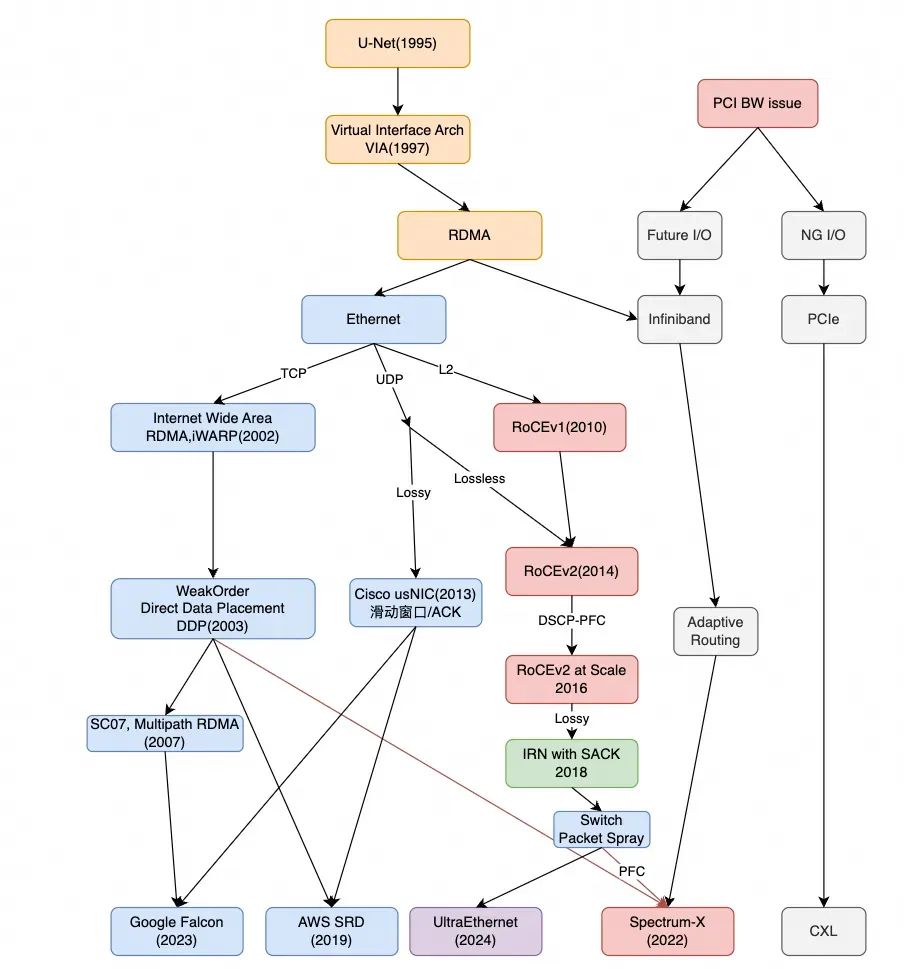
前几天,字节跳动发布了自研的veRoCE协议。仔细研读其规范可以发现,相对于传统RoCE,它放弃了无损网络(Lossless)的假设,支持了基于SACK的选择性重传,并为了多路径传输引入了类似iWARP的DDP(Direct Data Placement)机制,通过MSNETH/POETH报头实现了DDP中的MSN与Offset概念。言归正传,veRoCE这项工作本身意义重大,是对RoCE协议进行现代化改造的一次积极尝试。事实上,对于这些改良方向,业界在过去几年的文章中已有深入分析,并且相关技术方案已经在线上稳定运行多年。
例如,在以往的文章《RDMA这十年的反思1:从协议演进的视角》中已经清晰地阐述过。
最早探讨多路径能力的研究可以追溯到2007年的一篇论文《Analyzing the Impact of Supporting Out-of-Order Communication on In-order Performance with iWARP》。文章开篇即指出:由于高端计算系统对容忍网络故障和拥塞的需求日益增长,支持多网络通信路径正变得越来越重要。这正是当今AI训练网络中至关重要的拥塞和链路容错问题。而解决方案就是采用弱排序(Weak Ordering)的DDP机制。
20年前就已存在答案的问题,却成为当今RDMA现代化改造的焦点,这似乎有些讽刺意味。这也印证了一个观点:RoCE在过去十年的发展初期可能就走错了方向。事实上,更合理的技术路径选择如下:
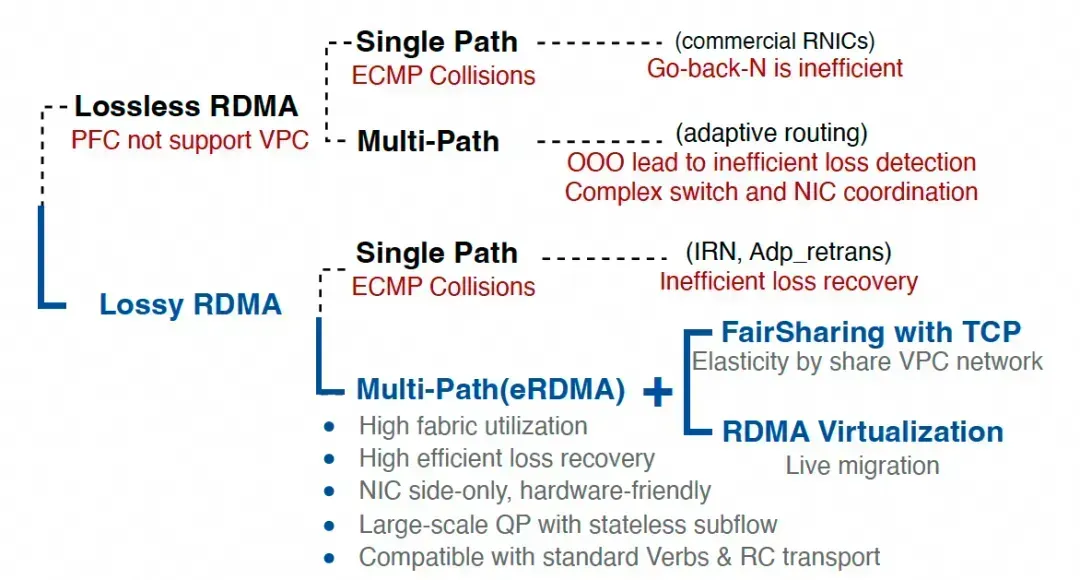
关于RoCE的缺陷,字节在官方文章《火山引擎 Force 大会发布 veRoCE 传输协议!》中提到了veRoCE带来的收益:
在典型测试场景中,veRoCE为大模型训练带来显著提升:LLM训练速度相较于RoCEv2提升约11.2%;AlltoAll通信吞吐提升约48.4%;在2%丢包率下,veRoCE的有效吞吐仍能达到网卡带宽的约95.7%,而RoCEv2在此场景下会因丢包过多导致通信中断。
这意味着,以往使用传统RoCEv2进行LLM训练时,由于协议缺陷可能导致整体算力浪费了11.2%。类似MoE等模型所需的AlltoAll操作,其带宽利用率可能仅有67%?此外,业界对于有损网络(Lossy)的测试标准通常更为严苛,无论是Google的Falcon还是CIPU eRDMA,都以在极端5%丢包率下实现90%的有效吞吐(Goodput)为目标。仅测试2%丢包率是不充分的。并且,即便在2%丢包率下,重传占用2%的带宽,理论上有效吞吐至少应达到97%以上才算充分利用带宽,这表明当前方案在错误重传导致的损耗方面仍有优化空间。
下面我们来详细分析veRoCE的协议规范。
1. 概述
规范开篇明确指出:
InfiniBand和RoCEv2都需要依赖无损网络才能高效运行,这使得RDMA传输协议在处理丢包和乱序报文时效率低下。此外,无损网络架构容易引发拥塞扩散和死锁,严重限制了网络的扩展性。随着AI网络规模将扩展至支持数十万甚至数百万GPU或AI加速器,这些限制变得尤为突出。在此规模下,由多路径传输和有损网络引起的丢包和乱序是必须解决且不可避免的“常态”。
