在大规模语言模型(LLM)的训练与推理中,高效的参数同步是提升整体性能的关键。本文将从最基础的AllReduce操作出发,逐步剖析Reduce Scatter、Tree AllReduce和Ring AllReduce等几种核心优化算法,帮助读者深入理解分布式训练中通信优化的原理与实践。
一、基础AllReduce
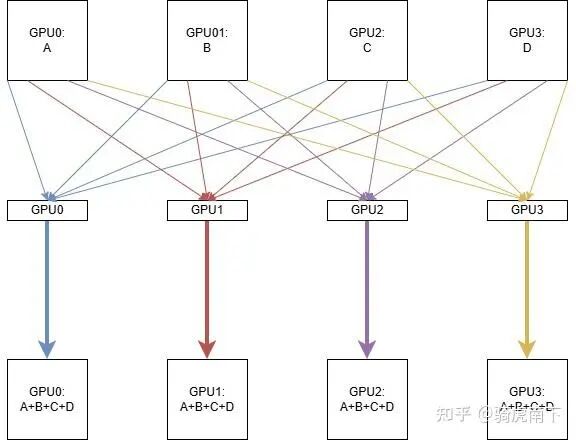
如上图,假设有4个GPU(GPU0/GPU1/GPU2/GPU3),每个GPU上各有一个Tensor数据(A/B/C/D)。
最原始的AllReduce算法是:每个GPU都拉取其他所有GPU上的全量数据,在本地进行累加,从而得到最终结果。例如,GPU0会拉取GPU1的B、GPU2的C和GPU3的D,然后与自身的A对应位置相加。其他GPU执行相同的操作。
这种方法虽然直观,但每个GPU都需要传输和计算全量数据,通信和计算开销巨大。我们能否让每张卡只处理一部分数据呢?
二、Reduce Scatter
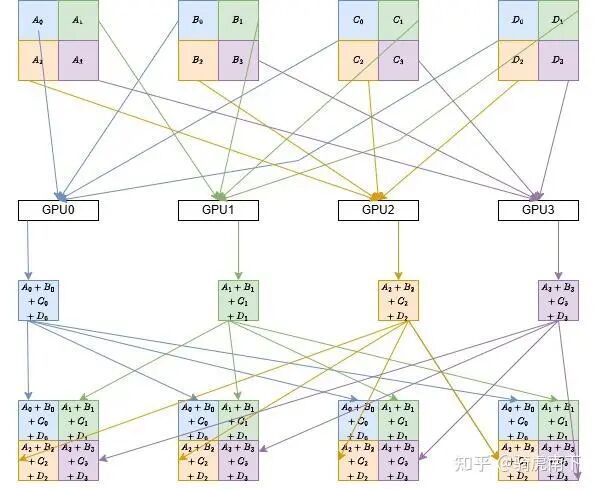
Reduce Scatter算法对上述过程进行了优化。它将每个GPU上的数据(如GPU1上的B)等分为四份(B_0, B_1, B_2, B_3),并让每个GPU只负责聚合其中一份。
具体过程以GPU0为例:
- GPU1、GPU2、GPU3分别将自己数据的第一部分(B_0, C_0, D_0)发送给GPU0。
