为什么在AI算力领域,英伟达似乎总是难以撼动?一份最新的成本分析揭示了令人惊讶的事实:在特定条件下,于英伟达平台上每花费一美元所获得的性能,可能高达AMD平台的15倍。
尽管英伟达硬件单价更贵,但综合算力产出与成本来看,构建一套完整的英伟达解决方案,反而可能更省钱。
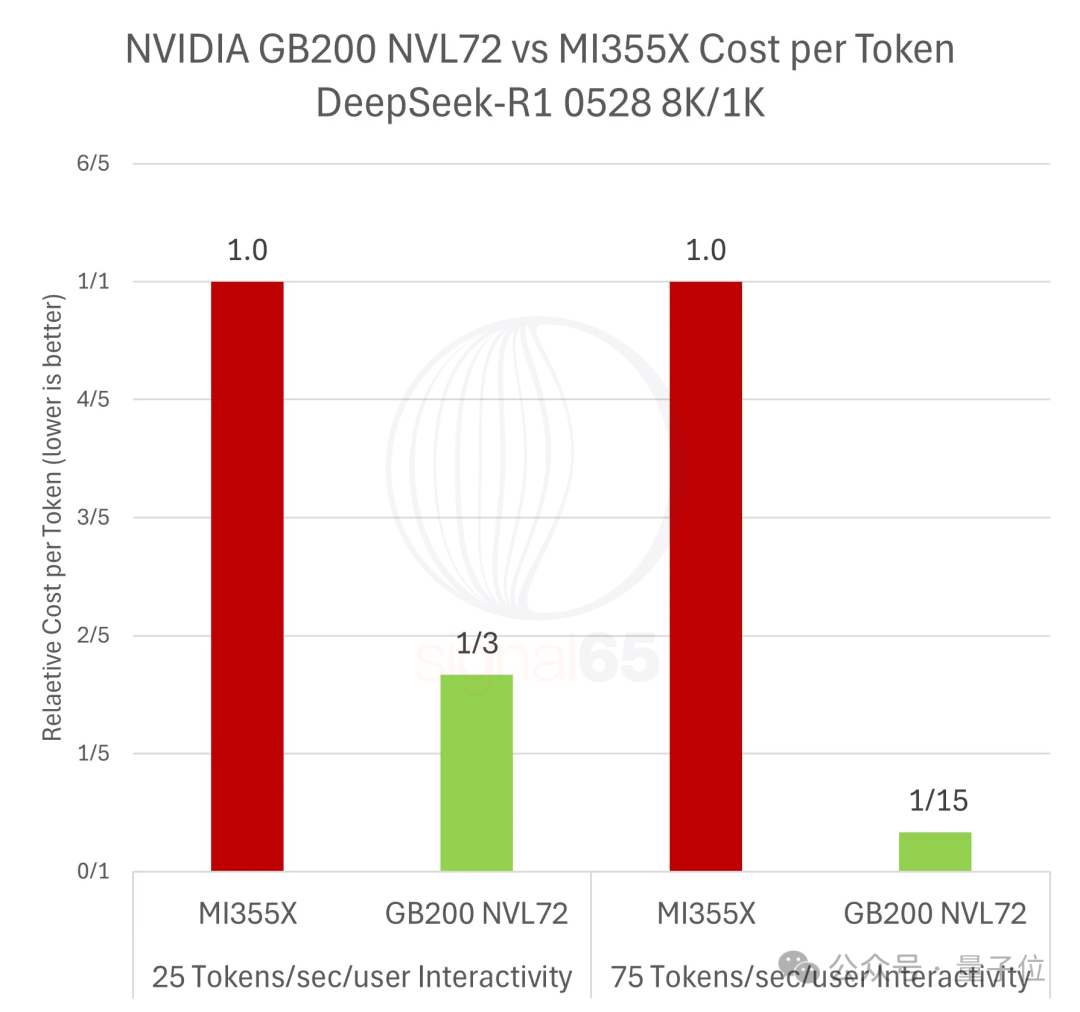
Signal65发布的一份详尽报告揭示了这一现实。报告基于SemiAnalysis InferenceMAX的公开基准测试数据,时间跨度从2025年10月到12月,覆盖了从传统密集模型到前沿MoE(专家混合)推理模型的全场景。其核心结论是,在运行前沿推理模型时,生成同样数量的token,英伟达平台的成本可能只有AMD的十五分之一。

这似乎印证了英伟达CEO黄仁勋那句著名的“买的越多,省的越多”。

MoE时代来临:8卡系统遭遇扩展天花板
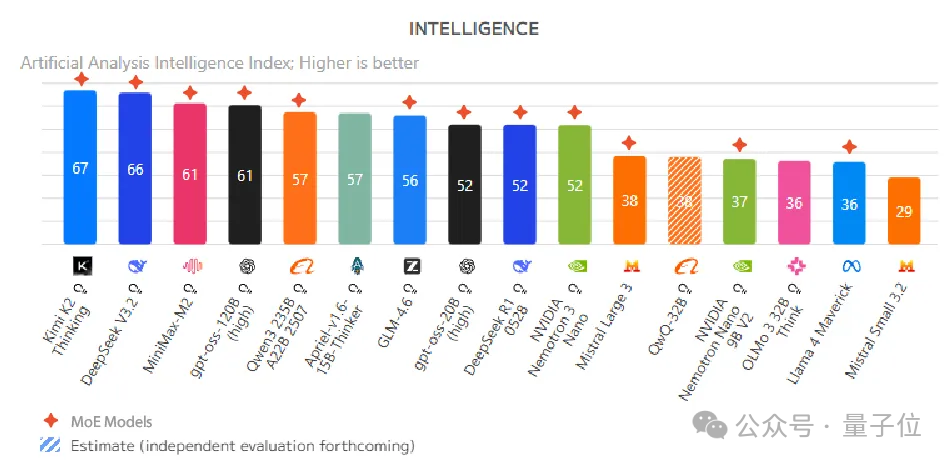
当前,AI模型正经历一场架构革命。观察最新的Artificial Analysis智能度排行榜会发现,排名前十的开源模型几乎清一色是MoE(Mixture of Experts)推理模型。
