2025年12月,SK海力士副社长Kim Cheon-sung在“2025人工智能半导体未来技术会议(AISFC)”上透露,与NVIDIA联合开发的下一代AI NAND(AI-N P)将于2026年底推出样品,性能可达现有企业级SSD的8-10倍;计划在2027年底量产的第二代产品,性能更将实现惊人的30倍跃升,IOPS(每秒输入/输出操作次数)有望突破1亿大关。此次合作直指当前AI产业发展中的核心痛点——存储性能瓶颈,或将重构未来AI数据中心的架构逻辑。

当前,AI产业已清晰分化出数据中心与端侧两大主要赛道,但无论哪一条,都共同面临着“存储性能增长滞后于算力飙升”的严峻挑战。以数据中心为例,主流高性能企业级SSD的峰值IOPS仅在300万左右,而AI计算核心所依赖的DRAM内存,其IOPS可达数十亿级别,两者存在数个数量级的性能鸿沟。这导致昂贵的GPU算力时常因等待数据而闲置,显著推高了AI基础设施的总体拥有成本。
正是为了填补这一“算力与存储”之间的巨大性能缺口,作为全球HBM领导者的SK海力士,与掌握AI算力核心的NVIDIA展开了深度合作。双方联手开发AI NAND,旨在打造一套能够真正适配AI高强度数据处理需求的专用存储解决方案。
SK海力士为此规划了覆盖“性能、带宽、容量”三大维度的“AIN家族”产品线:
- AI-N P(高性能型):专注解决大规模AI推理场景的海量数据IO瓶颈,是与NVIDIA合作的核心方向。
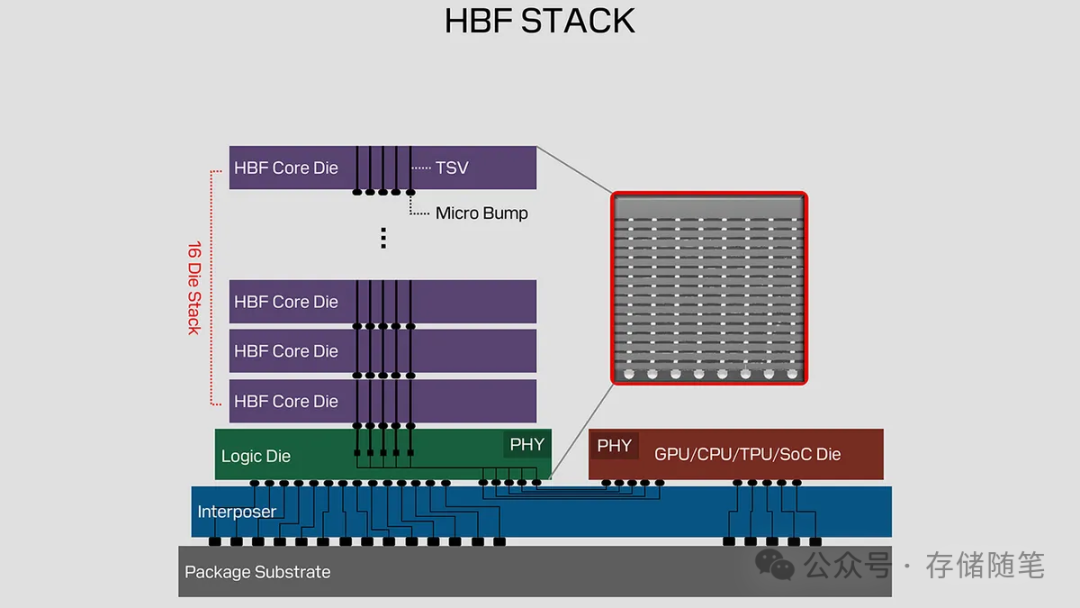
- AI-N B(高带宽型):又称HBF,借鉴HBM堆叠技术,通过堆叠NAND闪存来提升带宽,主攻AI训练与推理中的内存扩展场景。
- AI-N D(高容量低成本型):聚焦存储AI训练所需的海量数据集,通过QLC等先进技术实现PB级容量,旨在降低数据湖存储成本。

其中,AI-N P被置于优先推进的位置。其性能飞跃并非简单的参数优化,而是基于“NAND闪存+控制器”的全架构重构。传统SSD的性能受限于NAND的并行读写能力和控制器的调度效率。AI-N P则针对AI工作负载高并发、低延迟的批量数据处理特性,重新设计了底层架构,可能包括采用更高并行度的NAND阵列以及优化控制器的多通道调度算法,使存储设备能更好地匹配AI计算节奏。

实现高IOPS目标离不开高速接口的支撑。AI-N P将基于PCIe Gen6接口开发。相比当前主流的PCIe Gen4,PCIe Gen6不仅带宽翻倍,其引入的PAM4调制、FLIT模式等技术还能有效降低数据传输延迟,为达到2500万乃至1亿IOPS提供了坚实的物理层基础。
目前,SK海力士与NVIDIA正在推进AI-N P的联合PoC测试。这种“算力+存储”的深度协同模式极具价值,它能确保AI-N P与NVIDIA的GPU、AI框架及数据中心管理系统实现无缝兼容,避免出现性能达标但生态脱节的局面,是解决AI基础设施系统性瓶颈的最优路径之一。
我们可以通过一组对比数据直观感受AI-N P带来的性能突破:
- 当前主流企业级SSD:峰值IOPS约300万。
- 2026年底AI-N P样品:目标2500万IOPS,提升8-10倍。
- 2027年底第二代量产品:目标1亿IOPS,提升约33倍。
这一突破意味着存储IOPS将从“百万级”迈入“亿级”,大幅缩小了与DRAM的性能差距。对于AI数据中心而言,GPU算力利用率有望显著提升,从而支持更复杂、更大规模的AI模型推理应用。
除了AI-N P,SK海力士与SanDisk联合推进的AI-N B也值得关注。其Alpha版本计划于2026年1月底发布,2027年推出样品。AI-N B与AI-N P形成互补,前者解决高带宽需求,后者解决高并发IOPS需求。据悉,双方正致力于推动AI-N B的标准化工作,这对其未来生态建设与普及至关重要。

SK海力士与NVIDIA的此次合作,影响可能远超单一产品:
- 破解基础设施瓶颈:高性能AI存储将提升算力利用率,降低AI计算成本,加速大模型等技术在更多行业的规模化落地。
- 重塑存储竞争格局:推动存储行业从通用产品竞争转向“场景化定制”的新赛道,AI存储成为高附加值领域。
- 引领协同开发模式:“算力厂商与存储厂商深度协同”将成为优化AI基础设施的主流方向,带动更多产业链合作。
总结来看,SK海力士与NVIDIA通过“全架构重构+PCIe Gen6+生态协同”的组合拳,正试图一举击穿AI产业的存储性能天花板。从2026年的样品到2027年的量产产品,这一技术路线图既展现了雄心,也反映了市场的迫切期待。这场由产业巨头引领的存储变革,已悄然拉开序幕,其后续的PoC进展、样品实测表现以及行业生态的响应,都值得持续关注。 |  发表于 2025-12-14 21:48:25
|
查看: 225|
回复: 0
发表于 2025-12-14 21:48:25
|
查看: 225|
回复: 0