这个判断是正确的。始终坚持无损网络的观点值得商榷。一个朴素的观点是:传统以太网的设计哲学是“尽力而为”(Best-Effort),可靠性应由端点(如TCP)来保证。很高兴看到字节在这方面做出了转变。
另一个值得称赞的设计是维持了RDMA Verbs语义的兼容性,没有像AWS SRD那样为了支持多路径而导致整个生态不兼容。
现代化改造的另一个重点是支持多路径传输能力。相较于NVIDIA和博通倾向于在交换机侧做Packet Spray,veRoCE选择了支持端侧多路径能力。最终,通过“多路径传输、乱序交付、高效的丢包检测、硬件友好的选择性重传以及灵活的拥塞控制等特性”实现了RDMA的现代化。
如果我们仔细对比RoCE和iWARP,抛开TCP和UDP的差异,主要区别在于:无损(Lossless) vs 有损(Lossy)。字节已经做出了选择。为了实现有损传输,veRoCE采用了SACK机制。为了实现多路径转发,引入了iWARP的DDP概念。实质上,如果再加上基于滑动窗口的拥塞控制,其与iWARP的主要区别就只剩下UDP/TCP这个传输层协议了。同时,其延迟测量也采用了类似Swift的方式。当然,还存在一些细微区别,例如PSN与SeqNum的差异,这其中涉及许多设计取舍,特别是在跨域(Scale-Across)场景下的考量。
2. veRoCE报文格式
规范第三章介绍了报文格式。
2.1 BTH(基础传输头)
报文格式与InfiniBand规范基本一致,主要修改是增加了SACK、ACK_Rsp和SACK_Rsp类型的报文。此外,还增加了RTT探测报文和一个用于慢路径(SlowPath)的OpCode。
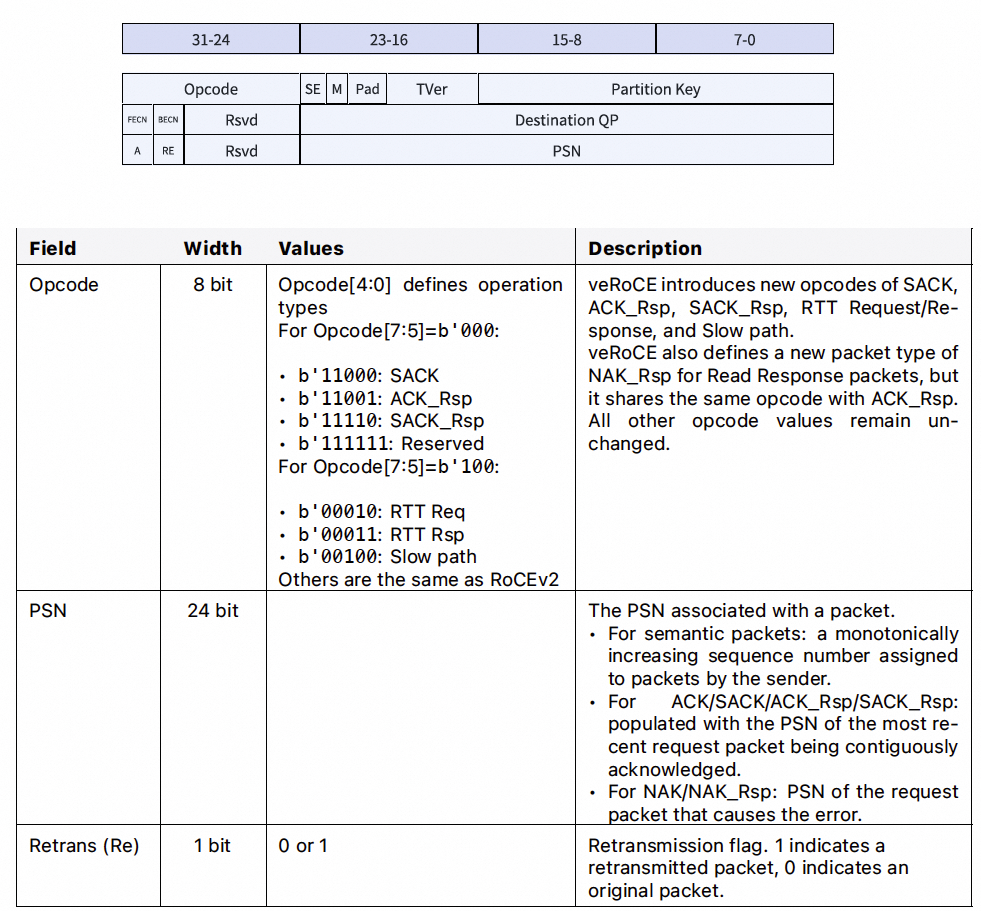
2.2 DDP头
为了支持DDP功能,veRoCE增加了MSN扩展传输头(MSNETH)和包偏移扩展传输头(POETH)。
以前我们也讨论过,在RoCE的报文格式中,由于传输层要求严格保序,报文设计相对简单,仅包含First/Middle/Last标识。
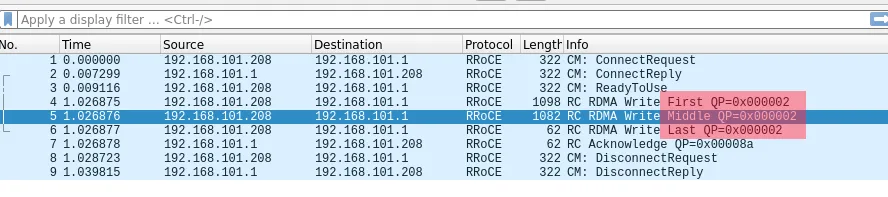
中间报文并不携带操作远端内存的地址信息,因此一旦乱序,接收端将无法确定写入位置。当然,NVIDIA也做了一些简化处理:是否可以通过将一个消息拆分成多个独立的WRITE报文,每个都携带地址,从而实现乱序发送?但对于一个完整消息,发送端仍需通知接收端操作已完成。因此,发送端需要等待所有拆分的WRITE报文被确认后,再发送一个WRITE_With_Imm消息进行最终确认,或者通过一个ATOMIC消息来更新接收端的Fence标志。这实际上仍然增加了一个往返延迟(RTT)。这种做法对于WRITE操作或许可行,但对于SEND/RECV语义则存在缺陷,因为RECV端的缓冲区排布并非绝对的物理地址。所以,在NVIDIA CX7网卡中,乱序处理仅支持WRITE语义。
网络领域早有深入研究,例如2002年发布的iWARP协议中就提出了直接数据放置(Direct Data Placement, DDP)技术。
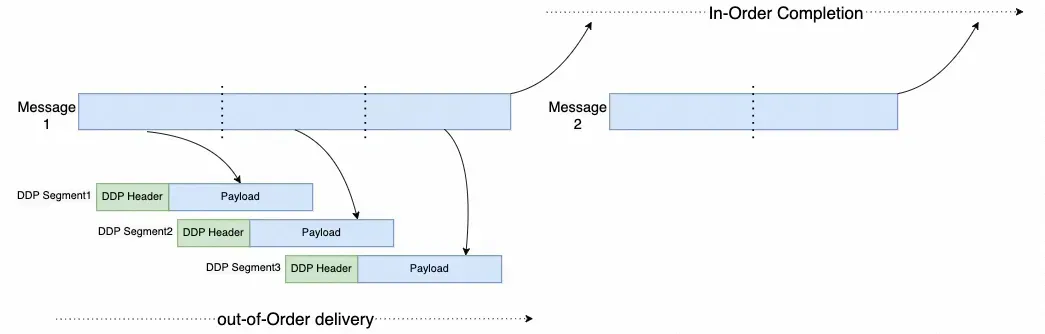
DDP在每个数据分段中添加了消息序列号(MSN)和消息偏移量(MO)。通过MSN和MO,可以非常容易地在多种语义上支持乱序接收,并能在接收端判断消息是否完成,进而提交立即数(Imm)或更新Fence标志。与RoCE现有实现相比,这甚至节省了一个RTT。
