构建必须运行在端侧、本地或边缘环境中的 AI 应用时,开发者常面临一个核心难题:究竟该选择哪一款小语言模型(SLM)进行微调以获得最佳效果?市面上的选择繁多,包括Qwen、Llama、Gemma、Granite、SmolLM等系列,如何做出科学决策?本文将通过一项详尽的基准测试,用数据为您解答。
核心结论速览
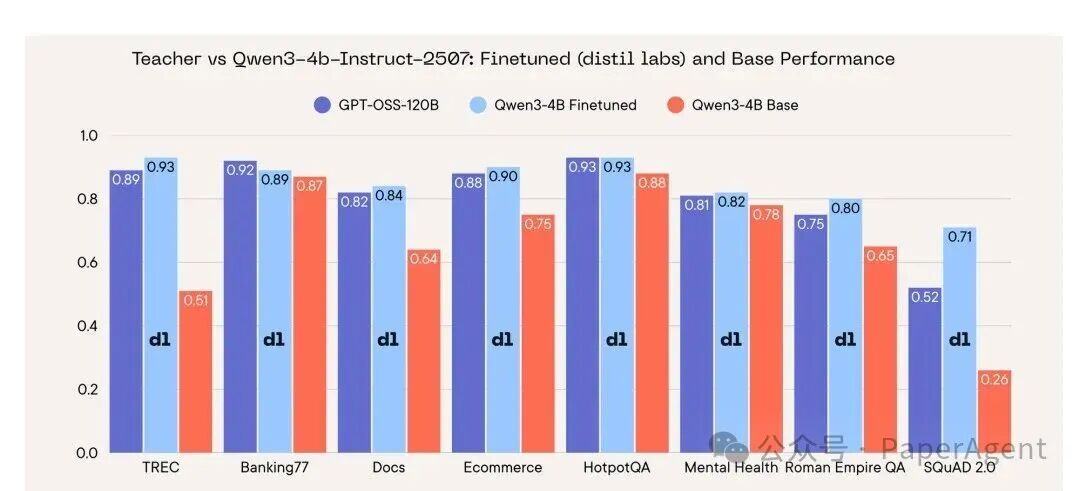
- 微调实现以小博大:经过微调的 Qwen3-4B 模型,在8项基准测试中的7项上,其性能与体积庞大30倍的教师模型 GPT-OSS-120B 持平甚至更优,仅有一项任务有3个百分点的微小差距。特别是在 SQuAD 2.0 数据集上,微调后的小模型反超教师模型达19分。这证明,通过针对性的微调,仅需极低成本即可在本地硬件上获得接近前沿大模型的准确率。
- 微调后综合性能最优:Qwen3 系列模型在微调后 consistently 表现最强,其中 Qwen3-4B-Instruct-2507 版本综合排名第一。若追求单任务最高精度,可直接选用此模型。
- 小模型的“可塑性”优势:模型体积越小,通过微调获得的性能提升往往越显著。这意味着,如果您受限于硬件只能使用 1B–3B 参数的小模型,它们通过微调“成长”的潜力巨大,足以大幅缩小与更大模型的差距。
测试背景与方法
本次研究系统地对 12个 主流小模型在 8项 任务(涵盖分类、信息抽取、开卷/闭卷问答)上进行了微调与对比,并与用于生成合成训练数据的教师大模型(GPT-OSS 120B)进行了性能比较。旨在回答四个实际问题:
- 微调后,哪个模型综合性能最强?
- 哪个模型通过微调提升最大(最具“可塑性”)?
- 在不进行微调时,哪个模型的零样本/少样本基础能力最好?
- 经过微调的最优学生模型,能否追上甚至超越教师模型?
