MIG(Multi-Instance GPU)是自NVIDIA Ampere架构开始支持的特性,旨在解决GPU在集群服务中的资源切分与虚拟化需求。本文将系统介绍MIG的核心概念与操作方法,并通过实际操作演示,帮助读者全面理解该技术。
阅读前,您可以通过以下问题快速定位相关内容:
- 为什么需要MIG?与传统的vGPU有何不同?(见章节一与章节二.1.3)
- MIG如何进行创建、删除与查看操作?(见章节三.1)
- MIG切分后,子实例间的算力竞争情况如何?(见章节三.3测试)
- MIG中的GI(GPU实例)与CI(计算实例)是什么关系?(见章节二.2)
- MIG子实例是一块完全独立的GPU吗?支持NVLINK吗?
一、技术背景
1.1 NVIDIA vGPU技术
vGPU是NVIDIA推出的、支持在虚拟机(VM)中使用的虚拟GPU软件解决方案。它能够将一块物理GPU划分为多个小型虚拟GPU,供不同用户或任务使用。
其核心原理涉及对物理硬件的两种虚拟化:存储虚拟化与运算虚拟化。
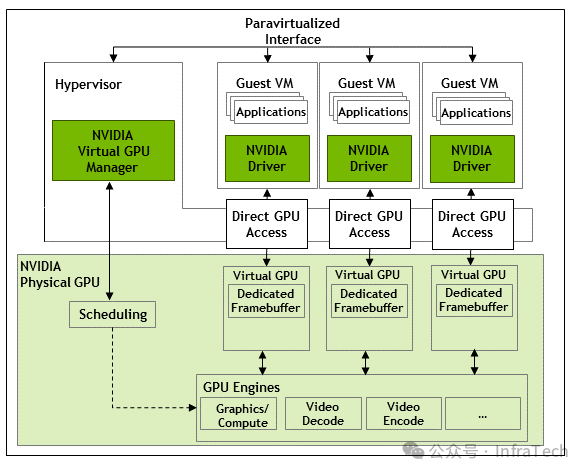
- 存储虚拟化:通过预先分配专用的帧缓冲区(dedicated framebuffer)来为每个虚拟GPU划定独立的显存空间。
- 运算虚拟化:通过调度器(scheduler)以时间片轮转(time-sliced)的方式,控制各虚拟任务对GPU物理计算引擎的使用时间。
这种基于时间片的vGPU模式,本质上是让所有任务共享物理硬件资源,通过分配不同的时间片比例来控制资源使用量。虽然能满足部分场景需求,但由于物理资源是共用的,任务需要排队等待,在算力、带宽保障以及任务切换开销方面难以实现完美的服务质量(QoS)。例如,当两个任务都需要使用视频解码单元(NVDEC)时,频繁的上下文切换会带来额外开销。同时,对于单个任务而言,也未必能充分利用整张GPU的所有资源,可能造成资源浪费。
1.2 国内GPU虚拟化实践
国内的GPU虚拟化方案(如阿里云cGPU、腾讯云qGPU等)大多参考了vGPU的设计思路。这些方案主要围绕数据安全、资源隔离和QoS保障三大核心问题进行设计,并有效提升了集群资源利用率。然而,由于无法修改底层硬件约束,在安全性与资源分配的平衡上始终存在局限。此外,软件层面的切分与隔离通常会伴随物理卡资源的浪费,且切分粒度越细,浪费往往越显著。