- 与此同时,GPU0、GPU2、GPU3将各自数据的第二部分发送给GPU1,以此类推。
每个GPU收到数据后,并行地对各自负责的那一份数据进行累加(Reduce)。例如,GPU0计算 A_0 + B_0 + C_0 + D_0。
接下来,每个GPU将自己累加得到的这1/4结果数据,广播(Scatter)给所有其他GPU。最后,每个GPU将收到的三份结果与自身拥有的一份拼接(Concat)起来,就得到了完整的AllReduce结果。
此方案将GPU间的数据传输量和本地计算量都降至原始的1/4,仅额外增加了一次1/4数据的广播操作,效率显著提升。
三、Tree AllReduce
当GPU数量进一步增加(例如8个)且网络拓扑具有层次性时(如机内通信带宽高,跨机通信带宽低),Tree AllReduce是更优的选择。
假设GPU0-3为一组,GPU4-7为另一组。
第一步:组内Reduce Scatter
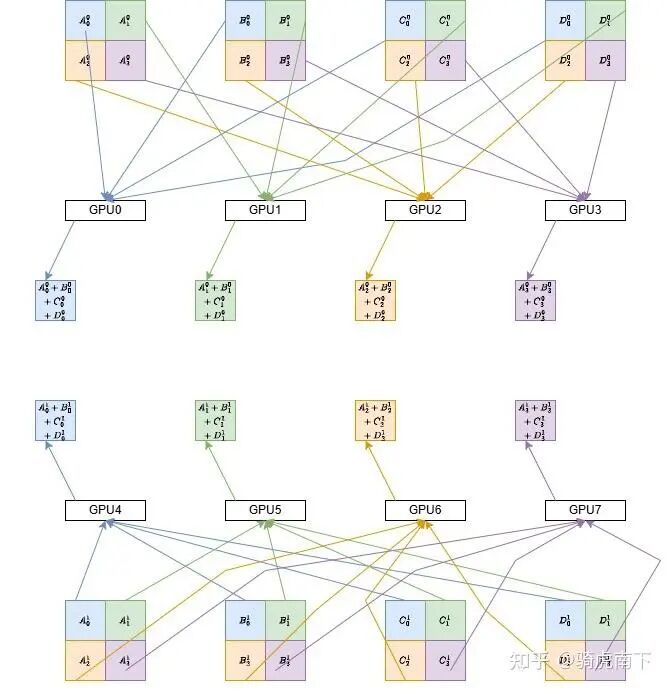 两组GPU内部独立执行Reduce Scatter操作。完成后,每组内的每个GPU都拥有全局结果数据的1/4。例如,GPU0和GPU4分别获得了各自组内左上角那1/4数据的累加结果。
两组GPU内部独立执行Reduce Scatter操作。完成后,每组内的每个GPU都拥有全局结果数据的1/4。例如,GPU0和GPU4分别获得了各自组内左上角那1/4数据的累加结果。
第二步:组间数据交换与累加
