
机器学习在量化金融中的成功,极大地依赖于对海量历史数据的利用。然而,传统的分析方法通常建立在“训练数据与测试数据服从同一分布”的独立同分布假设之上。现实中的金融市场由复杂的交易者互动驱动,呈现出高度的动态演化特性,这导致了严重的概念漂移——即数据随时间变化,其联合概率分布并不稳定。当这个基础假设失效时,基于静态历史数据训练的模型很容易过拟合,在面对未知市场环境时也显得鲁棒性不足。“历史数据是不够的”这一核心观点,恰恰点明了数据生成机制必须能够随市场演变而自我进化,而非仅仅依赖过去的观测。
尽管数据增强在计算机视觉领域已成为标准操作,但在量化金融流程中却尚未被广泛集成。主要的障碍在于,缺乏针对时间序列特别是金融数据的公认增强基准,而不恰当的增强又极易破坏金融数据的保真度和内在相关性。现有的自适应方法要么仅依赖重采样而不生成新样本,要么采用固定不变的增强策略,无法根据模型状态和数据分布的变化进行动态调整。
本研究填补了这一空白,设计了一个位于任务模型验证循环内的学习型控制器。该控制器包含一个自适应规划器和一个防过拟合调度器,能够依据模型反馈动态调节变换概率和强度,从而将数据增强转化为一个可控、可审计且符合金融先验的数据流组件。
一、 预备知识
1. 金融数据定义与 K 线约束
金融数据通常组织为 K 线(蜡烛图)元组(开、高、低、收)。为了维持市场的现实性,任何合成或增强后的 K 线数据都必须满足一个关键的一致性约束:最高价 ≥ 收盘价,最低价 ≤ 收盘价。这一约束保留了价格运动的短期动量、波动性和不对称性,也是本系统数据操控模块必须强制执行的核心规则。
2. 概念漂移的实证观察
通过 t-SNE 可视化技术对比金融数据(如麦当劳股价 MCD)与标准时间序列基准(如天气、电力负荷),我们可以清晰地观察到金融数据的训练集与测试集在特征空间和条件分布上都存在更显著的分离。这证实了金融数据确实具有更强烈的概念漂移特性。
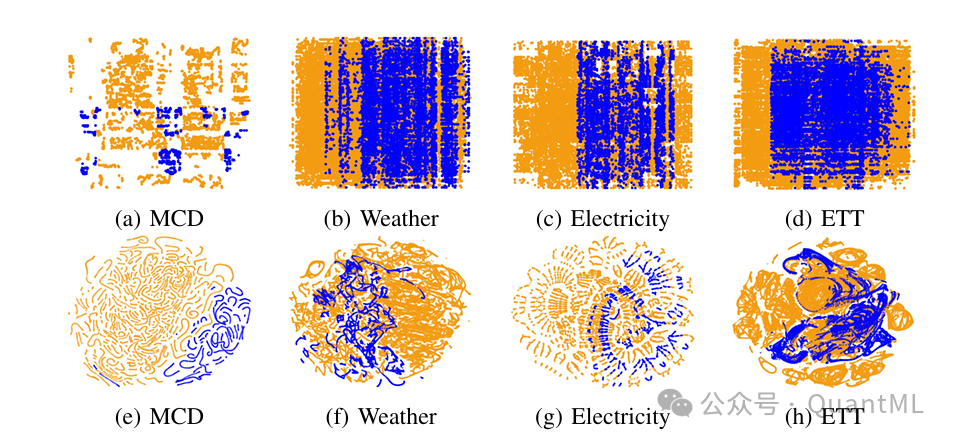
3. 验证集与测试集的邻近性
为了论证“利用验证集反馈来指导测试集表现”这一做法的合理性,研究采用了群体稳定性指数、Kolmogorov-Smirnov 统计量和最大均值差异三种指标,来量化“训练集-测试集”与“验证集-测试集”之间的分布距离。实验结果表明,无论是在股票还是加密货币数据集中,验证集的分布统计特性都比历史训练数据更接近未来的测试数据。这一发现为基于验证集反馈的自适应增强和规划器更新提供了坚实的统计学基础。