1.3 MIG的诞生
NVIDIA洞察到市场对小规格GPU资源的需求,从Ampere架构(2020年)开始,在硬件层面集成了MIG特性。该特性专为数据中心等场景设计,旨在提供更灵活、多样的GPU资源规格。MIG通过硬件级的资源划分与组合,帮助数据中心提升资源利用效率,同时降低用户的使用成本。
二、MIG技术架构解析
2.1 MIG的核心原理与架构
2.1.1 基本原理
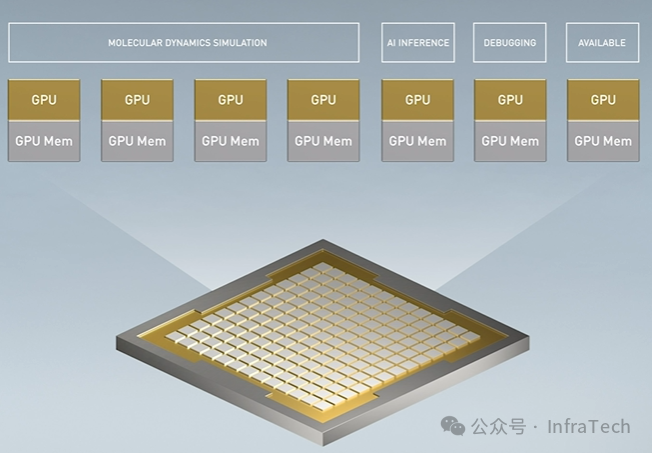
Ampere架构通过硬件设计,使GPU能够创建出在计算、显存带宽、故障隔离等方面都相对独立的子GPU实例(GI)。MIG的基本方法是分块+组合:首先对物理GPU上的可用资源(包括流式多处理器SM/TPC/GPC、拷贝引擎CE、编解码引擎DEC/ENC、全局显存、L2缓存等)进行划分;然后将这些分块后的资源重新组合,形成一个个具备数据保护、故障隔离独立、服务稳定特性的子GPU。
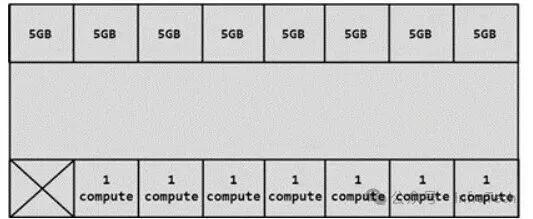
过程一:资源分块
下图展示了将一块A100 40GB GPU的算力均分为7份、显存分割为8份的示意图,为后续组合提供了均匀的资源单元。
过程二:资源组合
组合是指将分块后的算力单元与存储单元进行搭配。例如,可以将1个算力单位与特定大小的显存单位组合,形成一个1g.5gb的子GPU实例。具体的组合规格由预设的Profile决定。

完成分块与组合后,即可在物理GPU上建立一系列子GPU实例,以满足不同应用场景的需求。下图展示了将一张GPU划分为7个GI实例的示例。
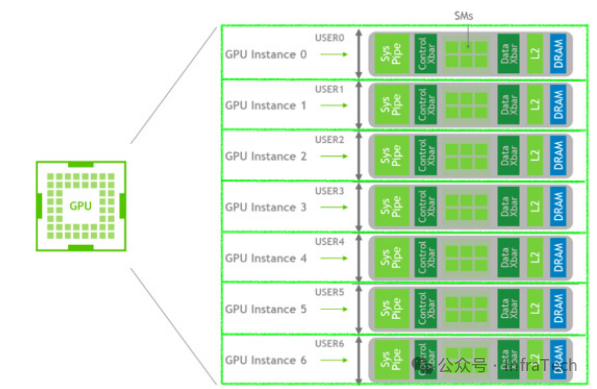
当然,资源也可以进行不等份切分,以适应更复杂的工作负载混合部署场景。
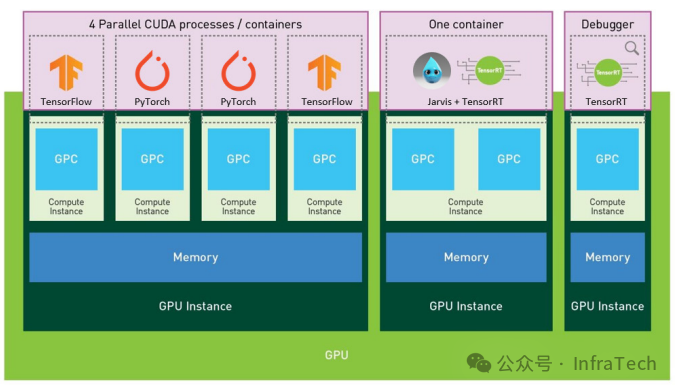
2.1.2 配置流程
MIG的配置流程较为灵活,支持对算力、显存及其他引擎进行“格式化”组合。创建MIG主要分为两大步骤:
- 创建GPU实例(GI):从物理GPU上选取已分块的资源单元,组合成一个子GPU。
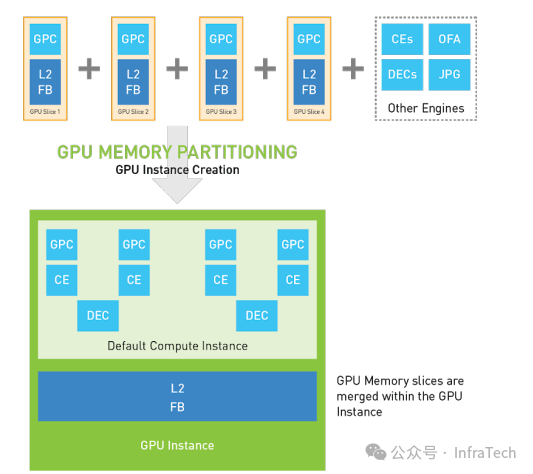