veRoCE在实现上略有差异,它采用包顺序(PO)而非DDP中的偏移量(Offset)。因此地址计算方式为:目标地址 = 基地址 + PO × 每包有效载荷大小。
3. 可靠连接服务
在设计新协议时,保持可靠连接(RC)服务接口的兼容性是非常值得称赞的。AWS EFA的问题在于,它在解决多路径转发时放弃了对RC的兼容,转而采用SRD方式,从而带来了大量的兼容性问题。
3.1 PSN(包序列号)
每个报文在其BTH中携带一个PSN进行传输。PSN用于识别丢失或乱序的报文,并且在可靠连接服务中,用于将确认报文关联到给定的语义报文。
veRoCE定义了两个PSN空间,一个QP同时维护两套独立的PSN序列号:
- SQ PSN空间:用于自己发起的Send/Write/Read请求。
- 响应PSN空间:用于为自己收到的Read/Atomic请求生成的响应。
这个设计也指出了RoCE的一个固有缺陷。标准的RoCE协议实际上无法很好地支持基于窗口的拥塞控制,原因在于:
- 数据包和ACK报文是单独发送的,数据包内不携带ACK信息。
- Read响应报文是用ACK报文封装的,实质是数据包,而Read响应本身没有对应的ACK。
这意味着:
- 由于响应报文不使用PSN,它们无法被原始的请求端用常规的ACK/NAK机制确认。
- 对Read请求报文的确认是隐式的,通过Read响应报文中携带的PSN实现。
- 对Read响应报文的可靠性保证几乎完全依赖于请求端的超时重传(RTO)。
如果采用基于窗口的拥塞控制,需要ACK来驱动窗口前进,在Read场景下就会导致Read响应发不出去。在不修改RoCE协议的前提下,解决方案只能是使用定时器配合令牌/信用机制,这又变回了基于速率的控制。
因此,veRoCE定义两个PSN空间,理论上可以解决这个问题。
接下来讨论一下PSN编码。理论上PSN长度很大(24位),但接收端的PSN位图长度限制了乱序接收窗口的大小。如果一个报文的PSN大于或等于aPSN + bitmap_length + 1,接收端将无法在其PSN位图中记录该报文的到达,从而导致该报文被丢弃。
这里存在一个潜在问题。考虑跨可用区(Scale-Across)的场景,例如跨AZ距离几十公里,假设延迟为500微秒,硬件位图为128位,那么实际的“在途数据”(inflight)大小为8KB * 128 = 1MB。此时,单个QP的最大理论带宽仅为1MB / 500us ≈ 16Gbps。若需达到400Gbps,则需要约3200位的位图。此外,跨AZ时不同光纤物理路径不同,还会出现路径延迟差异,处理起来更为复杂。
相比之下,iWARP采用的序列号(SeqNum)表示法可能更有效,具体实现此处不展开。
3.2 MSN(消息序列号)
MSN将可靠性确认从报文粒度提升到了消息粒度。aMSN(已确认MSN)的前进,是发送端硬件能够安全生成完成队列项(CQE)、通知应用操作完成的唯一可靠信号。这可以高效地实现Write-with-Immediate数据的处理。
3.3 确认机制
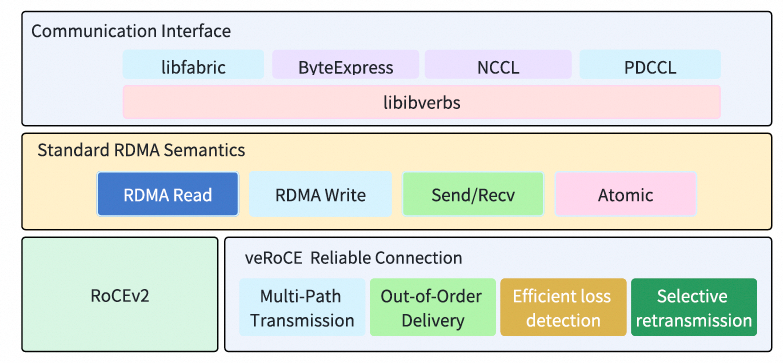
这部分是本章的核心,定义了veRoCE的关键交互逻辑。ACK报文的格式描述如下:
3.3.1 ACK/SACK
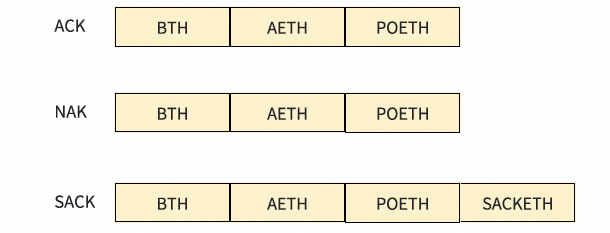