 对应位置的GPU进行跨组通信并累加。例如,GPU0与GPU4交换各自拥有的1/4数据并累加,使得两者都获得了8卡全局中左上角1/4数据的最终结果。GPU1与GPU5、GPU2与GPU6、GPU3与GPU7执行类似操作。
对应位置的GPU进行跨组通信并累加。例如,GPU0与GPU4交换各自拥有的1/4数据并累加,使得两者都获得了8卡全局中左上角1/4数据的最终结果。GPU1与GPU5、GPU2与GPU6、GPU3与GPU7执行类似操作。
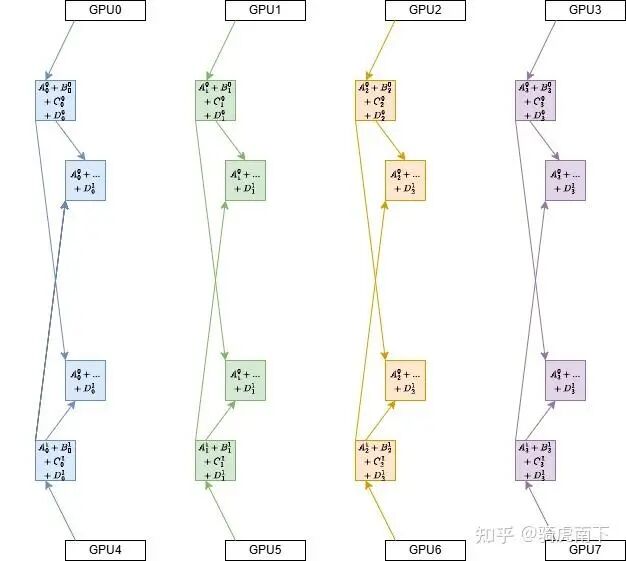
第三步:组内结果广播
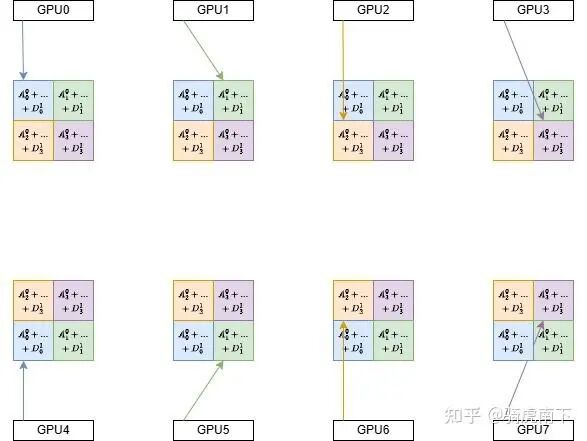 最后,在每个组内,拥有最终结果不同部分的GPU将数据广播给组内同伴。例如,在GPU0-3组内,GPU1、GPU2、GPU3将各自的结果部分发给GPU0,GPU0由此集齐所有部分,得到完整结果。另一组执行相同操作。
最后,在每个组内,拥有最终结果不同部分的GPU将数据广播给组内同伴。例如,在GPU0-3组内,GPU1、GPU2、GPU3将各自的结果部分发给GPU0,GPU0由此集齐所有部分,得到完整结果。另一组执行相同操作。
Tree AllReduce有效利用了网络带宽的层次性,减少了低速链路上的通信量。
四、Ring AllReduce
Ring AllReduce是另一种经典的、适用于环状拓扑的优化算法。我们以4卡为例分解其步骤。
数据准备