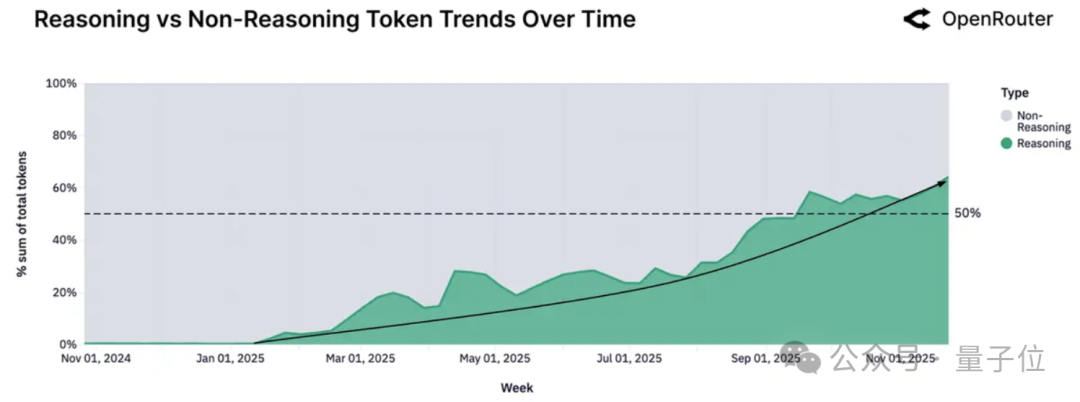
来自OpenRouter的数据进一步证实了这一趋势:超过50%的token流量正在被路由到推理模型上,并且这一比例仍在持续增长。
MoE架构的核心思想是将庞大的模型参数拆分为多个专门化的“专家”子网络,每个输入的token只激活其中一小部分专家。以DeepSeek-R1为例,它拥有6710亿总参数,但每个token仅激活约370亿参数。这种设计让它能够以相对更低的计算成本,提供接近前沿水平的智能。
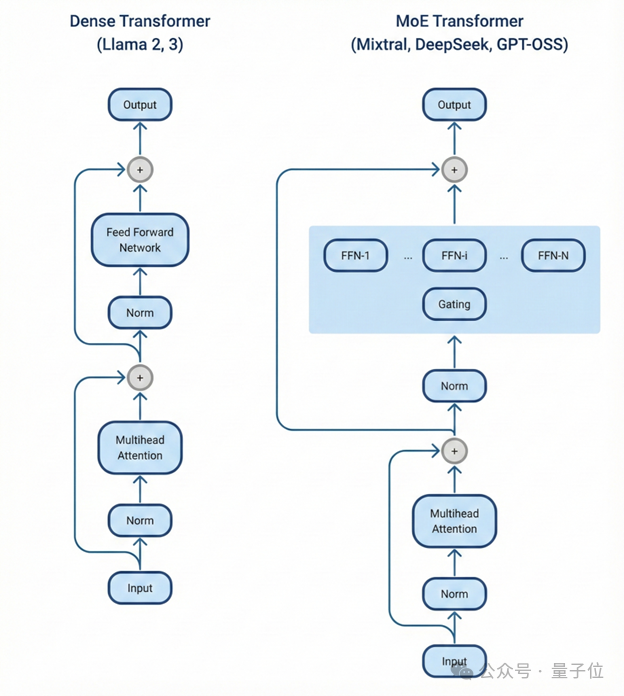
然而,问题也随之产生。当这些“专家”网络分布在不同GPU上时,GPU之间的通信延迟会导致计算单元空闲等待数据,这些空闲时间直接转化为了服务商的运营成本。报告指出,无论是英伟达B200还是AMD MI355X,所有基于8卡构建的系统在超出单节点规模后,都会撞上明显的“扩展天花板”。
英伟达GB200 NVL72的解决方案是将72块GPU通过NVLink高速互联技术连接成一个单一域,提供高达130 TB/s的聚合带宽。在软件层面,整个系统可以像一块巨型GPU一样被调度和使用。