- 创建计算实例(CI):在GI的基础上,可以进一步对其计算单元进行划分。这样创建出的CI在算力上独立,但GI内的其他资源(如显存、特定引擎)是共享的。下图展示了一个GI被划分为两个CI,每个CI拥有2个GPC算力单元。
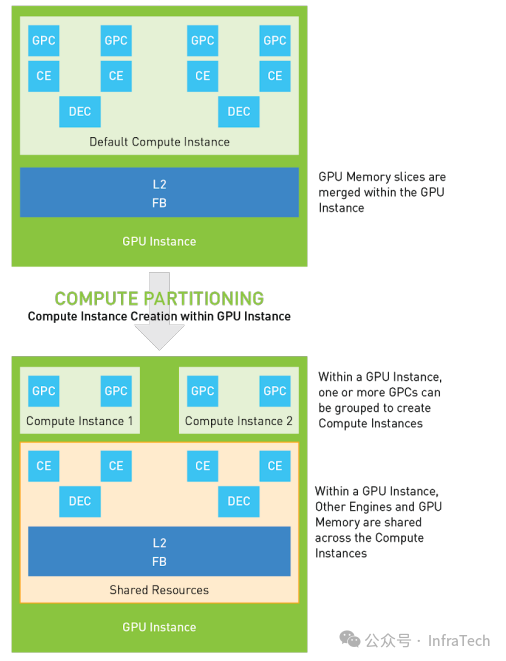
简而言之,MIG的资源创建经过了两次划分(先GI后CI),通过排列组合增加了配置的多样性,但这些组合必须遵循预定义的规则(Profile)。
2.1.3 MIG与vGPU的结合
MIG和vGPU的目标都是实现GPU虚拟化。两者可以结合使用,即在MIG划分出的硬件隔离子GPU之上,再运行基于时间片的vGPU软件层。下图对比了传统“时间分片vGPU”与“基于MIG的vGPU”在架构上的差异。
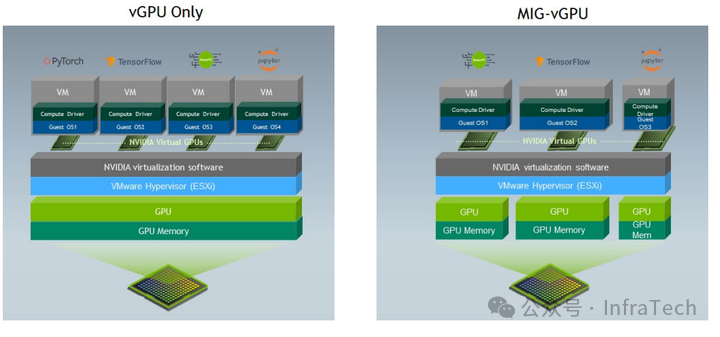
那么,既然有了vGPU,为何还需要MIG?通过一组基于Mask R-CNN训练网络的测试数据(来源见文末参考)对比,可以清晰地看到MIG-vGPU在性能上的优势:
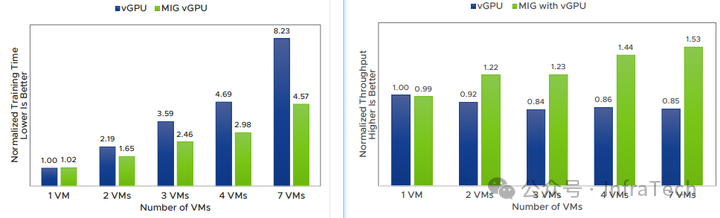
- 训练性能对比(时间-左,吞吐-右):
- 推理性能对比(时间-左,吞吐-右):
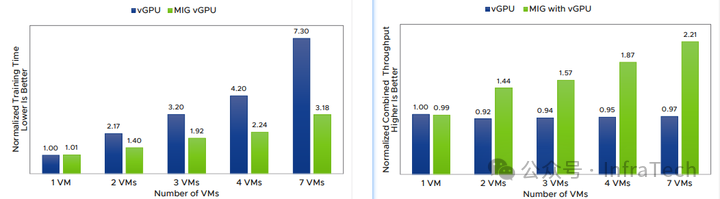
数据表明,MIG-vGPU在训练和推理任务上的表现均优于传统的Time-sliced vGPU。
2.1.4 MIG与MPS、Stream的对比
NVIDIA GPU支持多种并发机制:Stream(流)、MPS(多进程服务)和MIG。三者在并发数量、算力隔离性等方面存在显著差异。
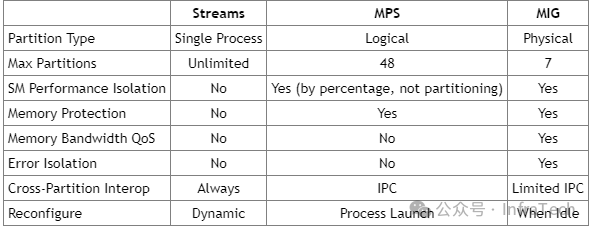
总体来看,MIG在配置灵活性(最多7个分片)上不及Stream和MPS,但在算力隔离、内存带宽隔离、错误隔离及QoS保障方面表现最佳。
2.2 核心概念解析
理解以下概念对操作MIG至关重要:
- 引擎与存储:
- SM/TPC/GPC:GPU的基本计算单元与计算块。
- CE:拷贝引擎,负责数据搬运。
- DEC/ENC:视频解码与编码引擎。
- OFA:光流加速器。
- Memory:主要指全局显存和L2缓存。
- 分片与实例:
- Slice:对引擎或存储资源进行划分后得到的基础单元模块。