二、 方法论
本研究的核心贡献在于构建了一个闭环的自适应数据流系统。该系统通过一个双层优化方案,交替训练任务模型与增强策略规划器。
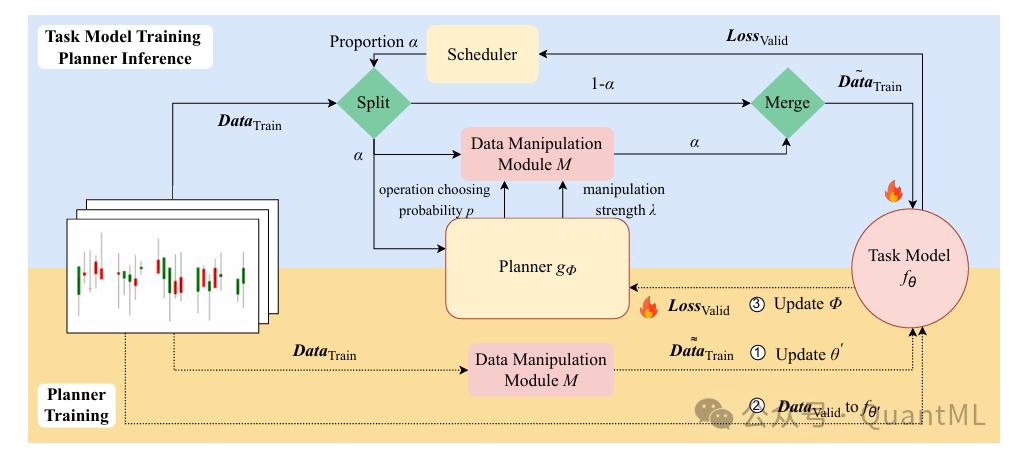
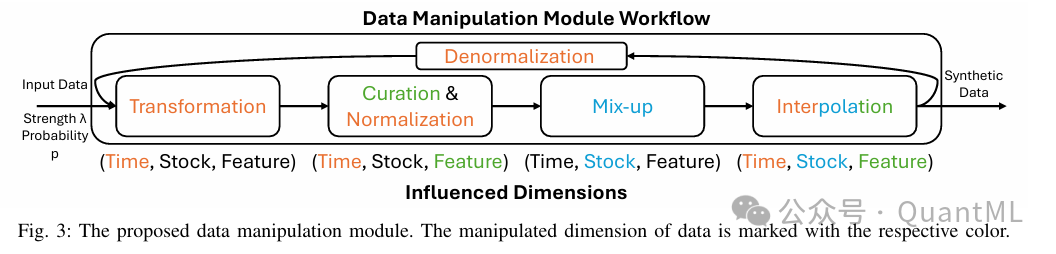
1. 参数化数据操控模块
不同于简单的增强操作堆叠,这个模块被设计为一个参数化的合成单元,旨在嵌入金融先验知识以确保数据的真实性和统计多样性。该模块由操作选择概率矩阵和操控强度参数控制,包含以下四个紧密耦合的层级:
-
变换层:
应用目标不变的单资产变换操作,旨在提升模型训练的泛化能力。具体包括:
- 抖动: 引入受控噪声以提高信号辨别力。
- 缩放与幅度扭曲: 模拟波动率变化和非线性价格动态。
- 排列: 在保持局部连续性的同时打破严格的时序,反映市场演化的部分随机性。
- STL 增强: 基于季节性-趋势分解,对残差项进行重采样,以更好地建模体制转换。
-
策展与归一化层:
在进行单资产变换后,首先强制执行 K 线一致性约束(如最高价调整为最高值)。随后,为了进行多资产混合操作,采用滚动窗口标准归一化处理数据。
-
混合层:
执行目标可变的多资产混合操作。这是本系统的创新点之一,其核心在于基于协整的目标资产采样。
- 选股机制: 对于源股票,系统根据协整检验的 p 值选择最相关的若干只股票作为候选。一个控制参数用于调节选择的偏好:偏向强协整关系(引入相关性)或弱协整关系(引入新颖性)。
- 混合操作: 包括 Cut Mix(替换片段)、Linear Mix(线性插值)、Amplitude Mix(频域幅度混合)以及相位幅度混合。
-
插值补偿层:
为了减轻混合操作可能产生的极端样本,提出了互信息感知混合策略。该策略计算原始数据与增强数据之间的互信息。如果增强数据与原始数据的语义对齐度较低,系统会自动增加原始数据的权重进行补偿。这确保了低相似度的增强对最终样本的贡献较小,从而保留任务相关的结构特征。
2. 学习型增强控制
