浙江大学 ReLER 团队提出的 ContextGen 是一种基于 Diffusion Transformer (DiT) 架构的多实例图像生成方法。它通过创新的上下文双重注意力机制,能够同时实现对多个目标实例的精确空间布局控制和高保真的身份细节注入。
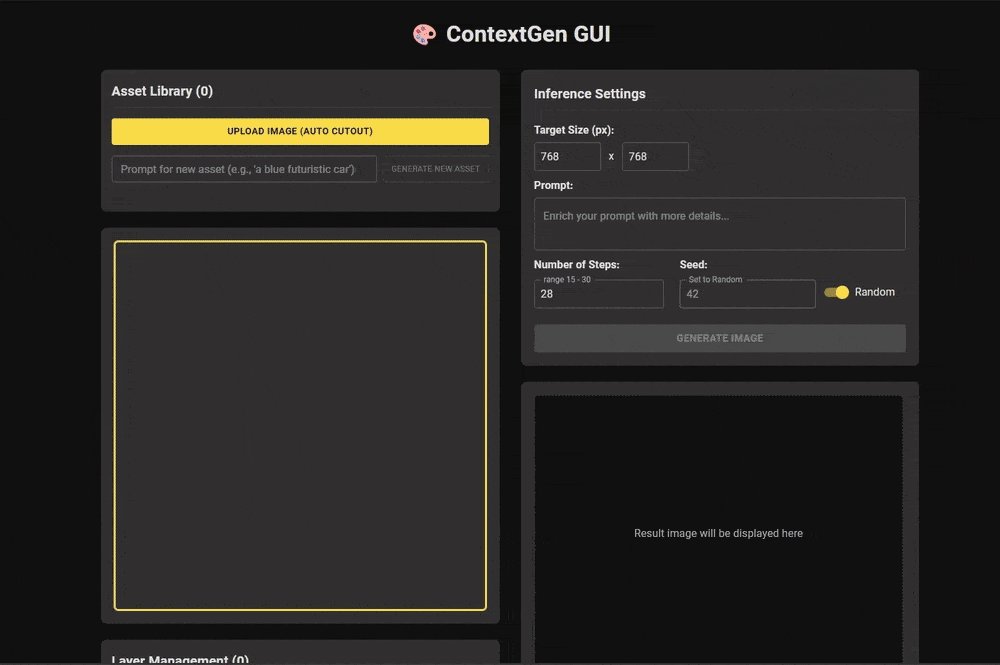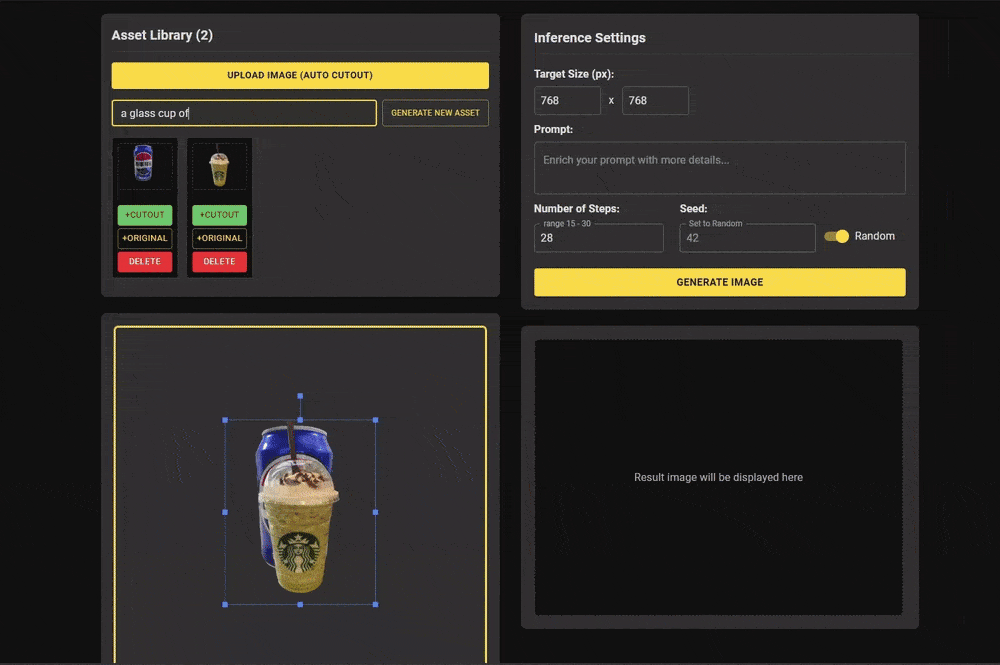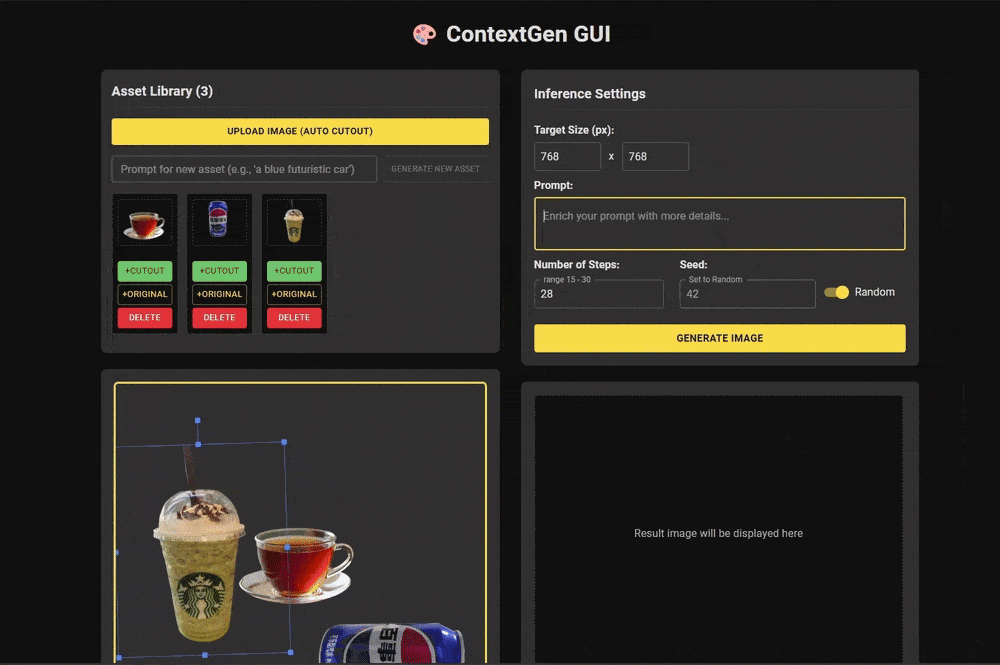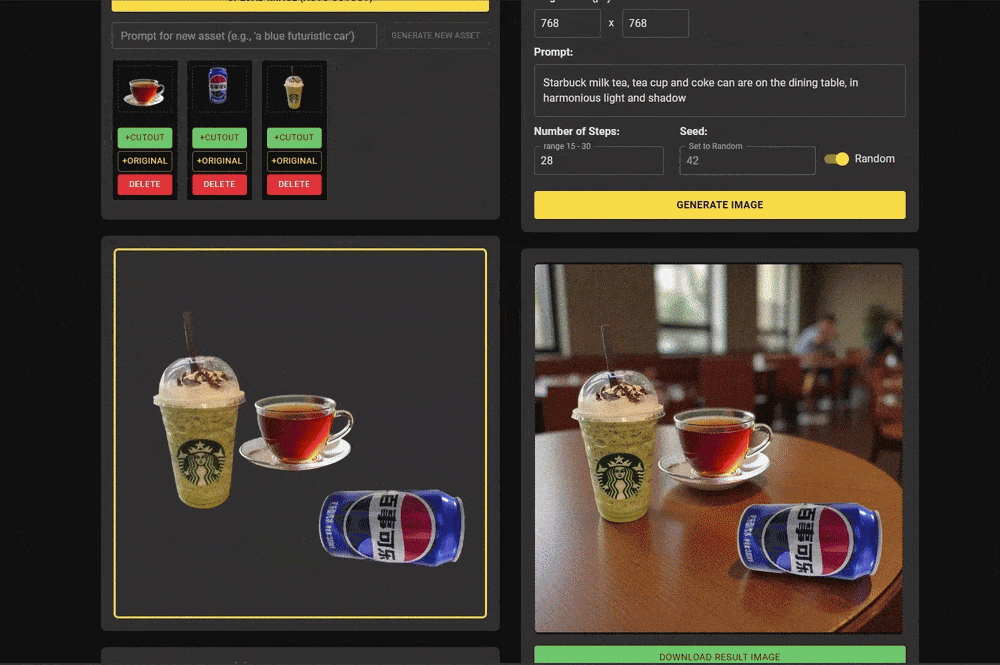
研究团队还提供了一个简洁的前端界面,用户可以通过上传参考图像和设计布局草图,轻松实现定制化的多实例图像生成。
方法概述