配合英伟达Dynamo推理框架的分离式预填充-解码调度以及动态KV缓存路由技术,这套架构旨在有效突破传统多卡系统间的通信瓶颈,这对于运行复杂的 MoE模型 至关重要。
模型越复杂,英伟达优势越显著
报告测试了三类典型模型,结果显示:模型越复杂、对通信带宽要求越高,英伟达平台的优势就越明显。
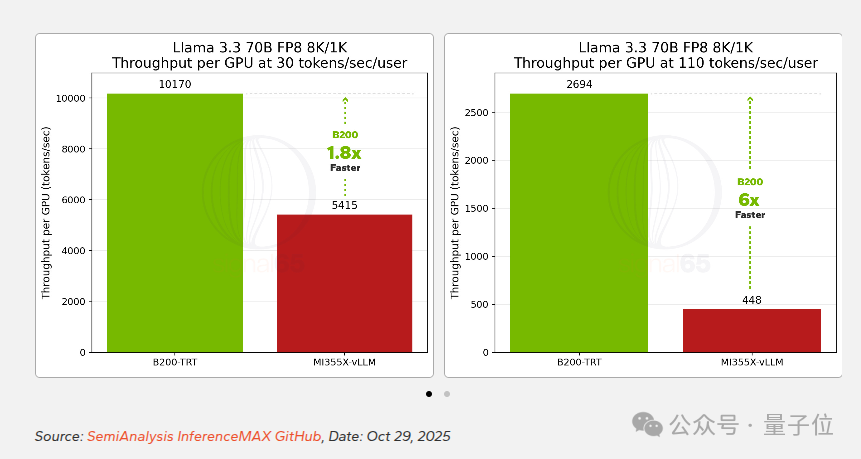
在传统的密集模型 Llama 3.3 70B 上,英伟达B200对比AMD MI355X的领先幅度相对温和。在基线交互性(30 tokens/sec/user)下,B200的性能约为MI355X的1.8倍;当交互性要求提升到110 tokens/sec/user时,这一差距扩大到了6倍。
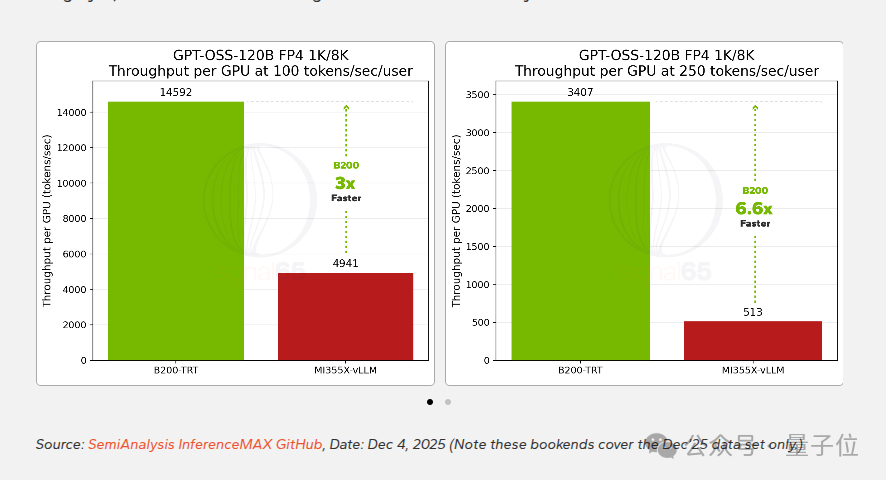
到了中等规模的MoE模型 GPT-OSS-120B,差距开始变得显著。该模型拥有1170亿总参数,每个token激活约51亿参数。根据2025年12月的测试数据,在100 tokens/sec/user的交互性下,B200的性能接近MI355X的3倍。在更符合推理模型高响应需求的250 tokens/sec/user条件下,差距进一步扩大到6.6倍。