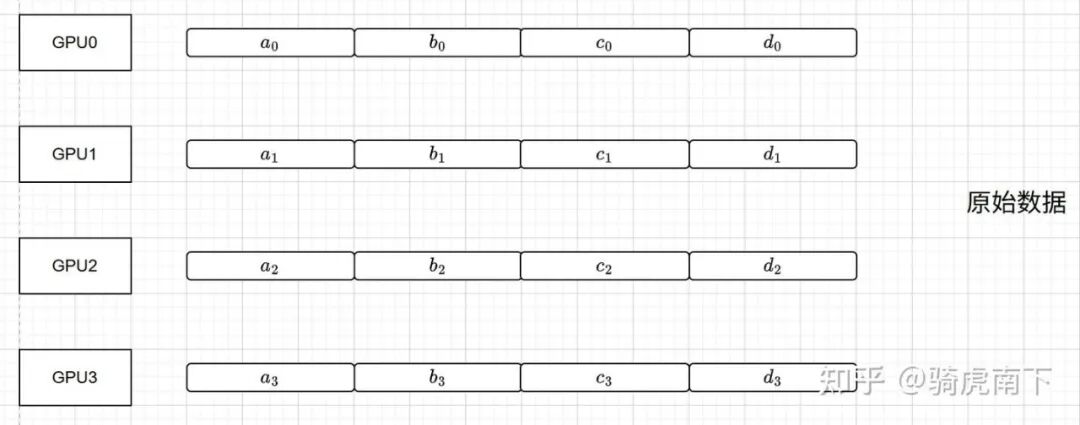 首先,将每张卡上的数据等分为4块(例如GPU0的数据分为a_0, b_0, c_0, d_0)。
首先,将每张卡上的数据等分为4块(例如GPU0的数据分为a_0, b_0, c_0, d_0)。
第一步:Reduce操作(初始环)
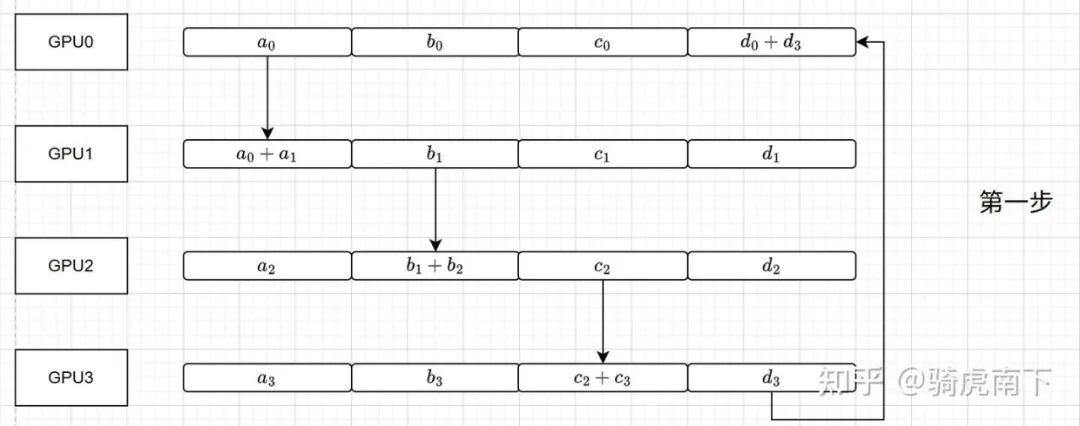 GPU沿环顺序发送数据块并累加:
GPU沿环顺序发送数据块并累加:
- GPU0发送a_0给GPU1,GPU1计算
a_0 + a_1。
- GPU1发送b_1给GPU2,GPU2计算
b_1 + b_2。
- GPU2发送c_2给GPU3,GPU3计算
c_2 + c_3。
- GPU3发送d_3给GPU0,GPU0计算
d_3 + d_0。
第二步:Reduce操作(继续环)
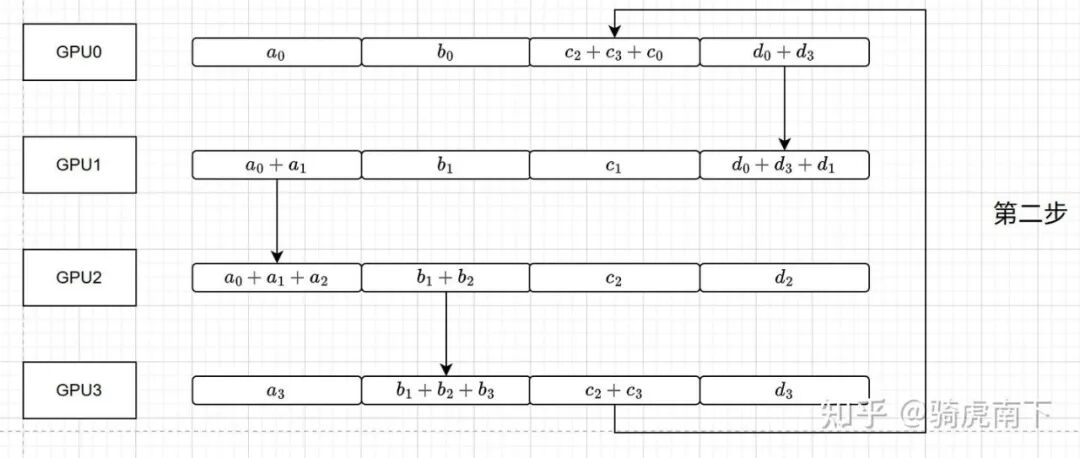 环继续传递和累加:
环继续传递和累加:
- GPU0将
d_3 + d_0 发送给GPU1,GPU1计算 d_3 + d_0 + d_1。
- 其他GPU执行类似操作。经过此轮,每个GPU都完成了三个GPU上某一块数据的累加。
第三步:完成Reduce
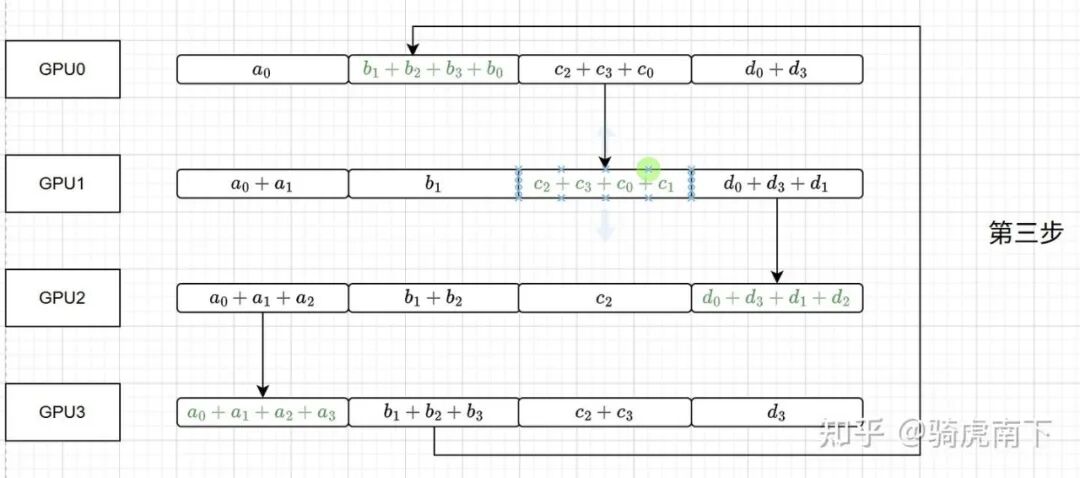 环完成最后一次传递和累加:
环完成最后一次传递和累加:
- GPU3将