ContextGen 建立在强大的 Diffusion Transformer (DiT) 基础模型之上,其核心目标是解决多实例图像生成中布局与身份难以协同控制的难题。该框架将布局指导图与多张参考图像拼接成一个统一的上下文序列,并创新性地引入了双重上下文注意力机制,在 DiT 的不同网络层进行分层、解耦的控制。
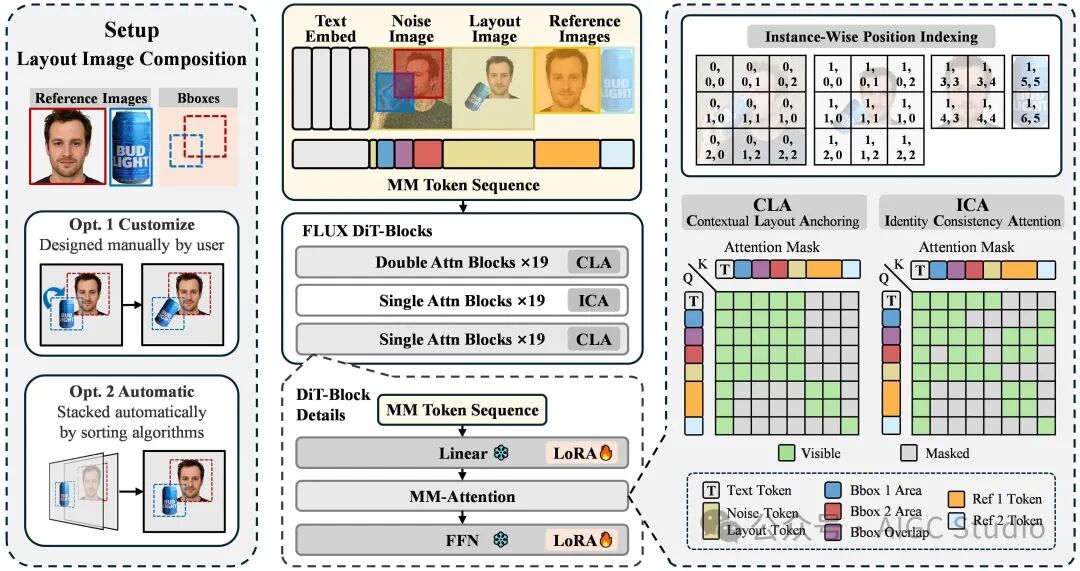
(a) 双重上下文注意力机制
该方法的核心在于将宏观的布局控制与微观的身份注入进行有效分离:
- 上下文布局锚定 (Contextual Layout Anchoring, CLA):部署在 DiT 的前置与后置层,专注于捕捉全局结构信息。CLA 模块通过学习上下文中的布局图像信息,鲁棒地将各个生成对象锚定到期望的空间位置,从而确保精确的布局控制。
- 身份一致性注意力 (Identity Consistency Attention, ICA):部署在 DiT 的中间层,专注于处理高频的细粒度身份细节。