每个报文都需要确认,但ACK支持聚合,即允许单个ACK报文确认一个或多个先前的语义报文。当接收端生成ACK/SACK时,其BTH.PSN字段用aPSN(已确认PSN)填充。发送端收到ack_pkt后,应将自己的aPSN前进到该ack_pkt的BTH.PSN。对于Read、Atomic和Send-with-Invalidation操作,ACK报文确认该请求已被接收。
一个常见的ACK流程如下:
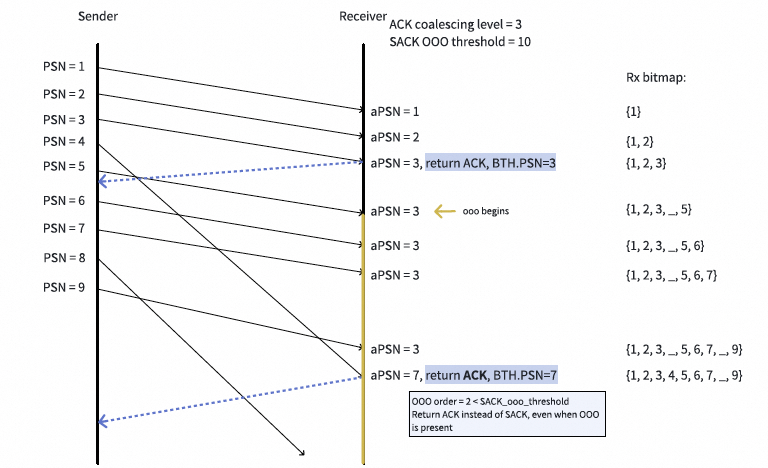
SACK报文用于选择性地确认在接收端乱序到达的语义报文。SACK的聚合与具体实现相关。考虑到SACK有128位的位图,可以采用一种“延迟SACK”(Lazy SACK)的处理方式:不为每个乱序报文都生成SACK,而是当接收端的乱序度(OOOD)超过某个阈值时,接收端才发送一个SACK。这意味着当OOOD低于阈值时,接收端继续返回ACK。OOOD定义为最高接收到的PSN(hPSN)与aPSN之间的差值。触发发送SACK报文的OOOD阈值可以被视为由多路径引起的最大乱序程度。
SACK示例如下:
这里也引入了一个问题:固定的OOOD阈值会带来一些复杂性,尤其是在基于速率的流控机制下。这一点将在后续拥塞控制部分详细展开。
3.3.2 NAK
veRoCE的NAK协议与InfiniBand规范保持一致。NAK码b'00000'(PSN序列错误)被重用于“丢包NAK”(Packet Drop NAK)。对于丢包NAK,应在检测到错误后立即传输NAK报文。
这实际上是为了配合交换机支持Packet Trimming(如NDP机制)而设计的显式丢包响应信号。
3.3.3 丢包检测
采用SACK和重传超时(RTO)两种方法:
- SACK报文:SACK中的位图直接指示了哪些PSN已收到、哪些未收到。可以应用启发式方法推断丢包。使用“延迟SACK”时,发送端收到SACK后就可以假定
aPSN + 1已经丢失,并随后启动对aPSN + 1及其附近位图中指示为未收到的若干个PSN的重传。
- 传输定时器:如果一个包在定时器超时(RTO)前未被确认,将触发重传。一旦RTO重传被触发,发送端应停止由SACK触发的快速重传,直到
aPSN+1被确认为止。
3.3.4 快速选择性重传
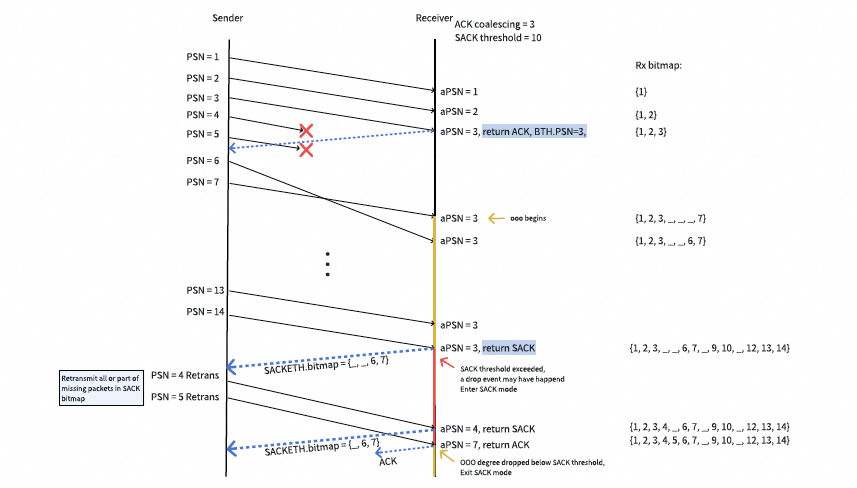
连续的SACK报文可能包含重叠的位图。如果每个SACK报文都简单地触发对[aPSN + 1, aPSN + N]范围内未收到报文的重传,将会产生大量不必要的重传,因为连续的SACK位图很可能重叠。下图提供了一个例子:报文2被重传了两次,因为两个SACK的位图都指示报文2尚未收到。
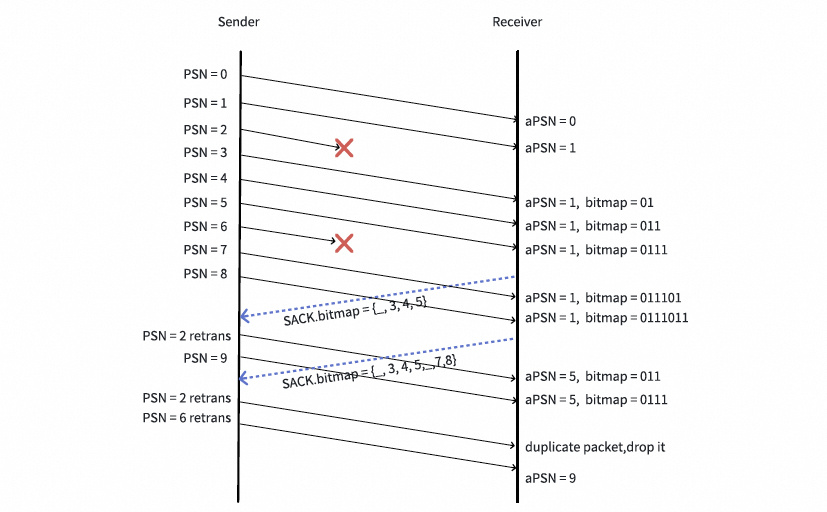
veRoCE推荐一种快速选择性重传机制来缓解不必要的重传。发送端或接收端维护一个变量RxtPSN,它记录了根据上一个SACK位图进行重传的最高PSN,并在每次收到或发送SACK时更新。对于每个新收到或发送的SACK,只有PSN大于RxtPSN的位图条目才应考虑用于选择性重传。为了避免因丢失的重传报文引起RTO,发送端或接收端还应记录RxtPSN最后一次更新的时间。当RxtPSN在一段时间内没有更新时,应将其重置为aPSN,以允许进行第二次选择性重传。该时间阈值的典型值为网络RTT。