受测模型清单:
- Qwen3 系列:Qwen3-8B、Qwen3-4B-Instruct-2507、Qwen3-1.7B、Qwen3-0.6B(已关闭“思考”模式以确保对比公平性)
- Llama 系列:Llama-3.1-8B-Instruct、Llama-3.2-3B-Instruct、Llama-3.2-1B-Instruct
- SmolLM2 系列:SmolLM2-1.7B-Instruct、SmolLM2-135M-Instruct
- Gemma 系列:gemma-3-1b-it、gemma-3-270m-it
- Granite:granite-3.3-8b-instruct
评估指标:
- 基础分:模型仅使用提示词(少样本)时的表现。
- 微调分:模型使用教师模型生成的1万条合成数据训练后的表现。
测试涵盖 TREC、Banking77、Ecommerce、Mental Health(分类)、文档理解、HotpotQA、Roman Empire QA、SQuAD 2.0(问答)共8个基准。最终结果通过计算每项任务的单独排名平均值(名次越低越好),并给出95%置信区间进行汇总。
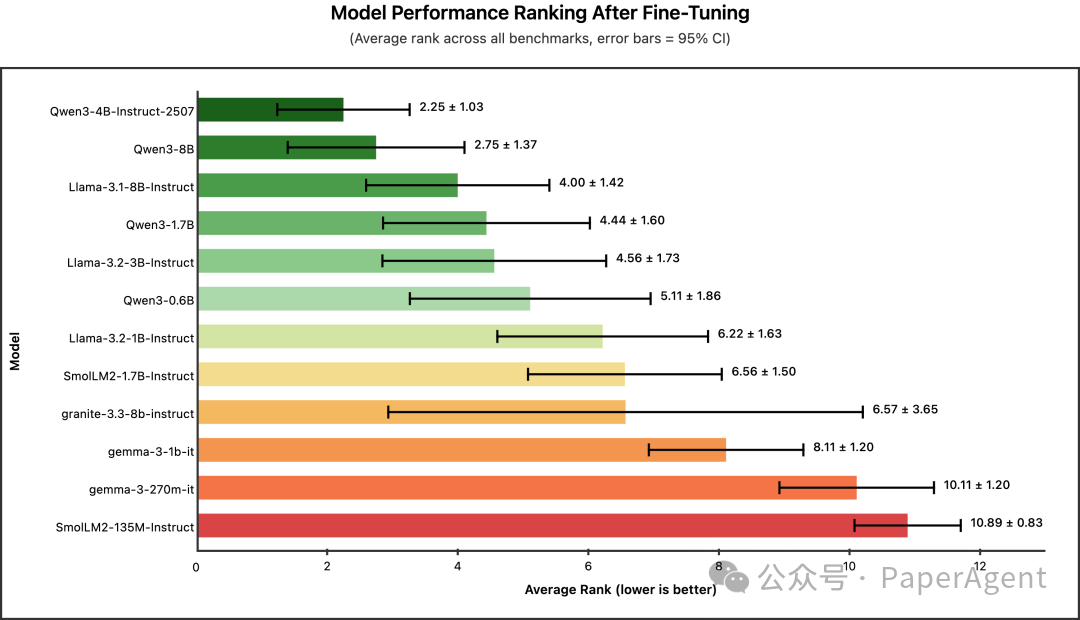
问题一:微调后谁最强?