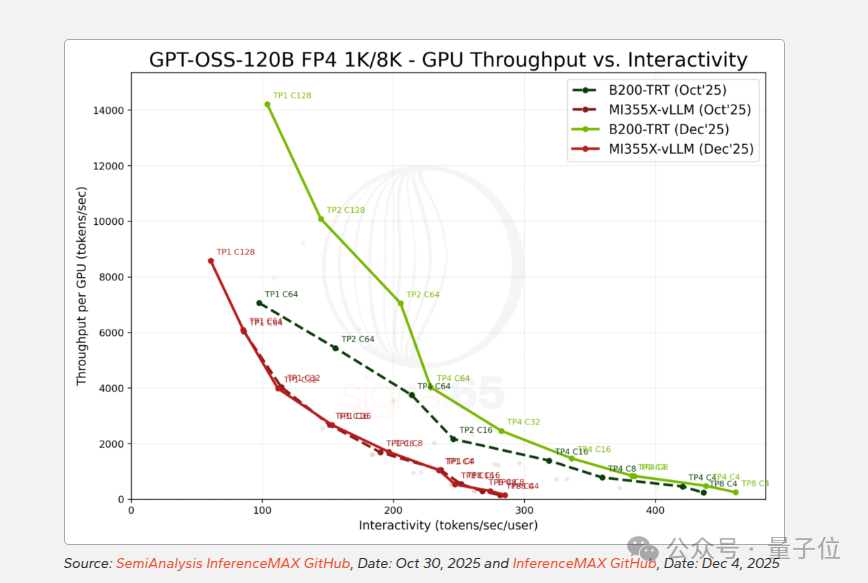
值得注意的是,从10月到12月,两个平台的软件栈均有优化,绝对性能均有提升。英伟达的峰值吞吐量从约7000 tokens/sec跃升至14000以上,AMD则从约6000提升到8500左右。然而,由于英伟达优化幅度更大,双方的实际性能差距反而拉大了。
真正的分水岭出现在前沿的复杂推理模型 DeepSeek-R1 上。这款模型集MoE路由、超大参数规模和高强度推理生成于一身,对基础设施的通信带宽和调度能力提出了极为苛刻的要求。测试结果令人震惊:
- 在25 tokens/sec/user交互性下,GB200 NVL72的每GPU性能是上一代H200的10倍,是MI325X的16倍。
- 在60 tokens/sec/user下,相比H200的优势扩大到24倍,相比MI355X达到11.5倍。
- 在75 tokens/sec/user下,GB200 NVL72的性能是B200单节点配置的6.5倍,是MI355X的28倍。
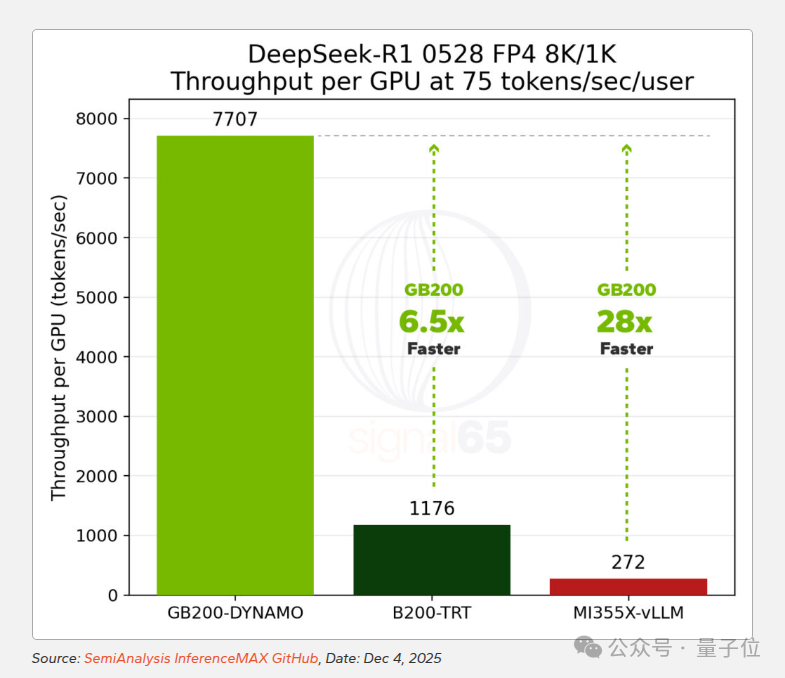