下图描绘了当RxtPSN在发送端维护时,快速选择性重传的工作流程。
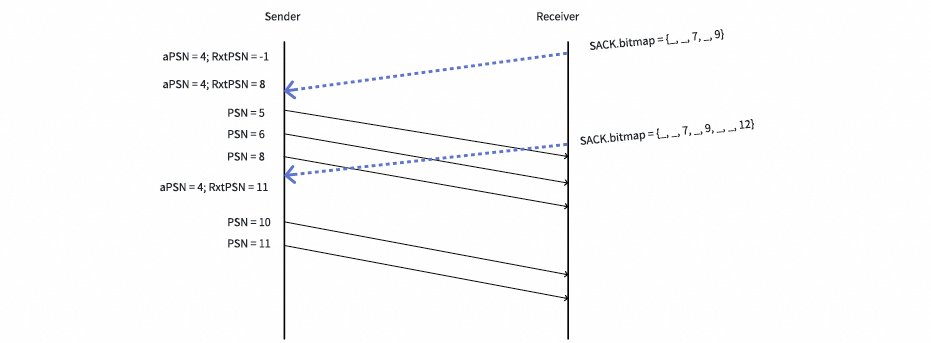
注意,veRoCE并不强制要求此设计,因为RxtPSN也可以在接收端维护。在发送端收到第一个SACK后,它解析位图,重传报文[5, 6, 8]并将RxtPSN更新为8。当第二个SACK到达时,重传的报文[5, 6, 8]仍在网络中传输。在RxtPSN的帮助下,发送端只重传了PSN大于RxtPSN的报文10和11。
如果重传的报文再次丢失,RxtPSN将会长时间停滞,导致其被重置。下图描绘了这个过程。
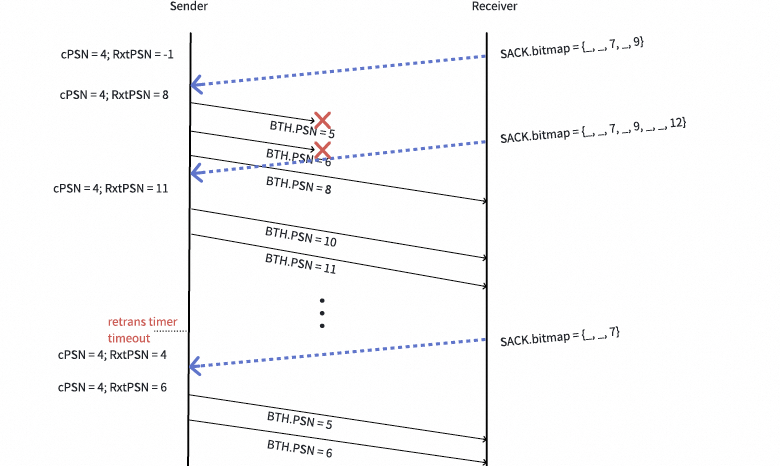
图中的第一个SACK触发了报文[5, 6, 8]的重传,但报文[5, 6]再次丢失。第二个SACK只重传了报文10和11,因为RxtPSN已经前进到8。当第三个SACK到达时,RxtPSN已经停滞了足够长的时间,从而被重置为aPSN(即4),于是报文[5, 6]被第二次重传。
这一部分的异常处理实现仍存在一些挑战。在纯硬件ASIC上构建完整的SACK逻辑非常困难,Google Falcon与Intel合作开发IPU时也曾因此多次流片。当然,veRoCE的处理方式仍存在一些可探讨的细节,此处不再展开。
3.4 WRITE与SEND操作的实现
这实质上是解释DDP的工作原理。RDMA Write操作的一个示例如下:
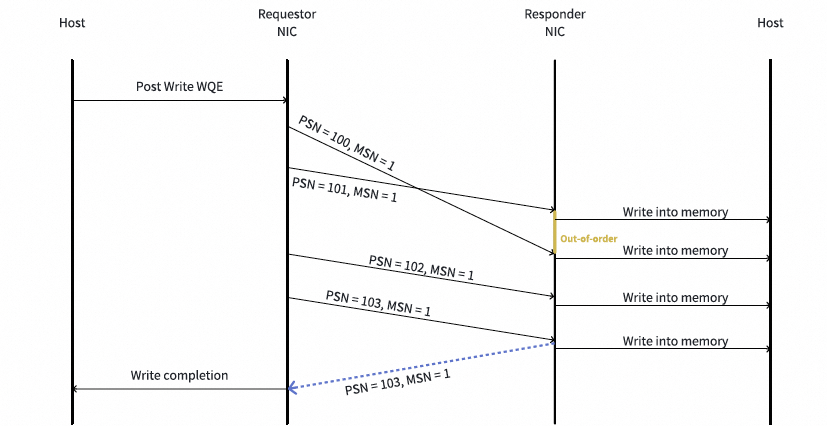
- 请求端向发送队列提交一个Write WQE。QP根据消息大小和MTU创建了4个Write请求报文(PSN = 100-103)。
- 请求端按顺序将报文传输给响应端。报文可能被网络重排序。例如,报文100和101在响应端乱序到达。响应端直接将数据放置到主机内存,无需对它们进行重排序。
- 响应端向请求端返回
ack_pkt以确认Write请求的到达,并且响应端可以执行ACK聚合以减少ack_pkt的数量。例如,最后4个报文的ACK被聚合。在该消息的最后一个“散乱包”(straggler packet)被响应端处理后,响应端回复一个AETH.MSN设置为1的ACK。一个Write消息的散乱包可以通过响应端的PSN位图来识别。
- 在收到带有新MSN值(本例中为1)的
ack_pkt后,请求端完成该Write消息。
对于Write-with-Immediate和Send消息,由最后一个报文携带的立即数需要被复制到CQE中。在乱序到达的情况下,最后一个报文可能在CQE生成之前到达,立即数需要被缓存在响应端。
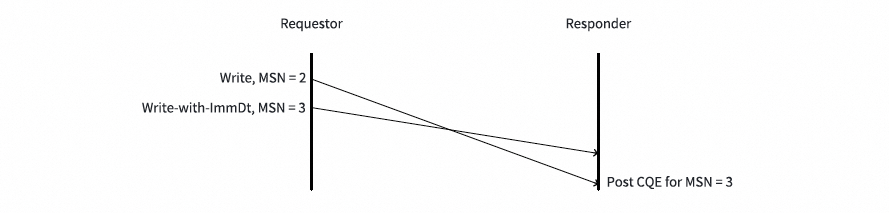
在MSN为2的Write请求完全接收后,响应端才为MSN为3的Write-with-ImmDt请求发布CQE。
3.5 READ操作的实现
Read请求仅占用一个PSN。后续的请求会顺序使用下一个PSN,不会跳过。收到Read请求后,响应端会缓冲它们,直到所有在前的请求都被处理完毕。对于一个Read响应,其AETH.MSN填充的是相应Read请求的MSN。
RDMA Read操作的一个示例如下:

- 请求端向发送队列提交一个Read Request WQE,随后一个Read Request报文被传输到响应端。该Read Request仅占用一个PSN。