- GPU Instance:子GPU实例,简称GI,可独立运行。
- Compute Instance:计算实例,简称CI,在GI内对算力进行的进一步划分。
- MIG命名规则:
- GI命名:格式如
3g.20gb,3g代表3个算力单位(A100共7个单位),20gb代表20GB显存。
- CI命名:格式如
1c.3g.20gb,1c代表占用1个算力单位(该GI总共有3g算力)。关键点:CI仅划分算力(GPC),GI内的其他资源(如显存、CE、DEC等)在CI间是共享的。
- Profile与Placement:
- Profile:GPU支持的切分类型/格式,必须按照固定的格式组合资源。
- Placement:子GPU的创建顺序和起始位置,需遵循特定规则。
下图列出了A100 GPU支持的部分MIG配置方式:
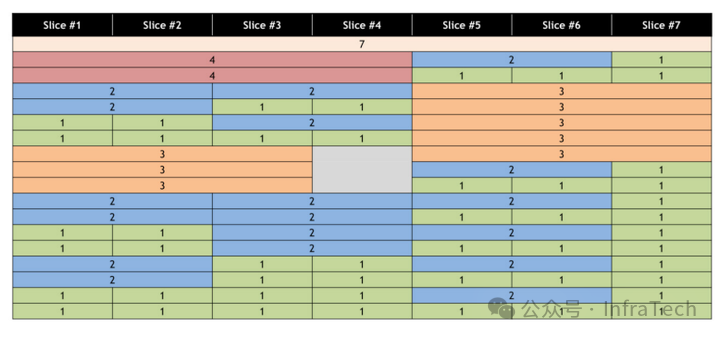
配置顺序可能导致算力浪费。例如,先创建了一个3g的GI后,剩余资源可能无法高效利用。
三、实战操作与性能测试
本节将基于Linux环境与NVIDIA A100显卡,演示MIG的配置、使用与性能测试方法。
测试环境关键硬件:Intel Xeon Platinum 8378A CPU @ 3.00GHz 128;显卡:NVIDIA A100-SXM4-80GB 8。
3.1 MIG基础操作
MIG的Shell操作主要涉及查看、创建和删除命令,通常需要root权限。基本操作命令概览如下:
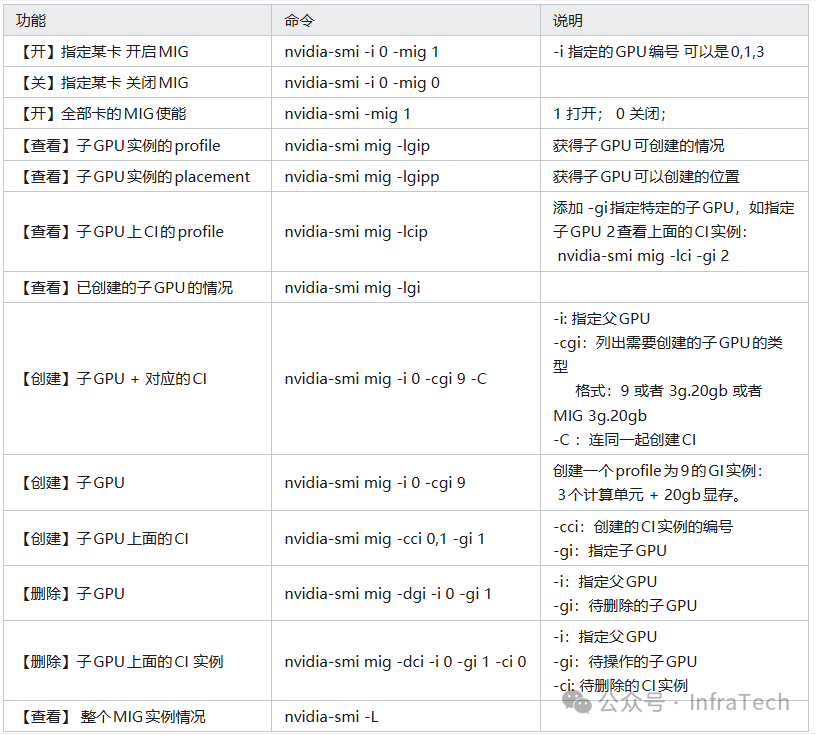
MIG的标准工作流程为:
启用MIG -> 创建GI实例 -> 创建CI实例 -> (使用) -> 删除CI实例 -> 删除GI实例 -> 禁用MIG。
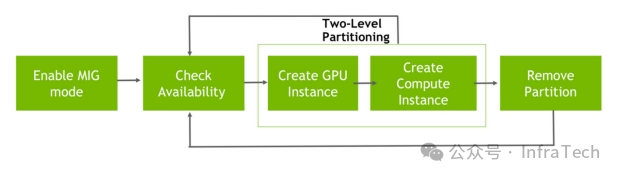
注意:
- GI的创建/删除可伴随CI的创建/删除。
- 创建CI必须在已存在的GI基础上进行。
- 关系为:物理GPU包含多个GI,一个GI可包含多个CI。
- 仅创建GI而不创建CI,子GPU无法运行。
3.1.1 启用MIG模式
默认情况下MIG功能为关闭状态。
# 查看指定GPU(例如GPU 7)状态
nvidia-smi -i 7
# 启用该GPU的MIG模式
nvidia-smi -i 7 -mig 1