更关键的是,GB200 NVL72能够达到竞争平台难以企及的交互性水平。报告指出,它在28卡配置下可以实现超过275 tokens/sec/user的输出,而MI355X在相近的吞吐量水平下,峰值交互性只能达到75 tokens/sec/user。
Token经济学:单价贵1.86倍,单Token成本省15倍
从直觉上看,性能更强的硬件平台理应更贵。事实也确实如此:根据Oracle Cloud的公开定价,GB200 NVL72的每GPU每小时价格为16美元,MI355X为8.60美元,前者价格是后者的1.86倍。参照另一家云服务商CoreWeave的定价,GB200 NVL72相比上一代H200的价格也贵了约1.67倍。
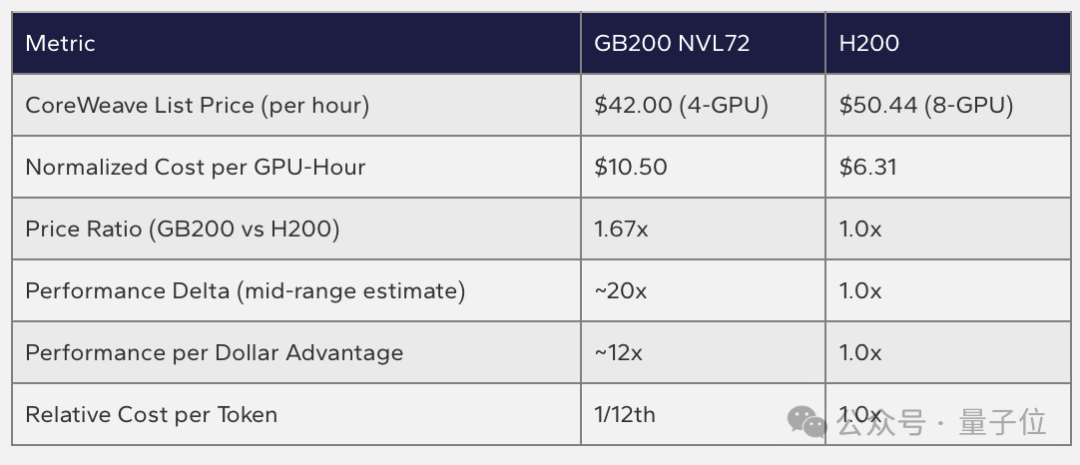
但报告通过计算揭示了一个反直觉的结论:不能只看单价,而要看“每美元能买到多少性能”。
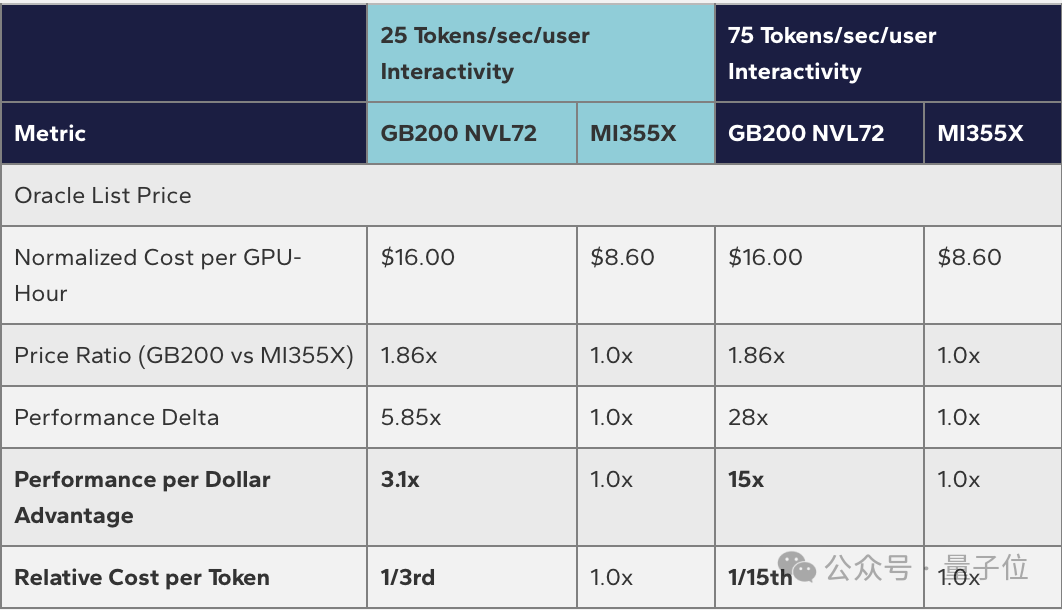
在25 tokens/sec/user的交互性下,GB200 NVL72的性能优势为5.85倍。用5.85倍性能除以1.86倍的价格溢价,得出其“每美元性能”仍是MI355X的3.1倍。这意味着生成相同数量的token,英伟达平台的成本约为AMD的三分之一。