- 收到Read Request后,响应端应向请求端回复一个ACK(也受ACK聚合影响)。这个ACK不表示Read请求的完成,只是确认Read Request已被响应端接收。
- 响应端缓冲该Read请求。当所有在前的请求都处理完毕后,响应端开始为该Read Request生成Read Response消息。
- 响应端按照被缓冲的Read Request的指示发送Read Response报文。对于一个Read Request,响应端可能根据消息大小和MTU生成多个Read Response报文。来自Read Response的报文与来自SQ的报文处于独立的PSN空间。
- 请求端收到Read Response报文,并回复
ack_pkt(即ACK_Rsp/SACK_Rsp)以确认其到达。当收到的Read Response报文填补了PSN范围中的一些“空洞”时,PSN和MSN可能得以推进,并通过确认报文返回给响应端。
- 响应端收到这些
ack_pkt。当ack_pkt中的MSN(指Response MSN)相比上次收到的MSN有所前进时,响应端释放相应数量的Read Request。
3.6 ATOMIC操作的实现
原子操作使请求端能够在响应端的一个指定地址上执行64位操作。这些操作原子性地读取、修改和写入目标地址,并保证对该地址的其他QP操作不会在读取和写入之间发生。veRoCE支持IB规范(章节9.4.5)中定义的FetchAdd和CmpSwap原子操作。原子操作请求仅占用一个PSN。收到原子操作请求后,响应端会缓冲它们,直到所有在前的请求都被处理完毕。响应端可以回复一个ACK或SACK来表明收到了原子操作请求,但这不能被用作请求端操作完成的信号。原子操作只有在收到AtomicACK时才能被认为是完成的。
原子操作的一个示例如下:
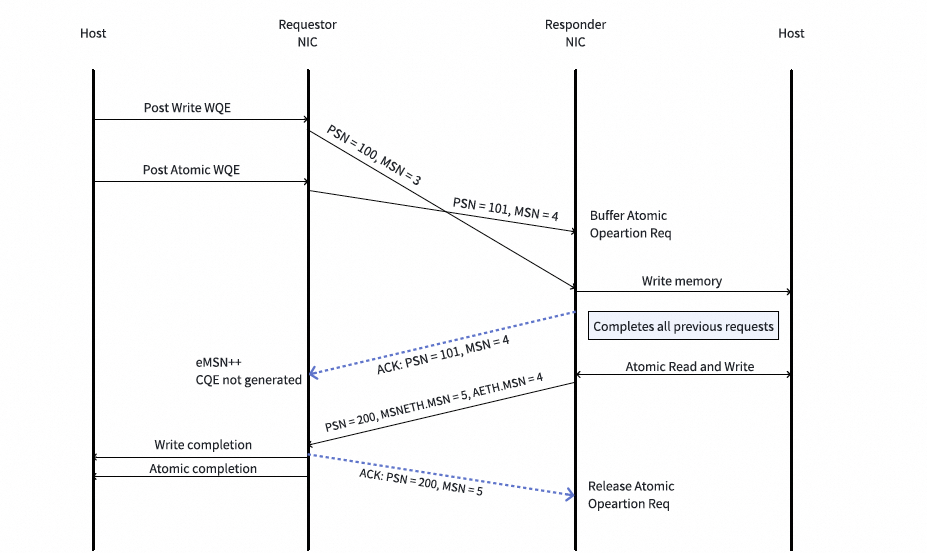
- 请求端向发送队列提交一个原子操作请求WQE(此时可能还有一个在途的Write请求WQE)。随后一个原子操作请求报文被传输到响应端。该原子操作请求仅占用一个PSN。
- 收到原子操作请求后,响应端应向请求端回复一个ACK(也受ACK聚合影响)。这个ACK不表示原子操作的完成,只是确认请求已被响应端接收。
- 响应端缓冲该原子操作请求。当所有在前的请求都处理完毕后,响应端执行该原子操作,并生成一个AtomicAck消息。
- 响应端发送AtomicAck消息。每个AtomicAck消息占用一个PSN和一个MSN。
- 请求端收到AtomicAck报文,并回复ACK_Rsp以确认其到达。当收到的AtomicAck报文填补了PSN范围中的“空洞”时,PSN和MSN可能得以推进,并通过确认报文返回给响应端。
- 响应端收到这些
ack_pkt。当ack_pkt中的MSN相比上次收到的MSN有所前进时,响应端释放相应数量的原子操作请求。
我们需要理解原子操作的本质。像FetchAdd或Compare-and-Swap这样的操作都包含两个步骤:
- 读:从远端内存地址读取原始值。
- 写:根据读取到的值和输入值进行计算,然后将新值写回同一地址。
关键在于,这两个步骤必须是原子性的,中间不能被任何其他操作打断。那么,如果AtomicAck丢失了怎么办?