系统通过一个双层优化问题来学习自适应增强课程,其目标是同时优化任务模型和生成增强策略的规划器。其中任务模型在训练循环中更新,而规划器则在验证循环中更新。
-
课程规划器:
规划器学习一个策略网络。其输入状态包括任务模型的高层特征表示和输入样本的统计特征(均值、波动率、动量等)。为了规避金融任务中的推断不确定性风险,规划器的损失函数设计参考了夏普比率的形式,引入了标准差惩罚项,以引导模型避开高风险的推断路径。
-
防过拟合调度器:
规划器控制操作的概率和强度,而调度器则控制数据被操控的比例。这是一个动态课程:操控比例随训练轮数增加而单调递增,意味着训练从简单(原始数据为主)逐渐过渡到困难(增强数据增多)。同时,如果当前轮次的验证集损失未明显下降(表明可能出现过拟合),调度器会移除对频繁操控的惩罚,从而允许引入更多样化的增强数据来打破过拟合。
-
联合训练机制:
为了处理不可导的操作(如选择哪个增强),采用了直通梯度估计器来优化操控强度,确保了整个系统能够进行端到端的优化。
三、 结果分析
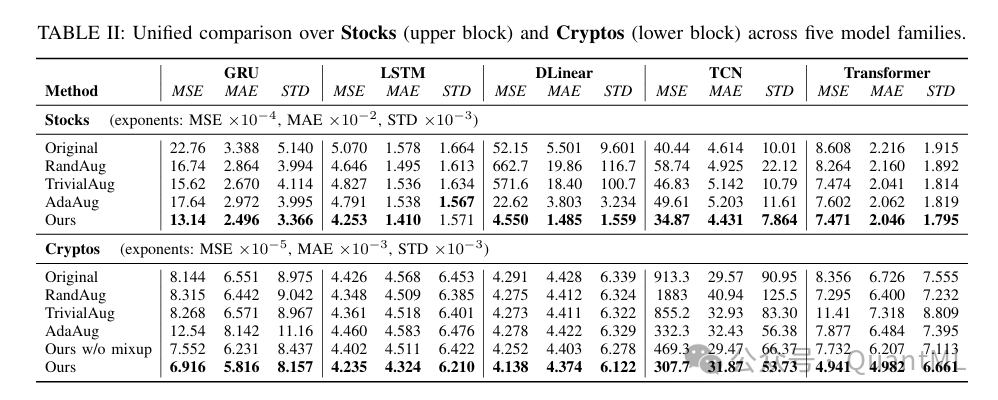
研究在两个真实的金融市场数据集上进行了广泛评估:道琼斯工业平均指数(日频数据)和主要加密货币(小时频数据)。实验对比了包括生成式模型和自动增强基准在内的多种方法,任务模型涵盖了 GRU、LSTM、DLinear、TCN 和 Transformer 五种主流架构。
1. 工作流有效性
在股价预测任务中,所提出的自适应数据流系统在所有模型架构上均取得了一致的最优性能,显著降低了预测误差。
- 模型适应性: 实验发现,像 GRU 和 Transformer 这样较强的模型对随机增强具有一定的鲁棒性,但较弱的模型在随机增强下性能反而下降。然而,本系统的自适应规划器成功地为所有模型找到了提升性能的增强策略,证明了其模型无关的通用性。
- 调度器作用: 对比固定增强比例的方法,本方法因引入了动态调度器而表现更优,证明了渐进式课程学习的重要性。
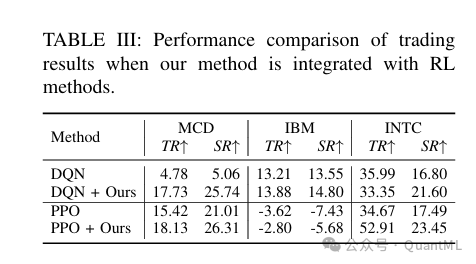
2. 强化学习交易迁移
为了评估增强策略的迁移能力,研究构建了一个单资产离散动作交易环境,并结合 DQN 和 PPO 算法进行测试。
- 风险调整收益: 在多个个股上,集成该系统后的 DQN 和 PPO 智能体在总回报和夏普比率上均有显著提升。