# 再次查看,确认MIG Mode变为Enabled
nvidia-smi -i 7
# 禁用MIG模式
nvidia-smi -i 7 -mig 0
若启用时遇到“pending”错误,可能原因包括:GPU被进程占用、Docker容器挂载、或相关服务(如nvsm, dcgm)正在运行。可尝试停止相关进程或容器,使用nvidia-smi --gpu-reset命令,或重启系统。
3.1.2 创建GI实例
启用MIG后,查看可创建的GI规格(Profile):
nvidia-smi mig -i 7 -lgip
输出会显示Profile ID、名称及剩余可创建数量(FREE/TOTAL)。创建操作会耦合地影响其他Profile的可用数量。
创建MIG 3g.40gb实例:
# 创建GI(假设Profile ID 9对应3g.40gb)
nvidia-smi mig -i 7 -cgi 9
# 查看已创建的GI
nvidia-smi mig -i 7 -lgi
此时若运行nvidia-smi -i 7,会显示No MIG devices found,因为还未创建CI。
3.1.3 创建CI实例
CI的创建依赖于GI。首先查看指定GI上可创建的CI Profile:
nvidia-smi mig -i 7 -lcip
假设GI ID为1,输出可能显示支持MIG 1c.3g.40gb、MIG 2c.3g.40gb、MIG 3g.40gb三种CI类型。
创建两个CI,用完该GI的3份算力:
# 在GI 1上创建CI (ID 0 和 1)
nvidia-smi mig -i 7 -cci 0,1 -gi 1
# 再次查看GPU信息,此时应能看到MIG设备
nvidia-smi -i 7
现在可以看到两个子设备(Device 0, Device 1)及其唯一的UUID。
3.1.4 一键创建GI与CI
通过-C参数可在创建GI时自动创建其默认的CI。
nvidia-smi mig -i 7 -cgi 5 -C
3.1.5 删除操作
删除操作较为灵活,可单独删除CI或GI,也可级联删除。
# 删除指定GPU上的所有CI(需先确保无任务运行)
nvidia-smi mig -i 7 -dci
# 删除指定GPU上的所有GI
nvidia-smi mig -i 7 -dgi