在RoCEv2模型下,请求端只能等待RTO超时,然后重传整个Atomic Request。这会导致远端的原子操作被错误地执行两次,完全违背了“原子性”的初衷。
在veRoCE模型下,由于AtomicAck有自己的PSN,如果它丢失了,请求端会发现响应PSN空间出现“空洞”,或者最终由请求端侧的定时器超时(注意,这是等待响应的定时器,而非RTO)。请求端就可以向响应端发送一个NAK_Rsp或通过其他机制(如超时后发送查询状态的特殊包),请求响应端仅重传那个丢失的AtomicAck,而不是重新执行原子操作。响应端在执行完原子操作后,应该缓存结果(AtomicAck的内容),直到它被请求端确认为止。
3.7 操作顺序
这实质上是解释DDP的弱排序(Weak Ordering)。相对于InfiniBand定义的强排序(Strong Ordering),veRoCE有一处修改:一个Send或RDMA Write操作不一定在其后续的Send或RDMA Write请求之前完成。如果两个Send或RDMA Write操作写入相同的目标内存,来自第二个操作的数据可能会被第一个操作的数据覆盖。这项修改是为了加速DDP过程,并避免在硬件中缓冲数据载荷。
4. 拥塞控制
拥塞控制在现代AI训练网络中至关重要,直接关系到云原生/IaaS环境下大规模集群的稳定与高效。
4.1 拥塞通知
每个接收端QP维护一个或多个拥塞信号上下文(CSC)来记录拥塞相关信息。有两种方法将拥塞信号回传给发送端:
- 带内(In-band):
ack_pkt可以携带拥塞信号,如ECN(使用BTH头中的BECN字段),这可被基于窗口的拥塞控制算法利用。
- 带外(Out-of-band):拥塞信号也可以使用独立的CNP报文返回给发送端,这使得基于速率的拥塞控制算法成为可能。
CNP的生成速率与实现相关。例如,即使接收端QP要求NIC硬件为每个被ECN标记的报文都生成一个CNP,硬件也可能以类似于ACK聚合的方式来聚合CNP。一旦一个CNP被发送,拥塞信号上下文应被重置。
4.2 RTT探测
RTT是使用独立的RTT探测报文测量的。具体算法与Google Falcon和CIPU eRDMA类似,一个RTT探测请求返回4个时间戳:

- 发送时间戳1:RTT请求报文在发送端的发送时间。该时间戳由请求中的RTTReqETH携带,并由RTT响应中的RTTRspETH回显。
- 接收时间戳1:RTT请求报文在接收端的接收时间。该时间戳由RTT响应中的RTTRspETH携带。
- 发送时间戳2:RTT响应报文在接收端的发送时间。该时间戳由RTT响应中的RTTRspETH携带。
- 接收时间戳2:RTT响应报文在发送端的接收时间。该时间戳由发送端自己标注。
这4个时间戳被传递给CC模块。如何使用这些时间戳由CC算法决定。三种可能的方式包括:a. 计算网络往返延迟;b. 计算主机处理延迟;c. 如果请求端和响应端时间同步,可计算网络单向延迟。
一个RTT请求的UDP源端口字段根据它正在探测的路径来设置,而RTT响应的源端口与其对应的RTT请求保持相同。
veRoCE的RTT探测方式仍有改进空间。在《谈谈Google Falcon的可靠传输论文并对比分析CIPU eRDMA》中也曾指出:RoCE没有将拥塞控制与数据路径紧密集成。 其拥塞控制是作为一个附加组件实现的,依赖于带外探测来收集拥塞信号,这种分离导致其拥塞响应迟缓。
事实上,像Google Falcon和CIPU eRDMA采用的带内测量方式具有更大优势。具体能解决哪些问题涉密不便展开。
4.3 拥塞控制模式
采用多路径的可靠连接,其拥塞控制机制可以工作在两种模式下:连接级和路径级。在任一模式下,发送端QP维护一个或多个拥塞控制上下文(CCC)来控制发送速率。注意,对于单路径可靠连接,无需区分这两种模式。
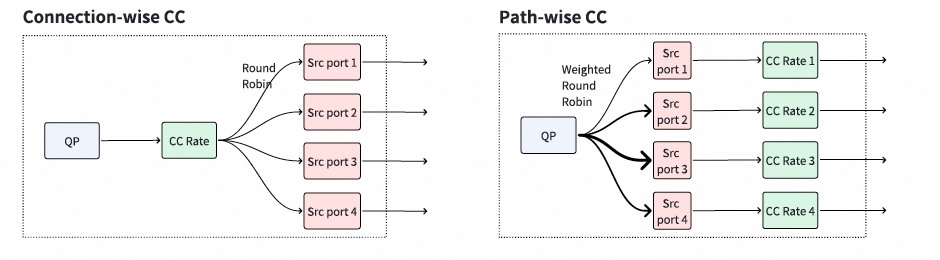
这里还有很多技巧似乎尚未在规范中体现,例如路径级的控制方式可能导致整个网卡的QP规模受限。
4.4 慢路径检测
随着时间的推移,路径质量可能会下降(例如,由于链路错误),使一条路径变成“慢路径”(高延迟/高丢包)。慢路径检测是一个可选但推荐的增强功能,以提高网络效率。发送端可以使用以下机制来识别并从慢路径迁移流量:
大的PSN差异(在接收端):如果一个新语义报文的PSN与hPSN(已收到的最高PSN)之间的差异超过一个阈值,那么该报文被认为是一个“慢包”。接收端随后向发送端发送一个慢包信号(Slow-Packet Signal, Opcode为bin10000100的报文)。如果发送端在一段时间内收到针对某条路径的多个慢包信号,该路径就可能被标记为慢路径。
慢路径检测算法可以是实现相关的。其他指标,例如延迟的ACK、RTT探测/响应丢失,也可以用来识别慢路径。