冠军:Qwen3-4B-Instruct-2507(平均名次 2.25)
| 模型 |
平均名次 |
95% 置信区间 |
| Qwen3-4B-Instruct-2507 |
2.25 |
±1.03 |
| Qwen3-8B |
2.75 |
±1.37 |
| Llama-3.1-8B-Instruct |
4.00 |
±1.42 |
| Qwen3-1.7B |
4.44 |
±1.60 |
| Llama-3.2-3B-Instruct |
4.56 |
±1.73 |
| Qwen3-0.6B |
5.11 |
±1.86 |
结论:Qwen3 家族在微调后表现强势,其中4B版本甚至略优于8B版本,这表明2024年7月25日发布的新版 Qwen3-4B 在知识蒸馏场景下具有独特优势。若您的GPU内存允许部署约4B参数的模型,且追求最高任务精度,Qwen3-4B-Instruct-2507 是直接选择。
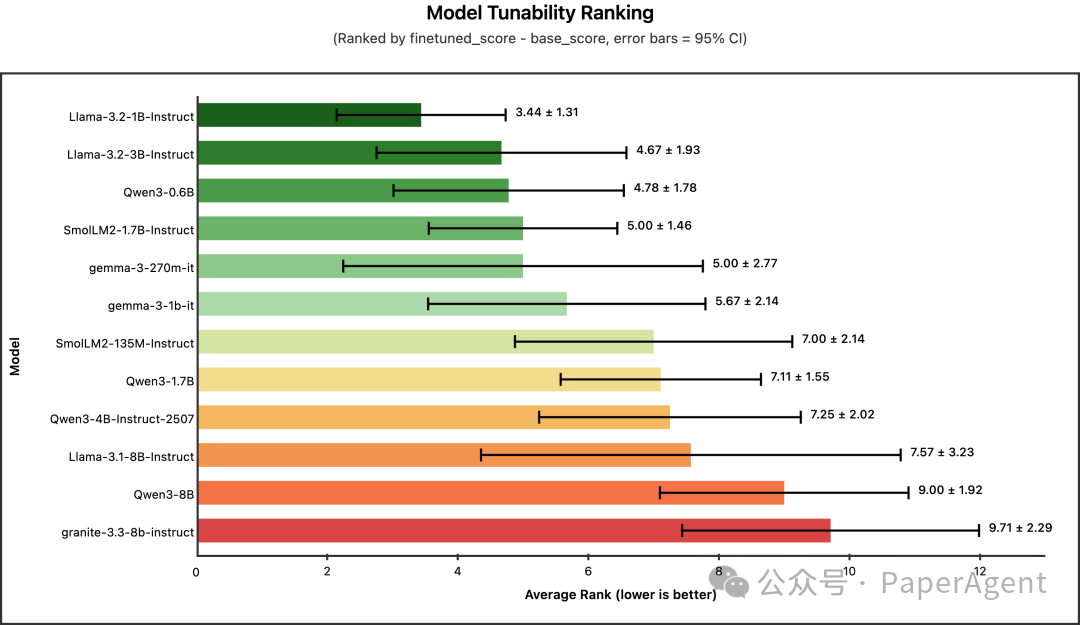
问题二:谁最“可塑”?(微调提升最大)
冠军:Llama-3.2-1B-Instruct(平均名次 3.44)
此处“可塑性”定义为微调后的排名提升幅度(微调分排名 - 基础分排名)。基础能力越弱(排名差),通过微调提升的潜力(空间)越大。
| 模型 |
平均名次 |
95% 置信区间 |
| Llama-3.2-1B-Instruct |
3.44 |
±1.31 |
| Llama-3.2-3B-Instruct |
4.67 |
±1.93 |
| Qwen3-0.6B |
4.78 |
±1.78 |
| SmolLM2-1.7B-Instruct |
5.00 |
±1.46 |
| gemma-3-270m-it |
5.00 |
±2.77 |
结论:可塑性榜单几乎与模型尺寸顺序相反。较大的模型起点高,提升空间相对较小。如果您受硬件限制只能使用小于2B的模型,无需过分担心——这类模型通过微调实现“逆袭”的潜力最大,能有效缩小与更大模型的性能差距。
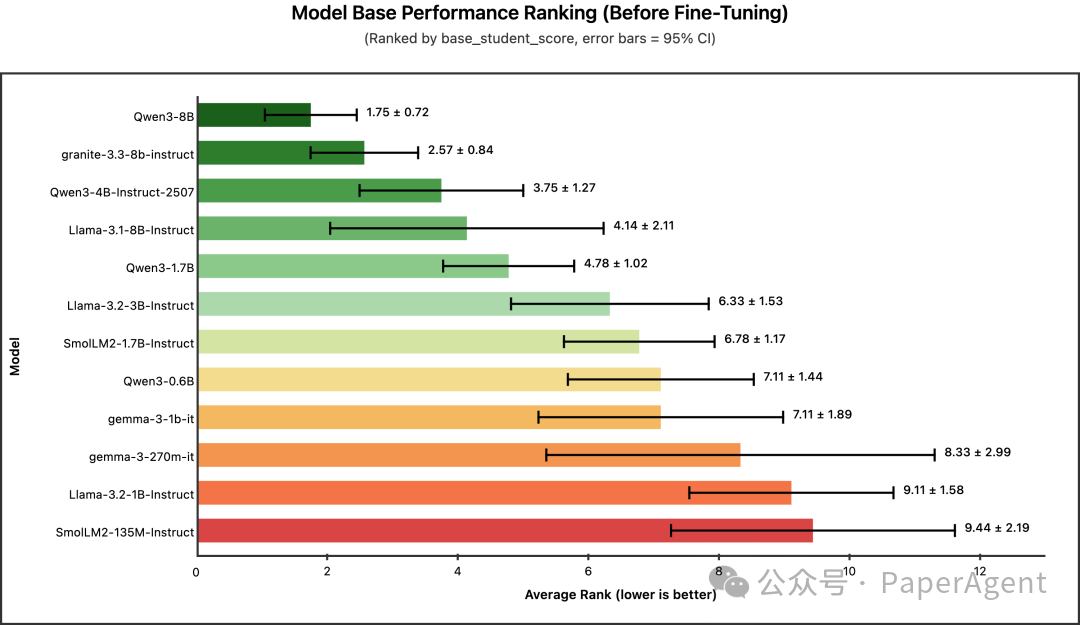
问题三:谁的基础最好?(零样本/少样本)