# 删除指定GI上的特定CI
nvidia-smi mig -i 7 -dci -ci 1 -gi 2
3.2 MIG设备的使用
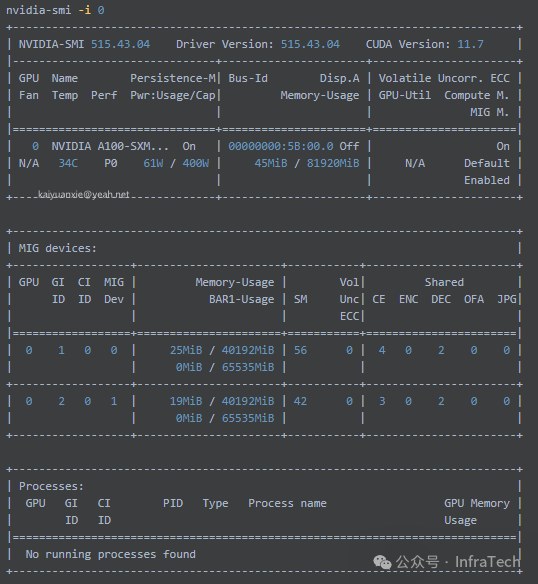
创建完成后,可通过nvidia-smi -L查看所有GPU及MIG设备。
3.2.1 在宿主机上使用
直接通过设置环境变量指定MIG设备的UUID即可。
export CUDA_VISIBLE_DEVICES=MIG-XXXXXXXX-XXXX-XXXX-aaed-1060f461744a
python train.py
3.2.2 在Docker容器中使用
需要nvidia-docker2 (>= v2.3) 支持。启动容器时挂载特定的MIG设备。
# 例如,挂载GPU 0上的第1号MIG设备
docker run --gpus '"device=0:1"' ...
这正是云原生技术栈中GPU资源管理的常见实践。
3.2.3 使用DCGM监控MIG性能指标
MIG设备运行时,nvidia-smi无法显示其Utilization,整卡Util会显示为N/A。需使用NVIDIA Data Center GPU Manager (DCGM)进行监控。
- 确认MIG设备与DCGM状态:确保已创建MIG设备并安装DCGM。
- 创建DCGM监控组:将需要监控的MIG设备加入一个Group。
dcgmi group -c mig-metric -a 0,i:0,i:1
dcgmi group -l
- 监控指标:使用
dmon命令打印指定指标,如SM利用率、显存利用率等。
dcgmi dmon -e 1001,1002,1003,1004,1005 -g 2
指标ID对应的含义可通过dcgmi profile -l -i 0查询。DCGM会分别输出整卡以及各个MIG实例的监控数据。
3.3 MIG性能隔离测试
我们通过两个测试验证MIG在算力分配与QoS隔离方面的效果。
测试环境:
- Case 1: 使用假数据与
torchvision.models.resnext101_32x8d模型,模拟多任务抢占。
- Case 2/3: 使用ImageNet数据与
swin-transformer模型。
3.3.1 均等算力抢占测试