而在75 tokens/sec/user的高要求交互性下,28倍的性能优势除以1.86倍的价格溢价,“每美元性能”达到了MI355X的15倍。这意味着,在这种场景下,生成同等数量token的成本,英伟达平台只有AMD的十五分之一。
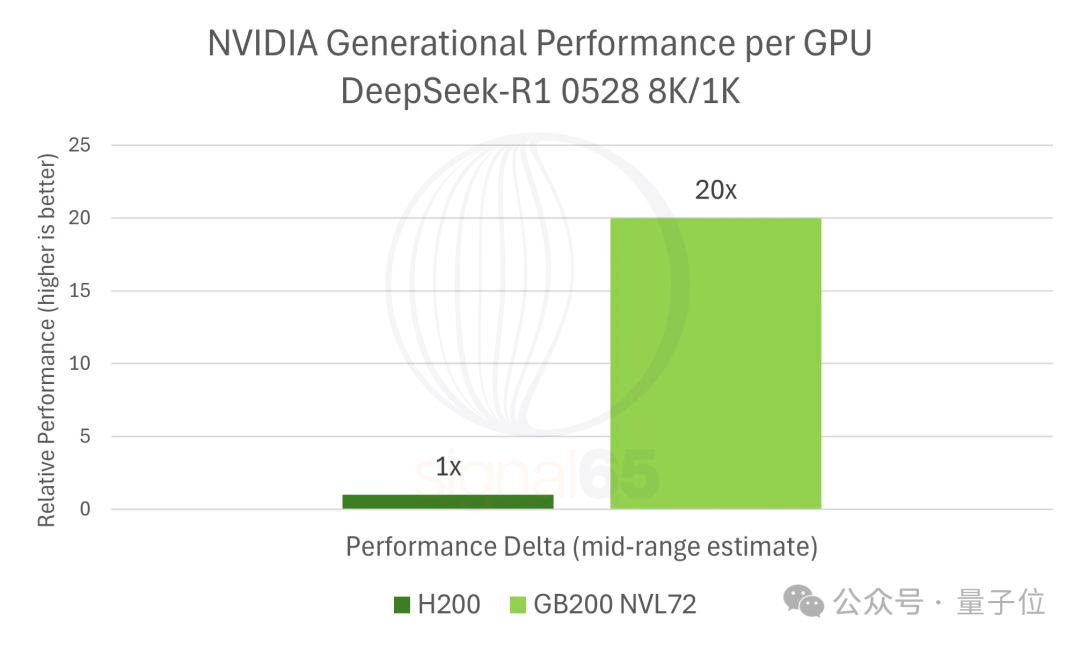
与自家上一代产品对比,结果同样惊人。报告估算,在运行DeepSeek-R1这类典型工作负载时,GB200 NVL72相比H200的性能提升约为20倍。
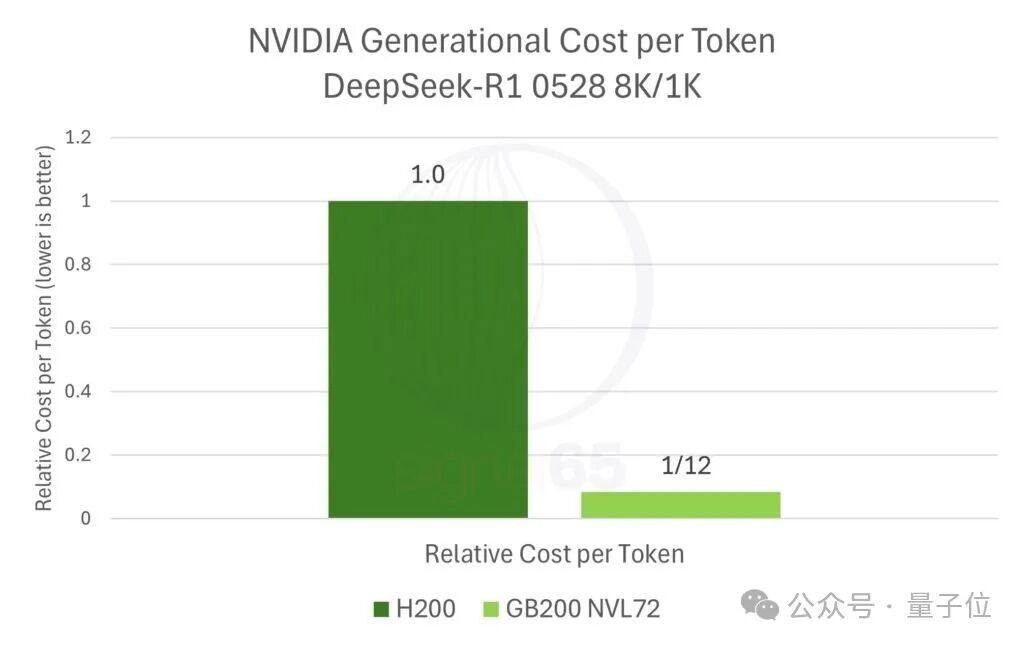
考虑到GB200 NVL72的价格仅上涨了约1.67倍,其“每美元性能”提升约12倍,使得单token成本降至H200时代的十二分之一。
结论:端到端平台设计成为关键
MoE推理模型的时代让网络通信成为推理成本的瓶颈,而英伟达机柜级的GB200 NVL72解决方案恰好瞄准了这一痛点。价值的衡量标准正在从单纯的算力峰值(FLOPS)转向更实际的“每美元能产出多少智能(Tokens)”。
报告在结论中也指出,AMD的竞争力并未被完全否定——在运行传统密集模型或对峰值算力容量更敏感的场景下,MI325X和MI355X仍有其用武之地。此外,AMD的机柜级解决方案Helios也正在开发中,有望在未来12个月内帮助缩小差距。
然而,就当前最前沿、最复杂的AI推理模型而言,从芯片、高速互联到软件框架的 端到端平台化设计,已经成为了决定最终成本效益的关键因素。这不仅仅是硬件竞赛,更是一场涵盖 计算性能 、互联带宽与软件生态的全面竞争。
对于密切关注 人工智能 与 高性能计算 趋势的开发者与技术决策者而言,这份报告提供了重要的成本视角。未来,如何平衡硬件采购成本与实际的AI任务产出效率,将成为构建高效 云计算 基础设施的核心课题。欢迎在 云栈社区 的 开发者广场 继续探讨AI算力的最新动态与技术选型。
参考链接:
[1] https://signal65.com/research/ai/from-dense-to-mixture-of-experts-the-new-economics-of-ai-inference/
 发表于 2026-1-4 00:26:20
|
查看: 278|
回复: 0
发表于 2026-1-4 00:26:20
|
查看: 278|
回复: 0
