Transformer会是AI发展的终点吗?其核心发明者之一给出的答案是:绝对不是。
那么,仅仅在现有架构上无限扩大模型规模,是通往AGI的唯一路径吗?对这个架构研究最久的人告诉你:也不是。
作为Sakana AI的创始人、研究科学家,Llion Jones正是2017年那篇著名论文《Attention Is All You Need》的八位合著者之一。可以说,除了其他几位共同作者,没有人在Transformer上投入的研究时间比他更久。
然而,就在去年,他做出了一个重要决定:大幅减少自己在Transformer相关研究上的投入。
这并不是因为该领域已无新意,而是因为它已经变得过于拥挤。他坦言,自己某种程度上成了这项成功发明的“受害者”。他认为,当前业界对Transformer架构的执着,可能让大量研究资源陷入了“局部最优”的陷阱。
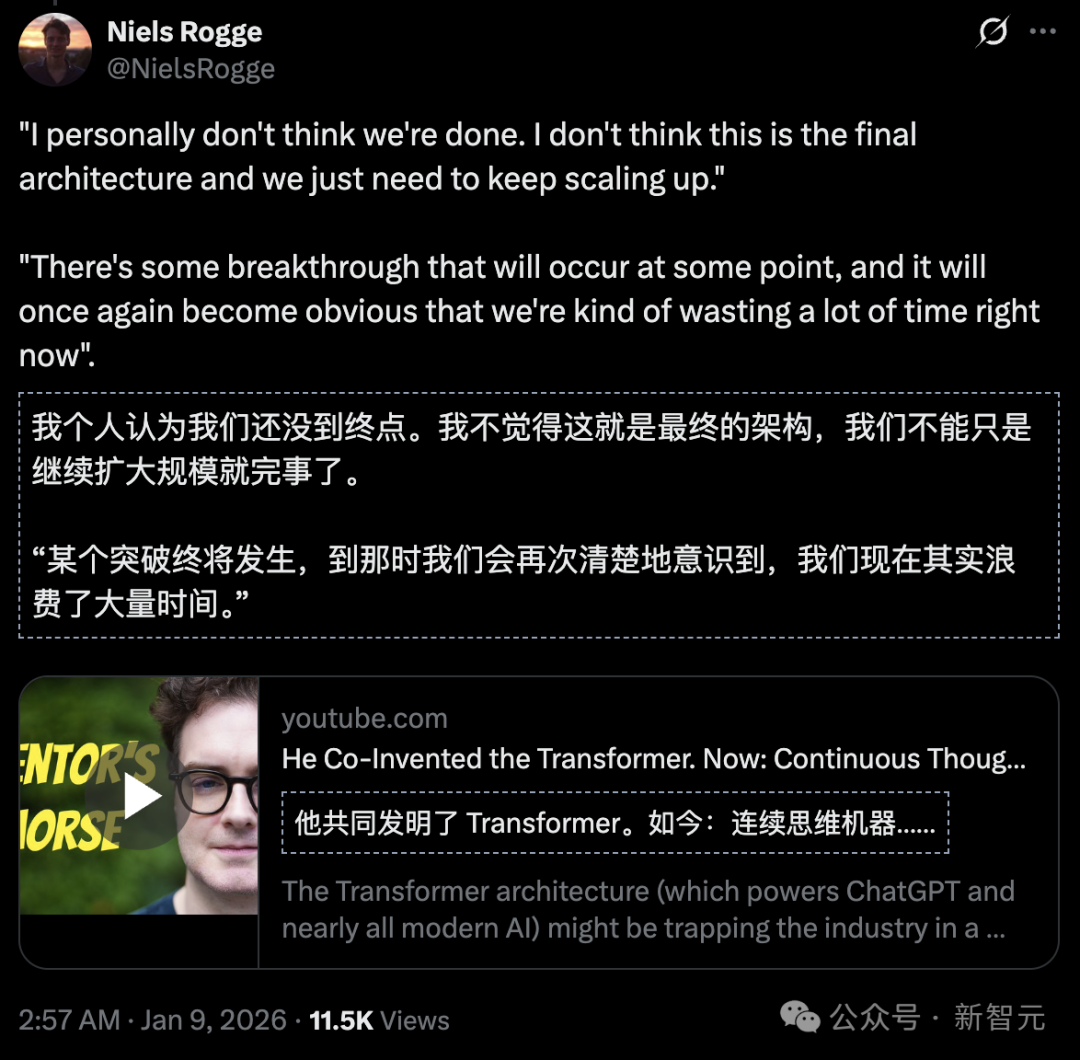
“我个人不认为我们已经走到了终点。我不觉得这就是最终的架构,我们不能只是继续扩大规模就完事了。” Jones在一次分享中表示,“某个突破终将发生,到那时我们会再次清楚地意识到,我们现在其实浪费了大量时间。”
在Transformer横空出世之前,循环神经网络(RNN)及其变体(如LSTM、GRU)是序列建模的绝对主流。RNN本身确实是AI历史上的重大突破,它让模型具备了处理序列数据的能力。
随后,整个研究社区几乎都投入到对RNN架构的改进中。但许多工作都像是在同一块基石上进行微雕——调整门控单元的位置、优化梯度流动——努力将语言建模的困惑度从1.26比特/字符提升到1.25比特/字符。
然而,当足够深的纯解码器Transformer被应用于同样的任务时,性能瞬间跃升到了1.1比特/字符的水平。于是,之前无数围绕RNN的精心优化,在那一刻似乎都失去了意义。
Jones指出,当前的论文发表趋势似乎又走上了老路:在Transformer这个“终极”架构上,进行无数细微的修改——比如调整层归一化的位置,或者对训练方式做些微小改进。
2020年,时任谷歌DeepMind的研究员Sarah Hooker提出了“硬件彩票”的概念。她认为,通往AGI的道路本不止一条,但深度神经网络恰好中了大奖——它完美契合了GPU等现代硬件的特性,从而得以蓬勃发展。