测试在MIG 4g.40gb(理论算力约为整卡的57%)与整卡上运行相同训练任务,并观察随着并发任务数增加,单个任务耗时与平均耗时的变化。
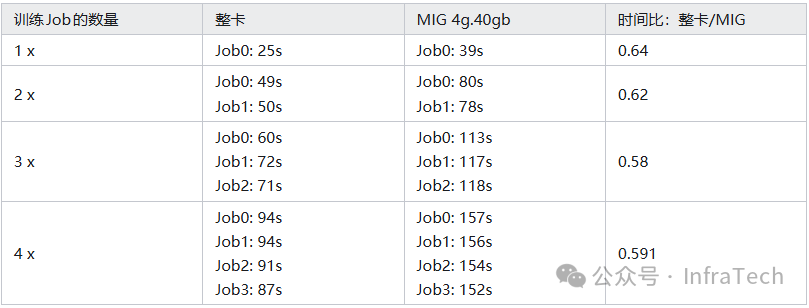
测试结果表明,在多任务并发场景下,任务耗时的增加比例与算力切分的比例高度吻合,证明了MIG在算力隔离上的有效性。
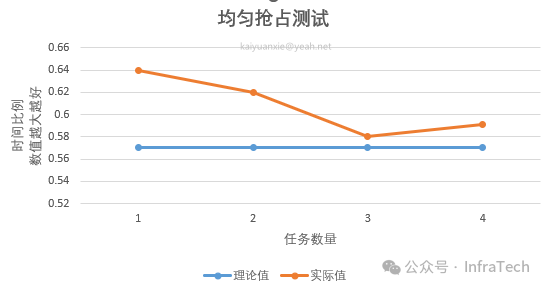
3.3.2 不同算力配置测试
使用swin-transformer在ImageNet-mini数据集上训练,通过改变GI的算力大小(1g/2g/3g/4g,显存均为40GB),观察训练时间的变化。
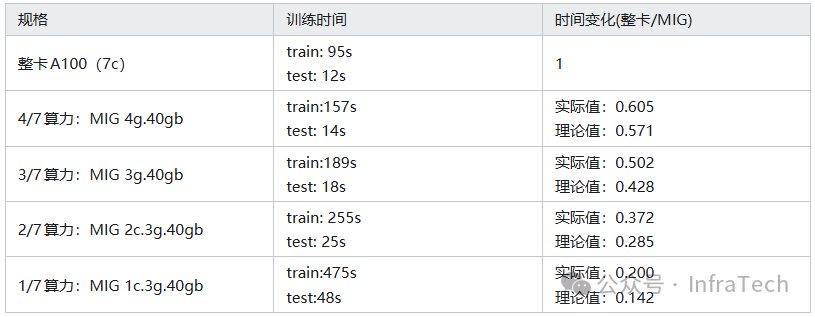
结果显示,训练时间随算力减少而增加,其变化趋势与算力缩减比例基本一致。实际值略优于理论值,可能是因为训练负载未完全压满计算单元。
3.3.3 非均等切分与QoS测试
此测试旨在回答:在同一张A100上按不等比例(如3:4)切分算力并运行相同任务,任务间会相互影响吗?
在同一GPU上创建两个GI,算力分别为3g和4g,并同时启动两个相同的swin-transformer训练任务。
记录它们的端到端执行时间,并与它们各自单独运行的时间进行对比。

测试数据清晰表明,在非均等切分场景下,MIG仍能提供优秀的QoS保障。混合训练时每个任务的执行时间与它们单独运行时基本一致,任务间没有产生明显的性能干扰。
四、总结
MIG作为一种硬件级GPU虚拟化技术,在资源隔离、安全性和QoS保障方面表现卓越。相较于传统的Time-sliced软件虚拟化方案,其在带宽保障、计算效率损失和故障处理方面具备显著优势。
当然,MIG并非完美:例如,它目前不支持子实例间的P2P通信(如NVLINK);当切分子实例数量较多时,部分专用引擎(如OFA、NVJPEG)可能不可用;且配置粒度相对固定(最多7分)。然而,作为云原生与AI基础设施的重要发展方向,MIG技术无疑为数据中心提供了更灵活、高效和可靠的GPU资源供给方案,能更好地满足多元化AI工作负载(例如使用PyTorch等框架的训练与推理任务)的需求。
参考资料
 发表于 2025-12-25 07:03:21
|
查看: 385|
回复: 0
发表于 2025-12-25 07:03:21
|
查看: 385|
回复: 0