然而,在一些跨域(Scale-Across)场景中,物理路径的延迟本身就存在很大差异,简单地剔除“慢路径”将导致高延迟路径的实际带宽无法被利用。多路径转发的算法设计需要很多巧妙的平衡,但涉密不便详述。
5. 总结
5.1 RDMA现代化目标分析
笔者曾提出过RDMA现代化的几个目标:
- 集合通信能够保证95%以上的网络利用率。
- 在5%丢包率下仍能保证90%的有效吞吐。
- 无需任何交换机的高级特性,由网卡实现多路径和拥塞控制。
- 超大规模(如128K QPs)且支持所有QP开启多路径转发能力。
- 兼容RDMA RC Verbs,现有RDMA应用无需修改代码即可运行。
- 在类似128:1的Incast场景下,每个QP间的带宽差异最大不超过100Kbps。
- 完全OS无感知的热迁移。
- 完善的RDMA虚拟化支持。
总体来看,veRoCE是一项不错的工作。按照传统RoCE的基线性能,集合通信在标准的FatTree网络中因哈希冲突等原因,实际利用率约为60%。理论上,多路径能带来约1.6倍的性能提升,即达到第一个目标的需求。从字节公布的数据看,提升为1.48倍,这意味着实际网络利用率在89%左右,应该还有几个百分点的提升空间。
第二个目标是在5%丢包率下保持90%的有效吞吐,这是对SACK实现更严格的考核。希望字节能补充5%丢包率下的测试数据。
第三个目标是无需交换机高级特性,这一点veRoCE应该可以做到,尽管部分场景可能仍需要NDP或交换机提供额外的哈希熵。此外,仅靠剔除慢路径的多路径算法可能也存在问题。
第四个目标,如果使用路径级拥塞控制,可能无法实现,或者会导致多路径算法的可选子路径减少。
第五个目标,是veRoCE做得好的地方,坚持RC Verbs兼容才是正道。
第六个目标,从字节公布的数据看,AlltoAll性能提升不错,但能否达到如此严苛的标准尚存疑问。这一条对EP并行的AlltoAll通信至关重要。
最后两个目标属于实现层面的问题。
5.2 无损还是有损?
选择有损(Lossy)是veRoCE非常正确的一步。但实际上,当你选择有损并支持多路径时,就不可避免地会按照iWARP的思路来改造协议:对UDP传输做加法,从TCP借鉴SACK,延迟测量借鉴Swift,多路径又不可避免地参考iWARP的DDP。选择正确的网络/系统技术路线至关重要。
本质问题是,早期RDMA主要用于HPC场景,带宽需求小,延迟要求高,基本不丢包,因此强无损和简单可靠传输就能满足需求。但到了AI时代,极大的带宽需求迫使我们必须放弃无损和强排序,通过iWARP DDP这类技术实现弱排序和多路径转发,才能充分利用带宽。
当然,这件事本身很难,对于NVIDIA(Mellanox)在现有硬件架构上推倒重来更是尴尬,这也导致了他们持续坚持走无损路线。
5.3 多路径与拥塞控制
veRoCE仍受制于原有的一些硬件实现约束。和RoCE一样,它没有将拥塞控制与数据路径紧密集成。其拥塞控制是作为一个附加组件实现的,依赖于带外探测来收集拥塞信号,这种分离使其拥塞响应相对迟缓。
从ZTR-CC开始,NVIDIA就尝试用带外信号探测拥塞,但信号处理缓慢,效果不佳。近期的CX8通过PSA以及Spectrum-X将遥测处理能力提升了1000倍,但更频繁的带外周期性探测不仅与数据路径分离,还会消耗大量资源。
至于多路径算法,规范中并未公布太多细节,其实现仍涉及大量技巧,特别是在多路径与拥塞控制的融合方面。
5.4 结语
历史的选择往往很简单,但却常常被大量的市场营销和偏见所裹挟。很高兴看到veRoCE选择了一条正确的技术路径。
其实,实现这些目标最大的难点在于软硬件协同设计。许多协议设计者缺乏处理高性能有状态L4协议的经验和能力。有些号称专家的人,可能从未亲手设计过一颗芯片,自然无法周全考虑所有因素。同理,veRoCE也受限于其承载网卡的硬件提供商的约束,协议上仍存在一些不完善之处。
毕竟,与在业界深耕十多年、处理有状态L4服务路由的人相比,我们认为的芯片设计常识,对学术界或部分从业者而言可能难如登天。
总体而言,veRoCE还是一项非常不错的工作,在保持RC兼容的前提下实现有损传输和多路径,基本完成了RDMA现代化改造的核心部分。但前路依然漫长,正确的选择始终如下:
建议深入阅读以下几篇文章,它们对理解人工智能时代的高性能网络演进大有裨益:
《谈谈Google Falcon的可靠传输论文并对比分析CIPU eRDMA》
《RDMA这十年的反思1:从协议演进的视角》
《RDMA这十年的反思2:从应用和芯片架构的视角》
 发表于 2025-12-24 03:12:21
|
查看: 608|
回复: 0
发表于 2025-12-24 03:12:21
|
查看: 608|
回复: 0