冠军:Qwen3-8B(平均名次 1.75)
| 模型 |
平均名次 |
95% 置信区间 |
| Qwen3-8B |
1.75 |
±0.72 |
| granite-3.3-8b-instruct |
2.57 |
±0.84 |
| Qwen3-4B-Instruct-2507 |
3.75 |
±1.27 |
| Llama-3.1-8B-Instruct |
4.14 |
±2.11 |
| Qwen3-1.7B |
4.78 |
±1.02 |
结论:在不进行任何微调、仅依赖提示词的情况下,参数更大的8B级别模型稳居前列,其中 Qwen3-8B 表现最稳定(方差最小)。如果您的应用场景无法进行模型微调,那么选择更大的基础模型仍然是硬道理。但请注意,经过微调后,这种优势会被大幅削弱。
问题四:最优学生能追上老师吗?
能。 微调后的 Qwen3-4B-Instruct-2507 在8项基准测试中的7项上,性能持平或反超了教师模型 GPT-OSS-120B。
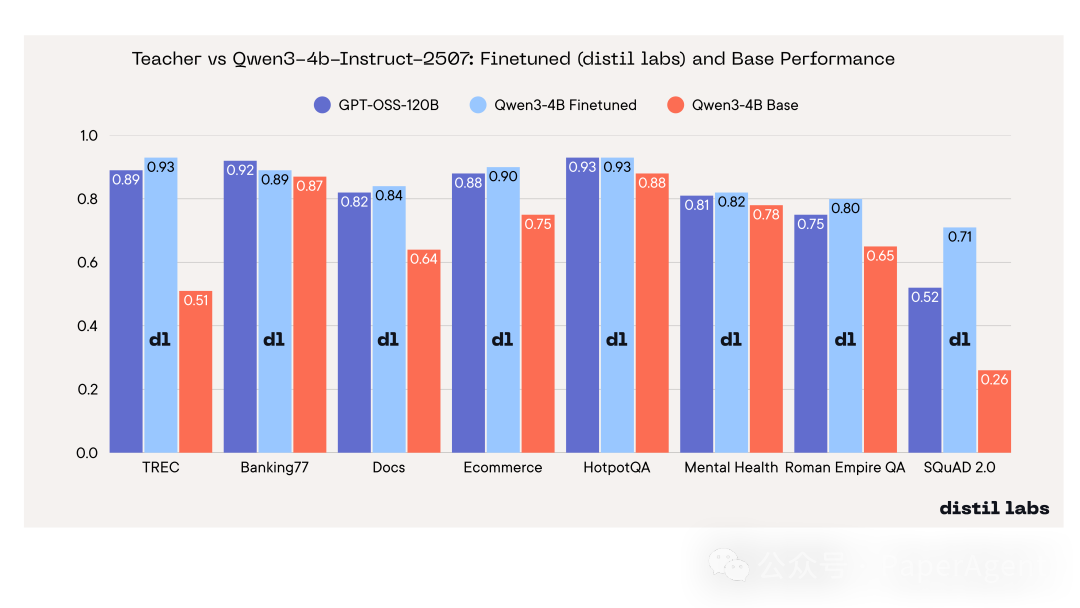
| 基准测试 |
教师模型 (GPT-OSS-120B) |
Qwen3-4B (微调后) |
Qwen3-4B (基础) |
学生-教师差值 |
| TREC |
0.89 |
0.93 |
0.51 |
+0.03 |
| Banking77 |
0.92 |
0.89 |
0.87 |
–0.03 |
| Docs |
0.82 |
0.84 |
0.64 |
+0.02 |
| Ecommerce |
0.88 |
0.90 |
0.75 |
+0.03 |
| HotpotQA |
0.93 |
0.93 |
0.88 |
+0.00 |
| Mental Health |
0.81 |
0.82 |
0.78 |
+0.01 |
| Roman Empire QA |
0.75 |
0.80 |
0.65 |
+0.05 |
| SQuAD 2.0 |
0.52 |
0.71 |
0.26 |
+0.19 |
结论:一个仅4B参数的模型,在经过得当的微调训练后,能够在多数任务上持平甚至超越体积达30倍的教师大模型。其推理成本仅为教师的约1/30,并且可以实现完全的私有化部署,这对于边缘计算和成本敏感场景意义重大。
