
近期,NewBieAi Lab 发布了其首个实验性文本生成图像模型 NewBie-image-Exp0.1。该模型专注于生成高质量的动漫(ACG)风格图像,其核心采用了前沿的 Next-DiT Transformer架构,并结合了先进的文本编码器与视觉解码器,旨在为艺术创作提供更灵活、细节更丰富的生成体验。
一、模型概览
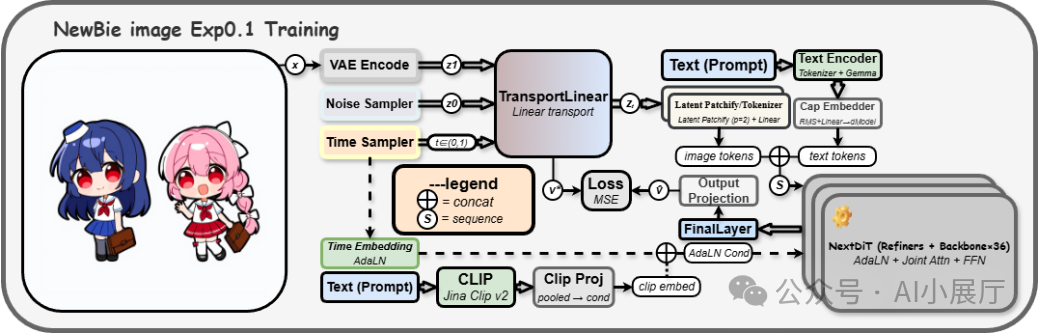
NewBie-image-Exp0.1 是一款参数量为 3.5B 的动漫图像生成模型。它以 Transformer-based 的 Next-DiT 架构为核心,使用大规模高质量动漫数据进行训练,并集成了双文本编码器与 Flux 1 Dev-VAE,目标在于全面提升对提示词的理解能力、生成图像的一致性以及最终的视觉渲染质量。
目前,该模型已在 Hugging Face 平台上以非商业许可(Newbie-NC-1.0) 的形式开源。
二、核心技术解析
1. Next-DiT:新一代生成主干
模型摒弃了传统的U-Net结构,转而采用 Next-DiT(基于 Diffusion Transformer 的扩展架构)作为其生成核心。这种人工智能架构在以下方面表现突出:
- 更强的长程依赖建模:擅长处理包含复杂构图和多人物的场景。
- 更精细的特征表达:能够生成蕴含高密度细节的动漫风格画面。
- 良好的可扩展性:为未来支持多分辨率及跨模态任务奠定了基础。
这使得模型在动漫插画、角色设定、概念设计等需要高稳定性和表现力的应用中更具优势。
2. 双文本编码器融合
为了精准理解用户意图,模型创新性地融合了两种文本编码器的能力:
- Google Gemma3-4B-it:提供强大的自然语言理解。
- Jina AI / Jina CLIP v2:具备出色的文本-图像对齐能力。
Gemma的隐层特征与CLIP的池化嵌入会经过线性映射后融合,并输入到扩散模型的时间步与自适应层归一化(AdaLN)条件路径中。这种设计带来了显著优势:
- 对提示词(prompt)的理解更为精确。
- 对风格、构图、动作等视觉细节的控制更加容易。
- 生成复杂场景、多角色、多属性的画面时更加稳定。
对于希望精确控制人物服饰、表情、动作及场景的创作者而言,这一机制至关重要。
3. Flux 1 Dev-VAE:提升视觉细节
模型采用了近期备受好评的 Flux 1 Dev-VAE 作为视觉编码器。该编码器特性鲜明:
- 具备丰富的色彩还原能力。
- 能呈现干净锐利的边缘和线条。
- 对纹理、光影等细节的层次刻画更为细腻。
在动漫风格生成中,这种VAE能显著提升最终画面的锐度、质感和整体观感。
4. 结构化XML Prompt训练
在数据预处理阶段,训练集中的文本描述被转换为结构化的XML格式,例如:
<root>
<character>…</character>
<appearance>…</appearance>
<clothing>…</clothing>
<action>…</action>
<background>…</background>
</root>
这种结构化方式带来了三大好处:
- 属性解耦清晰:如发色、服装、姿势等属性不易相互干扰。
- 多角色场景明确:有效减少人物融合或位置错乱的情况。
- 加速收敛与精确控制:模型训练效率更高,对生成条件的控制也更精准。
这对于元素明确、标签清晰的动漫内容生成尤为重要。
三、训练配置与模型规模
- 参数量:3.5B
- 训练数据:海量高质量动漫图像 + 对应的结构化XML Prompt
- 视觉编码器(VAE):Flux 1 Dev-VAE(16通道)
- 文本编码器:Gemma3-4B-it + Jina Clip v2
- 能力侧重:高分辨率、高细节、高一致性的动漫风格图像生成
整体技术路线明确指向“高质量且可控的动漫图像生成”。
四、开源信息与许可
- 模型开源地址:
- 许可协议:Newbie-NC-1.0
- 仅限非商业用途。
- 涵盖模型权重、衍生模型(如LoRA)及量化版本。
- 训练与推理脚本等源代码采用 Apache 2.0 协议。
请注意:获取完整的模型权重可能需要联系官方进行授权审批。
五、典型应用场景
NewBie-image-Exp0.1 在以下创作方向展现出明显优势:
- 动漫角色设定与原画创作
- 同人作品与插画生成
- 游戏概念设计(人物与场景)
- 漫画分镜草稿生成
- 视觉灵感探索与草图快速迭代
其稳定生成多角色、多属性、多元素场景的能力,为内容创作者提供了强大的实用工具。 |  发表于 2025-12-9 03:47:39
|
查看: 174|
回复: 0
发表于 2025-12-9 03:47:39
|
查看: 174|
回复: 0