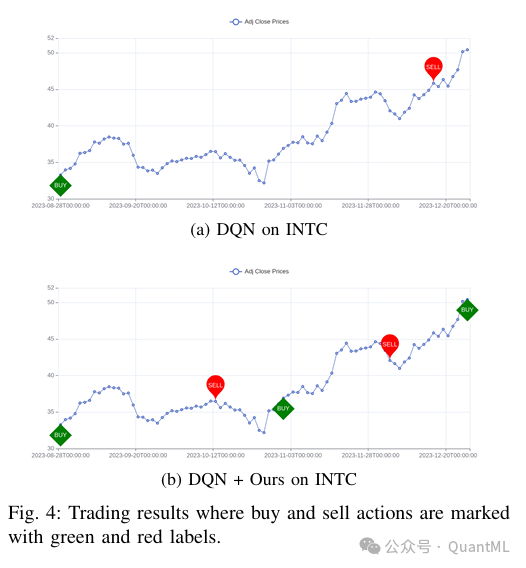
- 行为分析: 案例研究显示,该系统帮助强化学习智能体做出了更审慎的决策(例如在下跌趋势前卖出),这得益于训练阶段接触了更多样化的市场情景,缓解了概念漂移导致的泛化能力差的问题。
3. 数据保真度与质量评估
- t-SNE 分布: 增强后的训练数据在分布上更接近测试集,定性地证明了该流程有效缓解了概念漂移。
- 判别性得分: 使用事后 RNN 分类器区分真实数据与合成数据。本方法实现了最低的判别准确率(接近 50% 的随机猜测水平),表明合成数据具有极高的逼真度。
- 典型事实: 在收益率自相关性、波动率聚类和杠杆效应三个关键统计特性上,本系统生成的增强数据与真实金融数据的物理特性高度吻合,远超其他生成式模型。这证明数据挖掘与合成流程并未破坏市场的内在动力学结构。
4. 消融实验
- 移除多资产混合模块导致所有预测模型的误差一致上升,说明跨资产信息对于学习通用的时间动力学至关重要。
- 禁用规划器或调度器(退化为简单的自动增强)会导致性能显著恶化,尤其是对于数据敏感的架构。这进一步证实了在金融领域,增强策略必须是动态且针对特定模型状态进行优化的。
四、 结论
本研究提出了一种新颖的自适应数据流系统,成功弥合了量化金融中训练环境与真实市场表现之间的鸿沟。该系统是首个应用于金融时间序列管理的学习引导型数据流架构。
通过集成参数化的数据操控模块与学习型规划器-调度器,该框架构建了一个闭环反馈机制,能够随着模型的演化动态调节数据增强的强度与比例。这种设计使得数据管道能够自我调整以适应分布漂移,在整个学习过程中确保持续的数据质量和逼真的合成效果。
实验结果有力地证明,该系统不仅在预测和交易任务中提高了模型的鲁棒性和风险调整后的收益,而且生成的数据严格遵守金融市场的统计特性和典型事实。这为解决金融数据非平稳性提供了一个通用的、可扩展的自动化工作流解决方案。
在云栈社区的技术论坛中,我们持续关注并分享此类将前沿学术研究与工业实践相结合的技术方案,助力开发者应对复杂的数据挑战。
 发表于 2026-1-19 07:00:34
|
查看: 252|
回复: 0
发表于 2026-1-19 07:00:34
|
查看: 252|
回复: 0