“硬件彩票”描述了一种情境:某个研究思路之所以胜出,并非因为它在所有可能方向中具有普遍优越性,而是因为它恰好与当时的软硬件生态高度兼容。
Jones则将Transformer的成功比作“架构彩票”。他担心,整个行业正在重复RNN时代的故事,陷入对同一架构的过度优化之中。
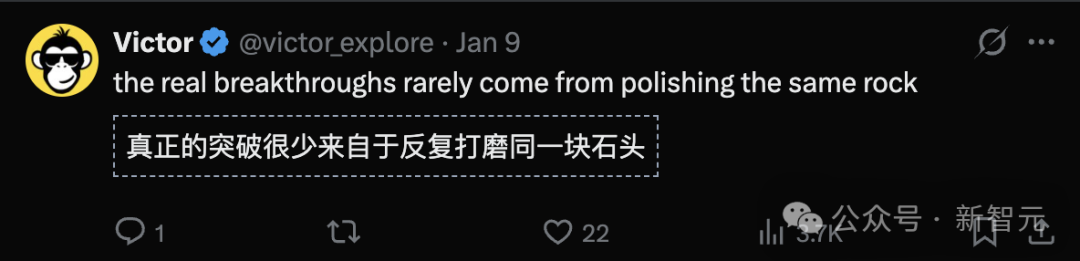
“真正的突破很少来自于反复打磨同一块石头。” 他在社交媒体上这样写道。
即便已有一些学术论文展示了在某些指标上超越Transformer的新架构,但问题在于,它们的优势还不足以让整个行业放弃成熟的Transformer生态。
原因非常现实:业界对Transformer的理解已极为深入,训练方法、微调技巧、软件工具链都已高度完善。除非新架构展现出“碾压级”的优势,否则让所有人从头换一套体系几乎是不可能的。
历史已经证明了这一点:Transformer能取代RNN,是因为性能差距大到无法忽视;深度学习的兴起也一样,当神经网络在图像识别上展现出压倒性优势后,符号主义的主流地位便不复存在。
Jones认为,Transformer的巨大成功本身,已经形成了一个难以逃脱的“引力阱”或“架构陷阱”。
“这就像有个巨大的‘重力井’,所有尝试离开的新方法都会被拉回来。哪怕你真的做出了一个效果更好的新架构,只要像OpenAI这样的巨头把Transformer的规模再扩大十倍,你的成果就可能被轻易超越。”
当前大语言模型远非通用智能
Jones进一步指出,当前的大语言模型所展现的并非真正的通用智能,而是一种“锯齿状智能”。
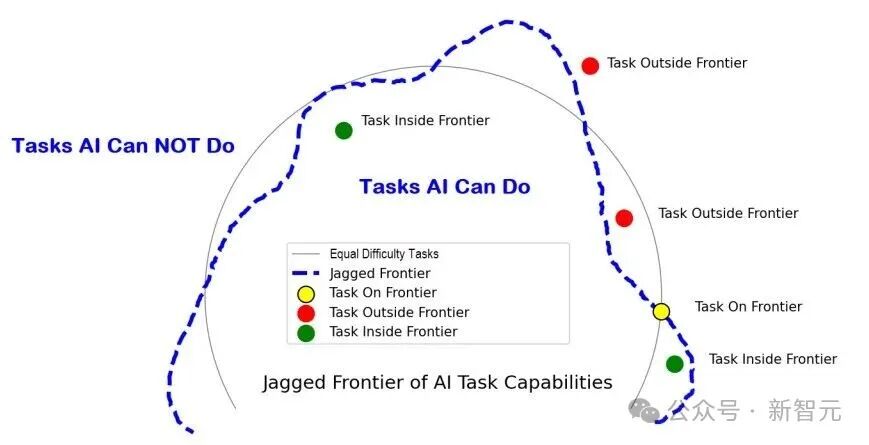
这意味着,模型可以在某些复杂任务上表现得如同专家,转眼间却又在极其简单的问题上犯下低级错误。这种强烈的反差感,暴露了当前架构中存在某些根本性的局限。
问题的核心或许在于,Transformer架构太“通用”了。你可以通过足够的训练和精妙的提示工程,让它去完成几乎任何类型的任务。但正因为这种“万能”属性,研究者们可能忽视了更深层的问题:是否存在更优的知识表示方式和问题思考机制?