b_1 + b_2 + b_3 发送给GPU0,GPU0计算 b_0 + b_1 + b_2 + b_3,得到b块的最终结果。
- 同理,GPU0得到c块结果,GPU1得到d块结果,GPU2得到a块结果。
至此,Reduce阶段完成,每个GPU拥有全局AllReduce结果中的一块。
第四至六步:AllGather操作

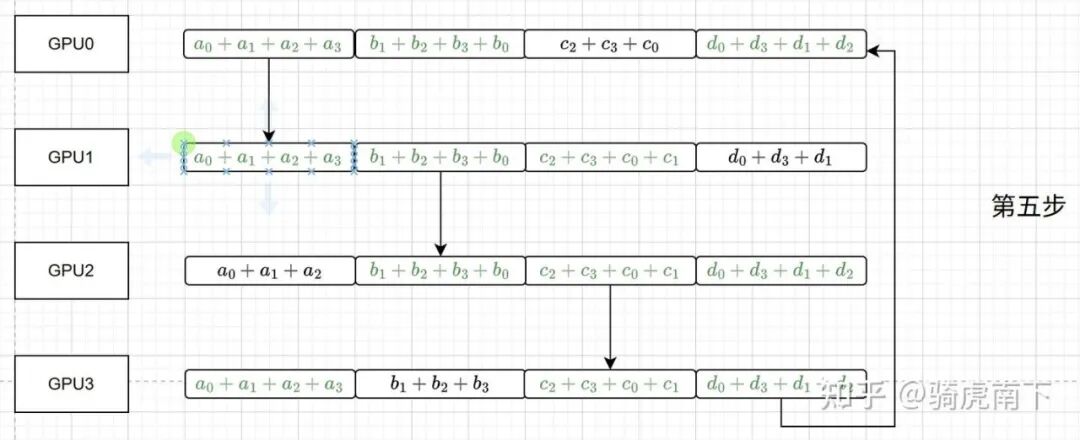
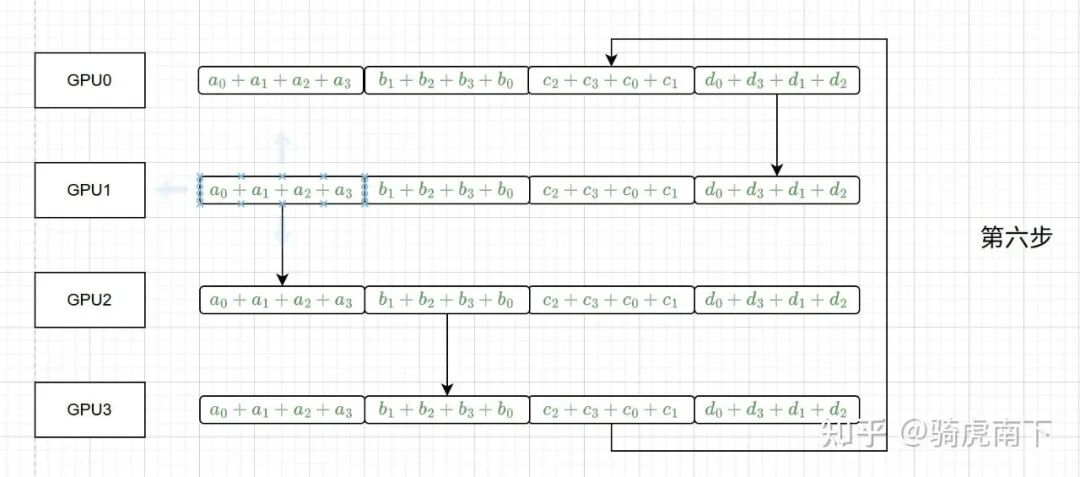 接下来是AllGather阶段,每个GPU沿环将自己拥有的那一块结果广播出去。经过三步传递,所有GPU都收集齐了全部四块结果,完成了完整的AllReduce。
接下来是AllGather阶段,每个GPU沿环将自己拥有的那一块结果广播出去。经过三步传递,所有GPU都收集齐了全部四块结果,完成了完整的AllReduce。
Ring AllReduce的优势在于其通信模式规整,能充分利用双向带宽,并且易于在像Kubernetes编排的集群或容器化环境中实现高效的流水线,是现代人工智能框架(如PyTorch, TensorFlow)分布式训练中常用的通信原语。
除了上述算法层面的优化,在实际的云原生部署中,还常结合计算与通信重叠、梯度压缩等技术来进一步压榨分布式训练的性能。
 发表于 2025-12-9 07:46:34
|
查看: 261|
回复: 0
发表于 2025-12-9 07:46:34
|
查看: 261|
回复: 0
