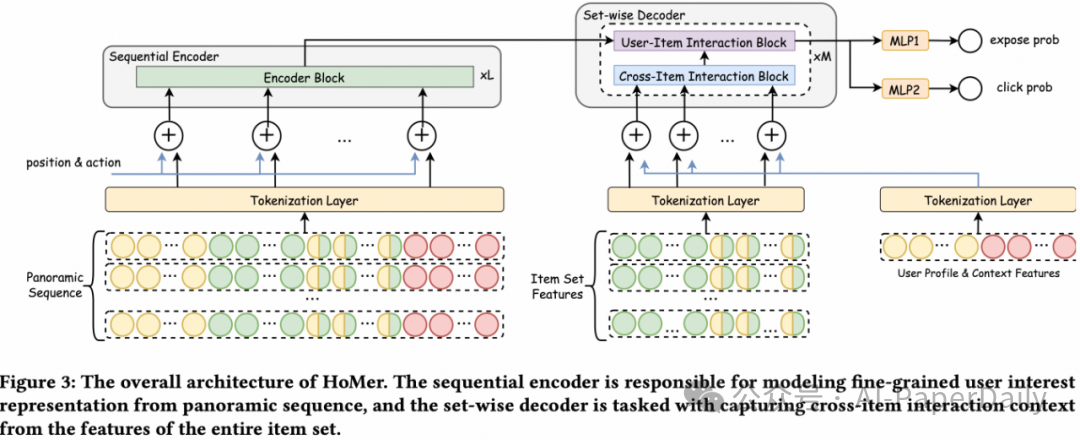
全景序列建模:解决特征异质性
传统方法中,每个历史行为通常只由ID和少量侧特征(如类别)表示,信息粗糙。HoMer提出构建全景序列,即在序列建模阶段,为每一个历史行为对齐其完整、丰富的非序列特征(如价格、品牌等),从而精确还原用户进行历史决策时的完整上下文。
具体实现上,序列编码器首先将每个历史行为转化为初始的兴趣表示:
h_i^(0) = Tokenize(e_i, p_i, a_i)
其中,e_i代表第i个行为及其所有侧特征,p_i和a_i分别表示位置编码和用户动作(如点击与否)。Tokenize过程包含了嵌入查找和由共享全连接层构成的令牌化层。随后,通过堆叠的L个编码器块对表征进行迭代精炼:
h_i^(l) = Transformer_Block^(l)(h_i^(l-1))
每个块内包含多头自注意力、前馈网络等标准组件。这一设计使得每个历史行为都能获得上下文感知的、精细化的表示,极大提升了用户兴趣建模的能力。
集合式预测:解决上下文异质性
针对传统点预测忽略物品间交互的问题,HoMer提出集合式预测范式。解码器采用双路径设计,其输入由用户兴趣上下文与待预测物品的初始嵌入共同构成:
d_j^(0) = [h_user, e_j]
其中,h_user是压缩后的用户兴趣上下文表示,e_j是第j个待预测物品的初始嵌入。
解码器同样通过堆叠的块进行信息传递与精炼:
d_j^(l) = Decoder_Block^(l)(d_j^(l-1), h)
在解码过程中,自注意力机制帮助捕获物品集合内部的交互关系,而交叉注意力机制则负责融合用户兴趣信息。为了进一步增强模型对曝光上下文的感知能力,论文引入了辅助曝光损失:
L_exposure = - (1/N) Σ (y_exp * log(p_exp) + (1 - y_exp) * log(1 - p_exp))
该损失函数鼓励模型学习物品被曝光(而不仅仅是点击)的模式。结合主任务点击损失,模型的总损失为两者的加权和,使其能够同步学习点击预测与曝光决策。
三、实验验证
实验在美团搜索广告场景下进行,数据规模庞大,包含4.2亿次请求、3900万用户和69万个独立物品。
离线实验结果表明,HoMer在AUC指标上达到0.8169,相比工业基线(0.8070)提升0.0099,显著优于其他前沿模型。即使在计算资源受限的条件下,HoMer也展现出更优的性能扩展性。
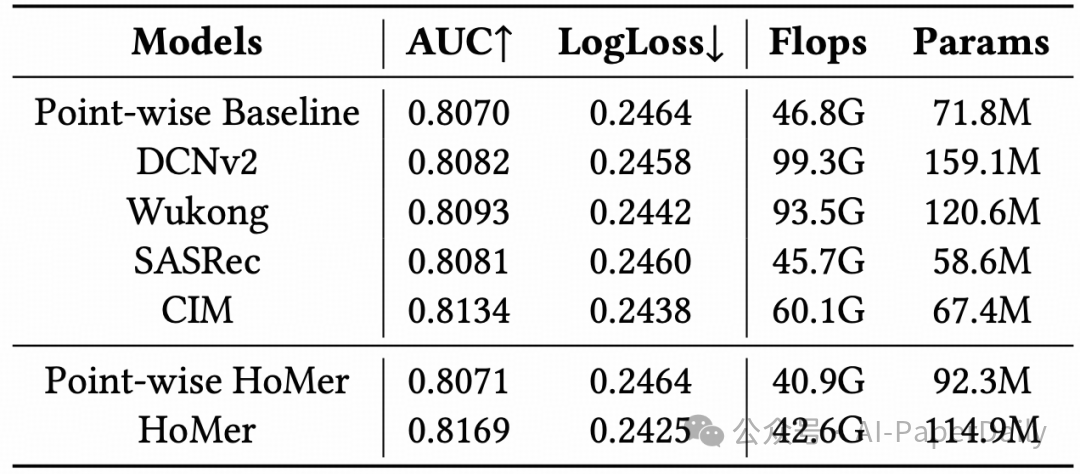
在线A/B测试结果更具说服力:在服务数千万用户的线上场景中,HoMer实现了CTR提升1.99%和RPM(千次展示收入)提升2.46%的业务收益。此外,通过初步的工程优化(如算子融合、计算图优化等),在保证效果的同时节约了约27%的GPU资源,模型计算效率(FLOPs利用率)从7.8%提升至12.2%,充分证明了该统一架构在大规模工业级推荐与广告系统中兼具有效性和高效性,其工程实践也为同类系统的性能优化提供了参考。
 发表于 2025-12-9 05:44:30
|
查看: 205|
回复: 0
发表于 2025-12-9 05:44:30
|
查看: 205|
回复: 0