ICA 通过使用隔离式的注意力掩码,确保生成图像中每个实例区域的 Token 只与其对应的参考图像 Token 进行交互,从而保障多个主体的身份特征能够高保真且互不混淆地注入到生成过程中。
(b) DPO 强化学习优化
为了避免模型在监督微调后僵硬地复制布局图像,导致生成结果缺乏多样性,团队在训练流程中引入了基于偏好的优化 (DPO) 强化学习阶段。这一 优化策略 有效缓解了布局复制问题,显著提升了生成图像的自然度和多样性。
大规模 IMIG-100K 数据集
为了支撑开放集的多实例生成研究,团队利用现有的大型语言模型与开源工具,构建了 IMIG-100K 数据集。这是首个专门为图像引导的多实例生成任务设计的大规模合成数据集,包含了详细的布局和身份标注,为相关领域的研究提供了重要的数据基础。
实验结果
定量比较:在 COCO-MIG 和 LayoutSAM-Eval 基准测试中,ContextGen 在布局准确性和实例属性保持等关键指标上均显著优于现有方法。特别是在 COCO-MIG 上,其空间准确性 (mIoU) 提升了 +5.9%。在专门评估身份保持能力的 LAMICBench++ 测试中,ContextGen 全面超越了当前开源的 SOTA 模型。
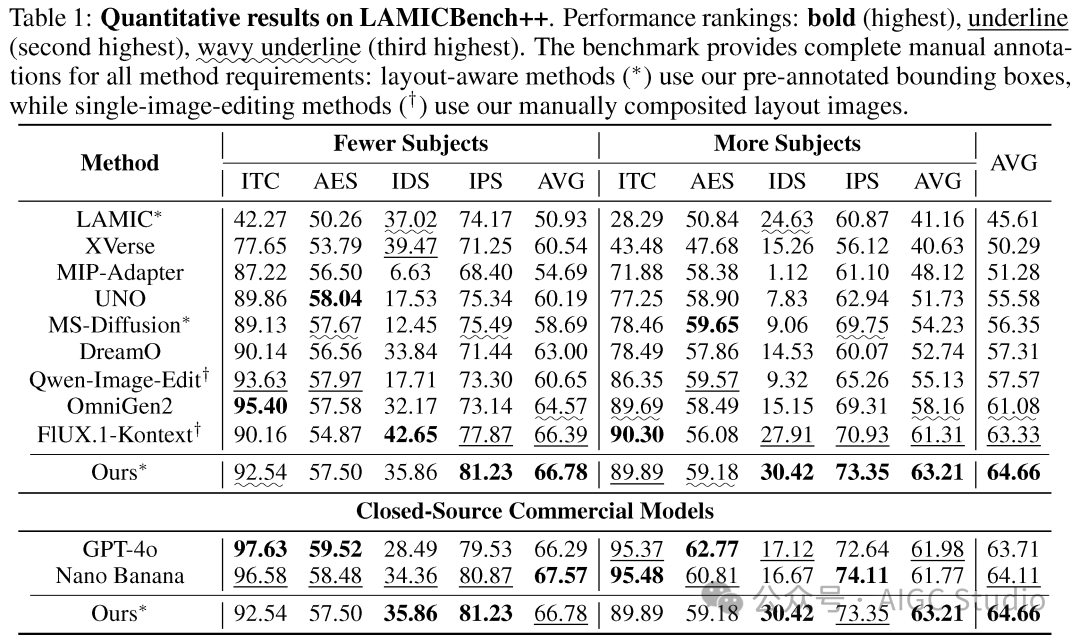
LAMICBench++ 身份保持性能对比
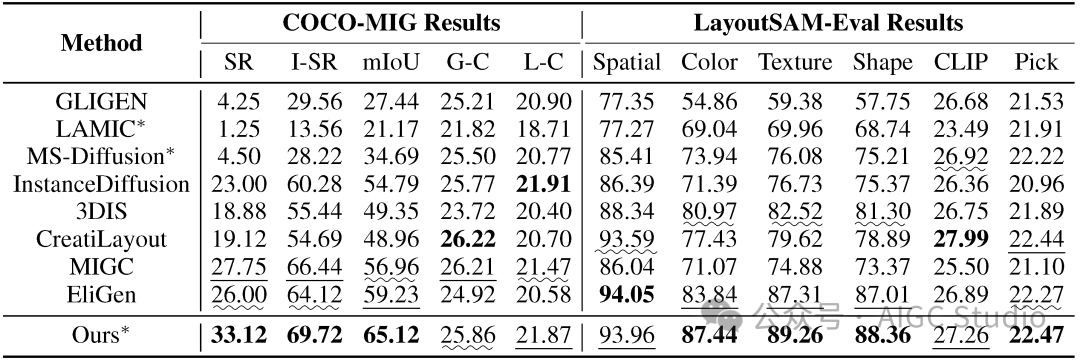
COCO-MIG 和 LayoutSAM-Eval 布局控制性能对比
定性结果:在复杂的多主体生成任务中,ContextGen 展现出了对多个实例细节(如特定颜色、材质、面部特征)的高保真还原能力。其身份保持效果甚至可以与 GPT-4o、Nano Banana 等强大的闭源商业模型相媲美。
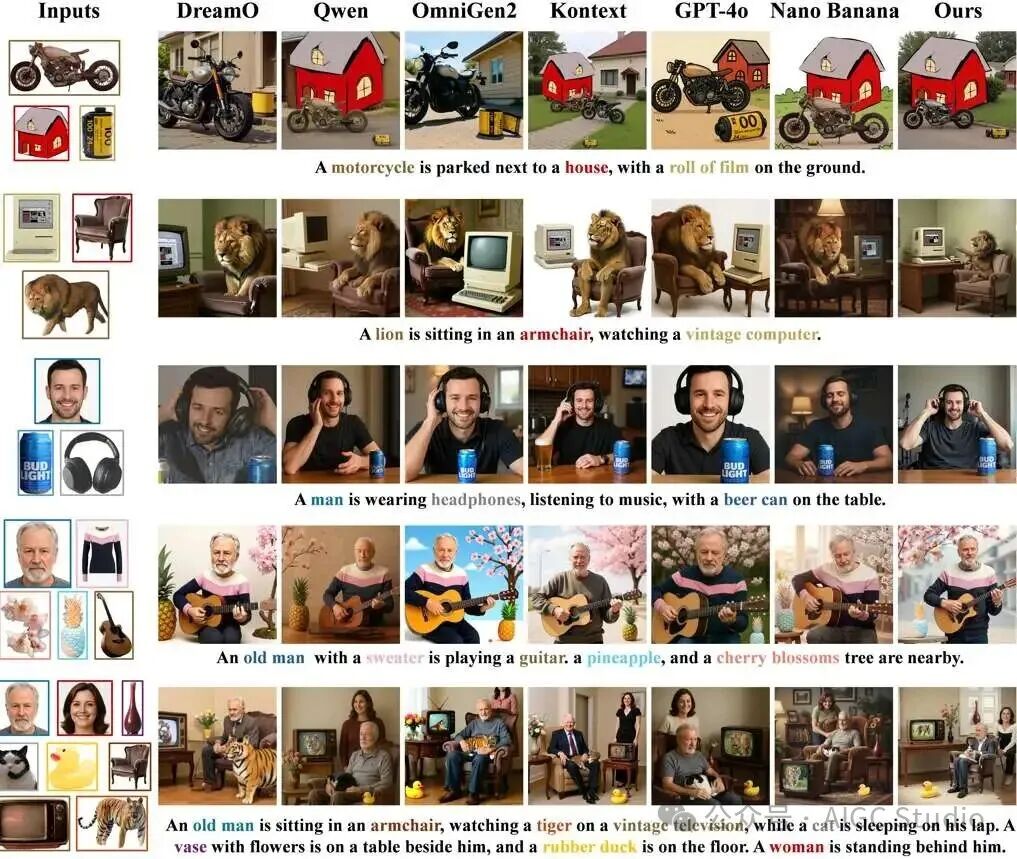
LAMICBench++ 身份保持定性对比(示例1)

LAMICBench++ 身份保持定性对比(示例2)

COCO-MIG 多实例生成定性对比

LayoutSAM-Eval 布局控制定性对比
结论
本文提出的 ContextGen 框架通过双重上下文注意力机制实现分层解耦控制,有效攻克了多实例图像生成中布局控制与身份保持协同优化的技术挑战。通过集成 CLA 与 ICA 模块,并结合 DPO 强化学习优化,ContextGen 能够同步实现高精度的布局锚定、高保真的身份注入,同时确保生成结果的多样性与自然度。大量实验证明,该框架在生成包含多个定制化实体的图像任务中达到了领先性能。 |  发表于 2025-12-14 23:46:10
|
查看: 185|
回复: 0
发表于 2025-12-14 23:46:10
|
查看: 185|
回复: 0