“现在,大家把所有东西都往Transformer里堆,把它当成万用工具来用。缺什么功能,就往上硬加模块。” Jones评论道,“我们明明知道需要不确定性建模、需要自适应计算能力,但我们却选择把这些特性以外挂的形式添加上去,而不是从架构本身去重新思考。”
为了跳出这个循环,Jones在2025年初开始将研究重心从Transformer转移,转向更具探索性的方向。他与Sakana AI的同事Luke Darlow等人,从生物学和自然现象中汲取灵感,设计了“连续思维机”。
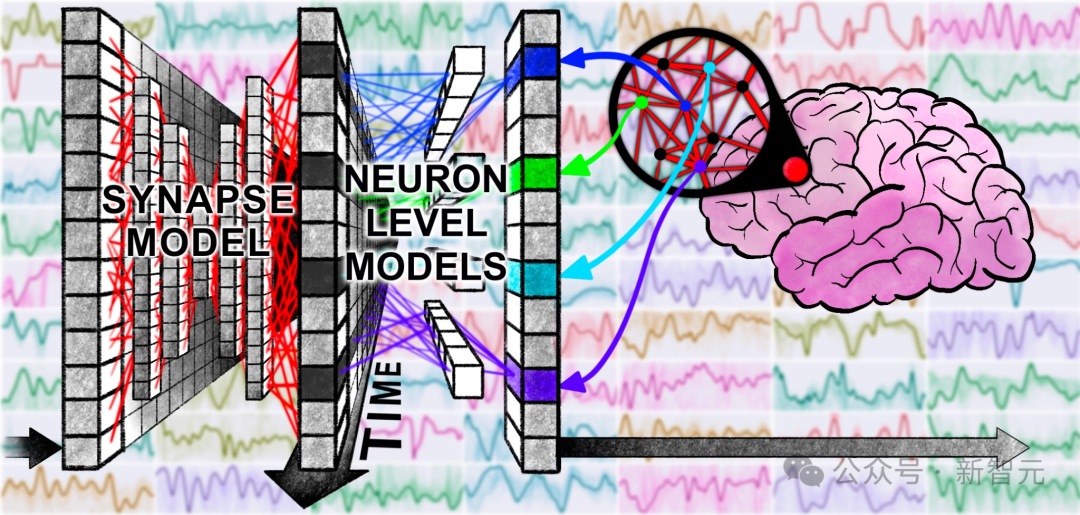
这项研究并非追求完全的生物仿真,而是对大脑运作原理进行高度简化的模拟。其核心思想是:大脑中的神经元并非静态的开关,而是通过同步振荡来传递和处理信息。CTM捕捉了这一精髓,使用神经动态作为核心表示,让模型在“内部思考维度”上逐步展开计算。
重要的是,他们在进行这项研究时,没有感受到学术圈常见的“抢发”压力,因为几乎没人在这个方向上工作。这给了他们充足的时间去打磨论文、做实研究、做足对照实验。
Jones希望,这项研究能成为一个“示范案例”,鼓励更多研究者去尝试那些看似高风险、却更可能通往下一个重大突破的探索方向。
启示:我们是否困在局部最优中?
Llion Jones的这番反思,是近期人工智能领域最为坦诚的言论之一。他承认,当前大量的研究工作可能只是在局部最优解上进行修修补补,而真正的范式转移或许隐藏在完全不同的方向。
他对此有着切身体会——毕竟,他本人就曾是那个让前一代主流研究(RNN)黯然失色的“颠覆者”。
一个令人不安的推论是:如果他的判断正确,那么所有埋头于改进Transformer各种变体的努力——无论是混合专家模型、注意力机制变体,还是层出不穷的架构微调——都可能在新的范式出现时瞬间过时。
但真正的困境在于:在突破发生之前,无人能确信自己是否真的困在局部最优之中。身处其中时,每一项微小的改进看起来都像是扎实的进步。在Transformer出现之前,RNN的一系列改进不也显得势不可挡吗?
同样,OpenAI的联合创始人Ilya Sutskever近期也评论道,仅靠扩大当前架构的规模并不足以实现AGI。
“Scaling时代的一个后果是:Scaling吸走了房间里所有的氧气。正因如此,所有人开始做同样的事。我们走到了今天这个局面——公司的数量多于创新点的世界。”
那么,研究者该如何抉择?Jones并未声称自己知道未来的答案,他只是坦言Transformer可能不是长期的解决方案。这种诚实虽然可贵,却缺乏直接的操作指南。
这个难题的本质在于:每一次范式转移,在事后看来都像是一段徒劳的摸索,但在当时却是必要的积累。我们无法跳过这个阶段,只能鼓励更多探索性的思考与尝试,并期盼有人能更快地找到出口。
关于AI未来架构的讨论,欢迎在云栈社区继续交流。
 发表于 2026-1-19 23:11:15
|
查看: 297|
回复: 0
发表于 2026-1-19 23:11:15
|
查看: 297|
回复: 0