实战选型指南
| 您的限制条件 |
推荐模型 |
理由 |
| 追求最高任务精度 |
Qwen3-4B-Instruct-2507 |
微调后综合性能最强 |
| 算力极其紧张(需<2B模型) |
Llama-3.2-1B 或 Qwen3-0.6B |
可塑性最高,微调收益最大 |
| 无法进行模型微调 |
Qwen3-8B |
零样本/少样本基础能力最强 |
| 极端边缘部署(如手机、IoT) |
Qwen3-0.6B |
体积最小,仍具备良好的微调潜力 |
测试细节与未来计划
训练细节:所有模型均采用统一的蒸馏流程。由教师模型(GPT-Oss-120B)为每项任务生成1万条合成数据用于训练。训练配置为4个epoch,学习率5e-5并采用线性衰减,使用LoRA技术(rank=64)。训练集与测试集严格隔离。
基准测试的持续演进:本次测试是一个起点,我们正在持续进行以下方面的加固:
- 扩展模型池:小模型领域迭代迅速,后续计划加入 Qwen3.5、Phi-4、Mistral 等新兴模型。
- 增加评估轮次:目前每项基准的平均运行次数有限,计划加大迭代量以进一步缩小置信区间,提升结果稳定性。
- 补充任务场景:计划加入文本摘要、代码生成、多轮对话等更多实际应用场景,使模型排名更具全面性和参考价值。
总结
基础模型之间固然存在性能差异,但通过有效的微调,这些差距能够被迅速缩小。本次基准测试清晰地表明:
- Qwen3-4B-Instruct-2507 是当前综合性能最强的选择,能够在单张消费级GPU上达到120B级别教师模型的水平。
- 参数极小的模型(如 Llama-3.2-1B)凭借其高可塑性,通过微调可以实现显著的性能跃升。
核心洞见:对于特定任务而言,精心的微调比单纯选择更大的基础模型更为重要。 一个经过良好微调的1B模型,其性能完全可以超越仅使用提示词的8B模型。
基准测试原始报告参考:Distillabs AI Blog |  发表于 2025-12-12 22:06:28
|
查看: 271|
回复: 0
发表于 2025-12-12 22:06:28
|
查看: 271|
回复: 0
